
A Coding Guide to High-Quality Image Generation, Control, and Editing Using HuggingFace DiffusersMarkTechPost In this tutorial, we design a practical image-generation workflow using the Diffusers library. We start by stabilizing the environment, then generate high-quality images from text prompts using Stable Diffusion with an optimized scheduler. We accelerate inference with a LoRA-based latent consistency approach, guide composition with ControlNet under edge conditioning, and finally perform localized edits via
The post A Coding Guide to High-Quality Image Generation, Control, and Editing Using HuggingFace Diffusers appeared first on MarkTechPost.
In this tutorial, we design a practical image-generation workflow using the Diffusers library. We start by stabilizing the environment, then generate high-quality images from text prompts using Stable Diffusion with an optimized scheduler. We accelerate inference with a LoRA-based latent consistency approach, guide composition with ControlNet under edge conditioning, and finally perform localized edits via
The post A Coding Guide to High-Quality Image Generation, Control, and Editing Using HuggingFace Diffusers appeared first on MarkTechPost. Read More

7 XGBoost Tricks for More Accurate Predictive ModelsKDnuggets 7 Python tricks that may help make the most of the standalone XGBoost library, particularly in terms of seeking more accurate predictive models.
7 Python tricks that may help make the most of the standalone XGBoost library, particularly in terms of seeking more accurate predictive models. Read More
An End-to-End Guide to Beautifying Your Open-Source Repo with Agentic AITowards Data Science The guide to automated improvement of scientific and industrial repositories using open-source AI agents
The post An End-to-End Guide to Beautifying Your Open-Source Repo with Agentic AI appeared first on Towards Data Science.
The guide to automated improvement of scientific and industrial repositories using open-source AI agents
The post An End-to-End Guide to Beautifying Your Open-Source Repo with Agentic AI appeared first on Towards Data Science. Read More

All About Google Colab File ManagementKDnuggets This is the ultimate guide to uploading, downloading, and saving files in Colab.
This is the ultimate guide to uploading, downloading, and saving files in Colab. Read More
Quantum computer breakthrough tracks qubit fluctuations in real timeArtificial Intelligence News — ScienceDaily Qubits, the heart of quantum computers, can change performance in fractions of a second — but until now, scientists couldn’t see it happening. Researchers at NBI have built a real-time monitoring system that tracks these rapid fluctuations about 100 times faster than previous methods. Using fast FPGA-based control hardware, they can instantly identify when a qubit shifts from “good” to “bad.” The discovery opens a new path toward stabilizing and scaling future quantum processors.
Qubits, the heart of quantum computers, can change performance in fractions of a second — but until now, scientists couldn’t see it happening. Researchers at NBI have built a real-time monitoring system that tracks these rapid fluctuations about 100 times faster than previous methods. Using fast FPGA-based control hardware, they can instantly identify when a qubit shifts from “good” to “bad.” The discovery opens a new path toward stabilizing and scaling future quantum processors. Read More

Exploring AI in the APAC retail sectorAI News AI in the APAC retail sector is transitioning from analytics and pilots into workflows and daily operations. Dense urban stores, high labour churn, and competitive quick-commerce ecosystems are driving the uptake. A Q4 2025 survey by GlobalData found that 45 percent of consumers in Asia and Australasia are very or quite likely to purchase a
The post Exploring AI in the APAC retail sector appeared first on AI News.
AI in the APAC retail sector is transitioning from analytics and pilots into workflows and daily operations. Dense urban stores, high labour churn, and competitive quick-commerce ecosystems are driving the uptake. A Q4 2025 survey by GlobalData found that 45 percent of consumers in Asia and Australasia are very or quite likely to purchase a
The post Exploring AI in the APAC retail sector appeared first on AI News. Read More
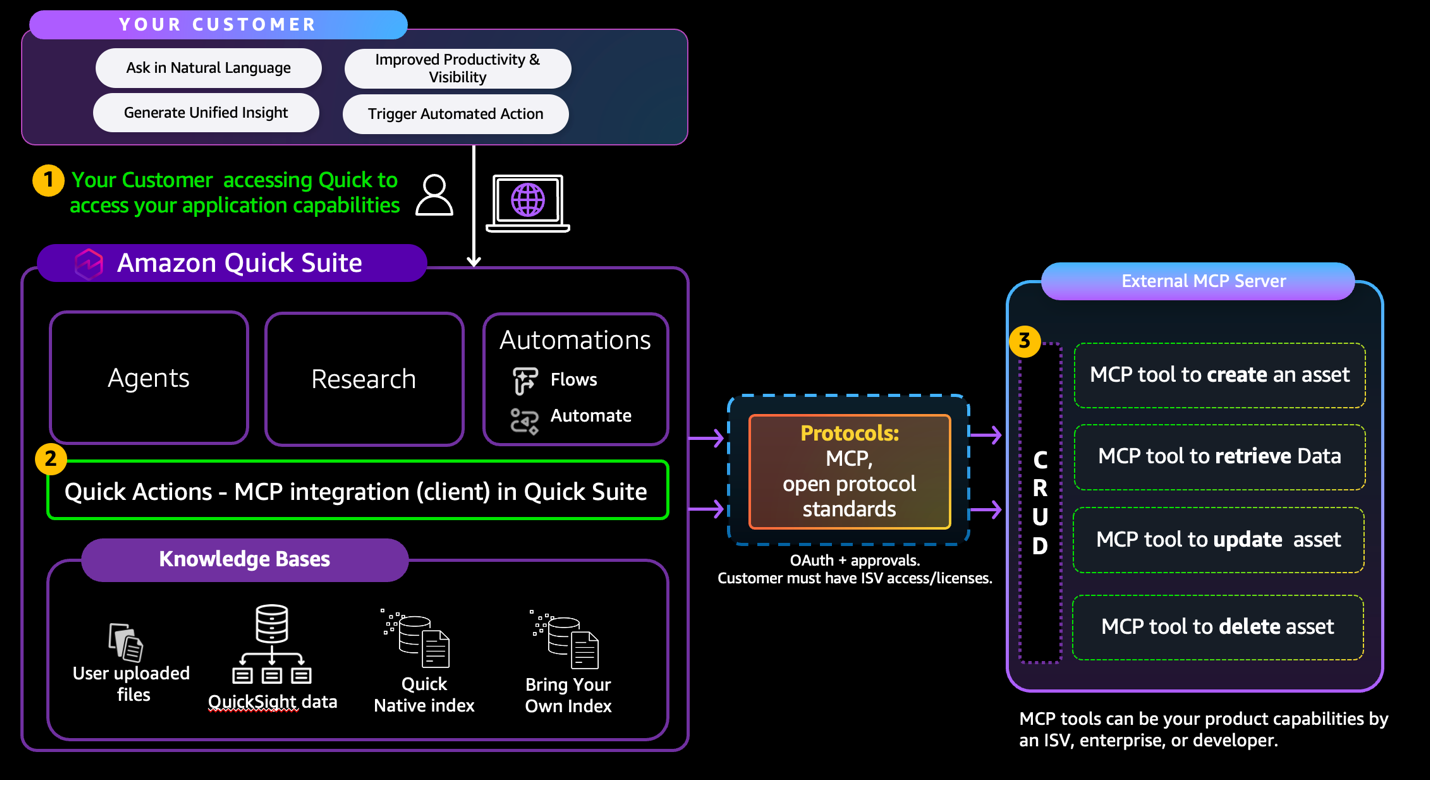
Integrate external tools with Amazon Quick Agents using Model Context Protocol (MCP)Artificial Intelligence In this post, you’ll use a six-step checklist to build a new MCP server or validate and adjust an existing MCP server for Amazon Quick integration. The Amazon Quick User Guide describes the MCP client behavior and constraints. This is a “How to” guide for detailed implementation required by 3P partners to integrate with Amazon Quick with MCP.
In this post, you’ll use a six-step checklist to build a new MCP server or validate and adjust an existing MCP server for Amazon Quick integration. The Amazon Quick User Guide describes the MCP client behavior and constraints. This is a “How to” guide for detailed implementation required by 3P partners to integrate with Amazon Quick with MCP. Read More
Simple Baselines are Competitive with Code Evolutioncs.AI updates on arXiv.org arXiv:2602.16805v1 Announce Type: new
Abstract: Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem’s search space and domain knowledge in the prompt are chiefly what dictate a search’s performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. When designing agentic scaffolds we find that high variance in the scaffolds coupled with small datasets leads to suboptimal scaffolds being selected, resulting in hand-designed majority vote scaffolds performing best. We propose better evaluation methods that reduce evaluation stochasticity while keeping the code evolution economically feasible. We finish with a discussion of avenues and best practices to enable more rigorous code evolution in future work.
arXiv:2602.16805v1 Announce Type: new
Abstract: Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem’s search space and domain knowledge in the prompt are chiefly what dictate a search’s performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. When designing agentic scaffolds we find that high variance in the scaffolds coupled with small datasets leads to suboptimal scaffolds being selected, resulting in hand-designed majority vote scaffolds performing best. We propose better evaluation methods that reduce evaluation stochasticity while keeping the code evolution economically feasible. We finish with a discussion of avenues and best practices to enable more rigorous code evolution in future work. Read More
NeuDiff Agent: A Governed AI Workflow for Single-Crystal Neutron Crystallographycs.AI updates on arXiv.org arXiv:2602.16812v1 Announce Type: new
Abstract: Large-scale facilities increasingly face analysis and reporting latency as the limiting step in scientific throughput, particularly for structurally and magnetically complex samples that require iterative reduction, integration, refinement, and validation. To improve time-to-result and analysis efficiency, NeuDiff Agent is introduced as a governed, tool-using AI workflow for TOPAZ at the Spallation Neutron Source that takes instrument data products through reduction, integration, refinement, and validation to a validated crystal structure and a publication-ready CIF. NeuDiff Agent executes this established pipeline under explicit governance by restricting actions to allowlisted tools, enforcing fail-closed verification gates at key workflow boundaries, and capturing complete provenance for inspection, auditing, and controlled replay. Performance is assessed using a fixed prompt protocol and repeated end-to-end runs with two large language model backends, with user and machine time partitioned and intervention burden and recovery behaviors quantified under gating. In a reference-case benchmark, NeuDiff Agent reduces wall time from 435 minutes (manual) to 86.5(4.7) to 94.4(3.5) minutes (4.6-5.0x faster) while producing a validated CIF with no checkCIF level A or B alerts. These results establish a practical route to deploy agentic AI in facility crystallography while preserving traceability and publication-facing validation requirements.
arXiv:2602.16812v1 Announce Type: new
Abstract: Large-scale facilities increasingly face analysis and reporting latency as the limiting step in scientific throughput, particularly for structurally and magnetically complex samples that require iterative reduction, integration, refinement, and validation. To improve time-to-result and analysis efficiency, NeuDiff Agent is introduced as a governed, tool-using AI workflow for TOPAZ at the Spallation Neutron Source that takes instrument data products through reduction, integration, refinement, and validation to a validated crystal structure and a publication-ready CIF. NeuDiff Agent executes this established pipeline under explicit governance by restricting actions to allowlisted tools, enforcing fail-closed verification gates at key workflow boundaries, and capturing complete provenance for inspection, auditing, and controlled replay. Performance is assessed using a fixed prompt protocol and repeated end-to-end runs with two large language model backends, with user and machine time partitioned and intervention burden and recovery behaviors quantified under gating. In a reference-case benchmark, NeuDiff Agent reduces wall time from 435 minutes (manual) to 86.5(4.7) to 94.4(3.5) minutes (4.6-5.0x faster) while producing a validated CIF with no checkCIF level A or B alerts. These results establish a practical route to deploy agentic AI in facility crystallography while preserving traceability and publication-facing validation requirements. Read More
Node Learning: A Framework for Adaptive, Decentralised and Collaborative Network Edge AIcs.AI updates on arXiv.org arXiv:2602.16814v1 Announce Type: new
Abstract: The expansion of AI toward the edge increasingly exposes the cost and fragility of cen- tralised intelligence. Data transmission, latency, energy consumption, and dependence on large data centres create bottlenecks that scale poorly across heterogeneous, mobile, and resource-constrained environments. In this paper, we introduce Node Learning, a decen- tralised learning paradigm in which intelligence resides at individual edge nodes and expands through selective peer interaction. Nodes learn continuously from local data, maintain their own model state, and exchange learned knowledge opportunistically when collaboration is beneficial. Learning propagates through overlap and diffusion rather than global synchro- nisation or central aggregation. It unifies autonomous and cooperative behaviour within a single abstraction and accommodates heterogeneity in data, hardware, objectives, and connectivity. This concept paper develops the conceptual foundations of this paradigm, contrasts it with existing decentralised approaches, and examines implications for communi- cation, hardware, trust, and governance. Node Learning does not discard existing paradigms, but places them within a broader decentralised perspective
arXiv:2602.16814v1 Announce Type: new
Abstract: The expansion of AI toward the edge increasingly exposes the cost and fragility of cen- tralised intelligence. Data transmission, latency, energy consumption, and dependence on large data centres create bottlenecks that scale poorly across heterogeneous, mobile, and resource-constrained environments. In this paper, we introduce Node Learning, a decen- tralised learning paradigm in which intelligence resides at individual edge nodes and expands through selective peer interaction. Nodes learn continuously from local data, maintain their own model state, and exchange learned knowledge opportunistically when collaboration is beneficial. Learning propagates through overlap and diffusion rather than global synchro- nisation or central aggregation. It unifies autonomous and cooperative behaviour within a single abstraction and accommodates heterogeneity in data, hardware, objectives, and connectivity. This concept paper develops the conceptual foundations of this paradigm, contrasts it with existing decentralised approaches, and examines implications for communi- cation, hardware, trust, and governance. Node Learning does not discard existing paradigms, but places them within a broader decentralised perspective Read More