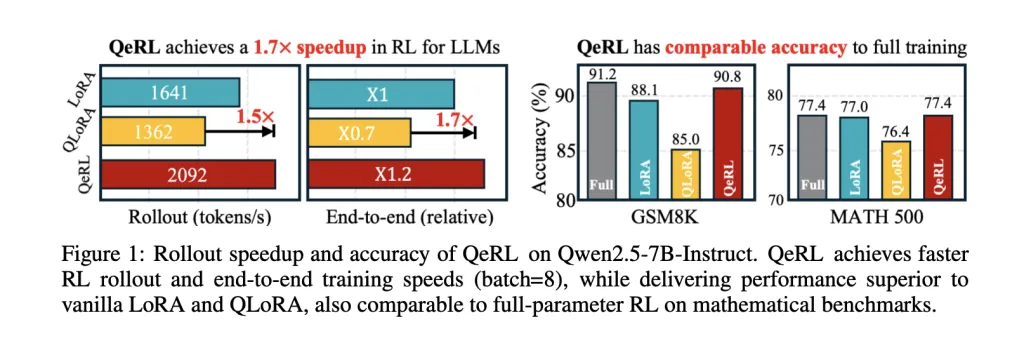
QeRL: NVFP4-Quantized Reinforcement Learning (RL) Brings 32B LLM Training to a Single H100—While Improving ExplorationMarkTechPost What would you build if you could run Reinforcement Learning (RL) post-training on a 32B LLM in 4-bit NVFP4—on a single H100—with BF16-level accuracy and 1.2–1.5× step speedups? NVIDIA researchers (with collaborators from MIT, HKU, and Tsinghua) have open-sourced QeRL (Quantization-enhanced Reinforcement Learning), a training framework that pushes Reinforcement Learning (RL) post-training into 4-bit FP4
The post QeRL: NVFP4-Quantized Reinforcement Learning (RL) Brings 32B LLM Training to a Single H100—While Improving Exploration appeared first on MarkTechPost.
What would you build if you could run Reinforcement Learning (RL) post-training on a 32B LLM in 4-bit NVFP4—on a single H100—with BF16-level accuracy and 1.2–1.5× step speedups? NVIDIA researchers (with collaborators from MIT, HKU, and Tsinghua) have open-sourced QeRL (Quantization-enhanced Reinforcement Learning), a training framework that pushes Reinforcement Learning (RL) post-training into 4-bit FP4
The post QeRL: NVFP4-Quantized Reinforcement Learning (RL) Brings 32B LLM Training to a Single H100—While Improving Exploration appeared first on MarkTechPost. Read More

MADREC: A Multi-Aspect Driven LLM Agent for Explainable and Adaptive Recommendationcs.AI updates on arXiv.org arXiv:2510.13371v1 Announce Type: cross
Abstract: Recent attempts to integrate large language models (LLMs) into recommender systems have gained momentum, but most remain limited to simple text generation or static prompt-based inference, failing to capture the complexity of user preferences and real-world interactions. This study proposes the Multi-Aspect Driven LLM Agent MADRec, an autonomous LLM-based recommender that constructs user and item profiles by unsupervised extraction of multi-aspect information from reviews and performs direct recommendation, sequential recommendation, and explanation generation. MADRec generates structured profiles via aspect-category-based summarization and applies Re-Ranking to construct high-density inputs. When the ground-truth item is missing from the output, the Self-Feedback mechanism dynamically adjusts the inference criteria. Experiments across multiple domains show that MADRec outperforms traditional and LLM-based baselines in both precision and explainability, with human evaluation further confirming the persuasiveness of the generated explanations.
arXiv:2510.13371v1 Announce Type: cross
Abstract: Recent attempts to integrate large language models (LLMs) into recommender systems have gained momentum, but most remain limited to simple text generation or static prompt-based inference, failing to capture the complexity of user preferences and real-world interactions. This study proposes the Multi-Aspect Driven LLM Agent MADRec, an autonomous LLM-based recommender that constructs user and item profiles by unsupervised extraction of multi-aspect information from reviews and performs direct recommendation, sequential recommendation, and explanation generation. MADRec generates structured profiles via aspect-category-based summarization and applies Re-Ranking to construct high-density inputs. When the ground-truth item is missing from the output, the Self-Feedback mechanism dynamically adjusts the inference criteria. Experiments across multiple domains show that MADRec outperforms traditional and LLM-based baselines in both precision and explainability, with human evaluation further confirming the persuasiveness of the generated explanations. Read More
AOAD-MAT: Transformer-based multi-agent deep reinforcement learning model considering agents’ order of action decisionscs.AI updates on arXiv.org arXiv:2510.13343v1 Announce Type: cross
Abstract: Multi-agent reinforcement learning focuses on training the behaviors of multiple learning agents that coexist in a shared environment. Recently, MARL models, such as the Multi-Agent Transformer (MAT) and ACtion dEpendent deep Q-learning (ACE), have significantly improved performance by leveraging sequential decision-making processes. Although these models can enhance performance, they do not explicitly consider the importance of the order in which agents make decisions. In this paper, we propose an Agent Order of Action Decisions-MAT (AOAD-MAT), a novel MAT model that considers the order in which agents make decisions. The proposed model explicitly incorporates the sequence of action decisions into the learning process, allowing the model to learn and predict the optimal order of agent actions. The AOAD-MAT model leverages a Transformer-based actor-critic architecture that dynamically adjusts the sequence of agent actions. To achieve this, we introduce a novel MARL architecture that cooperates with a subtask focused on predicting the next agent to act, integrated into a Proximal Policy Optimization based loss function to synergistically maximize the advantage of the sequential decision-making. The proposed method was validated through extensive experiments on the StarCraft Multi-Agent Challenge and Multi-Agent MuJoCo benchmarks. The experimental results show that the proposed AOAD-MAT model outperforms existing MAT and other baseline models, demonstrating the effectiveness of adjusting the AOAD order in MARL.
arXiv:2510.13343v1 Announce Type: cross
Abstract: Multi-agent reinforcement learning focuses on training the behaviors of multiple learning agents that coexist in a shared environment. Recently, MARL models, such as the Multi-Agent Transformer (MAT) and ACtion dEpendent deep Q-learning (ACE), have significantly improved performance by leveraging sequential decision-making processes. Although these models can enhance performance, they do not explicitly consider the importance of the order in which agents make decisions. In this paper, we propose an Agent Order of Action Decisions-MAT (AOAD-MAT), a novel MAT model that considers the order in which agents make decisions. The proposed model explicitly incorporates the sequence of action decisions into the learning process, allowing the model to learn and predict the optimal order of agent actions. The AOAD-MAT model leverages a Transformer-based actor-critic architecture that dynamically adjusts the sequence of agent actions. To achieve this, we introduce a novel MARL architecture that cooperates with a subtask focused on predicting the next agent to act, integrated into a Proximal Policy Optimization based loss function to synergistically maximize the advantage of the sequential decision-making. The proposed method was validated through extensive experiments on the StarCraft Multi-Agent Challenge and Multi-Agent MuJoCo benchmarks. The experimental results show that the proposed AOAD-MAT model outperforms existing MAT and other baseline models, demonstrating the effectiveness of adjusting the AOAD order in MARL. Read More
SENTINEL: A Multi-Level Formal Framework for Safety Evaluation of LLM-based Embodied Agentscs.AI updates on arXiv.org arXiv:2510.12985v1 Announce Type: new
Abstract: We present Sentinel, the first framework for formally evaluating the physical safety of Large Language Model(LLM-based) embodied agents across the semantic, plan, and trajectory levels. Unlike prior methods that rely on heuristic rules or subjective LLM judgments, Sentinel grounds practical safety requirements in formal temporal logic (TL) semantics that can precisely specify state invariants, temporal dependencies, and timing constraints. It then employs a multi-level verification pipeline where (i) at the semantic level, intuitive natural language safety requirements are formalized into TL formulas and the LLM agent’s understanding of these requirements is probed for alignment with the TL formulas; (ii) at the plan level, high-level action plans and subgoals generated by the LLM agent are verified against the TL formulas to detect unsafe plans before execution; and (iii) at the trajectory level, multiple execution trajectories are merged into a computation tree and efficiently verified against physically-detailed TL specifications for a final safety check. We apply Sentinel in VirtualHome and ALFRED, and formally evaluate multiple LLM-based embodied agents against diverse safety requirements. Our experiments show that by grounding physical safety in temporal logic and applying verification methods across multiple levels, Sentinel provides a rigorous foundation for systematically evaluating LLM-based embodied agents in physical environments, exposing safety violations overlooked by previous methods and offering insights into their failure modes.
arXiv:2510.12985v1 Announce Type: new
Abstract: We present Sentinel, the first framework for formally evaluating the physical safety of Large Language Model(LLM-based) embodied agents across the semantic, plan, and trajectory levels. Unlike prior methods that rely on heuristic rules or subjective LLM judgments, Sentinel grounds practical safety requirements in formal temporal logic (TL) semantics that can precisely specify state invariants, temporal dependencies, and timing constraints. It then employs a multi-level verification pipeline where (i) at the semantic level, intuitive natural language safety requirements are formalized into TL formulas and the LLM agent’s understanding of these requirements is probed for alignment with the TL formulas; (ii) at the plan level, high-level action plans and subgoals generated by the LLM agent are verified against the TL formulas to detect unsafe plans before execution; and (iii) at the trajectory level, multiple execution trajectories are merged into a computation tree and efficiently verified against physically-detailed TL specifications for a final safety check. We apply Sentinel in VirtualHome and ALFRED, and formally evaluate multiple LLM-based embodied agents against diverse safety requirements. Our experiments show that by grounding physical safety in temporal logic and applying verification methods across multiple levels, Sentinel provides a rigorous foundation for systematically evaluating LLM-based embodied agents in physical environments, exposing safety violations overlooked by previous methods and offering insights into their failure modes. Read More
Behavioral Embeddings of Programs: A Quasi-Dynamic Approach for Optimization Predictioncs.AI updates on arXiv.org arXiv:2510.13158v1 Announce Type: cross
Abstract: Learning effective numerical representations, or embeddings, of programs is a fundamental prerequisite for applying machine learning to automate and enhance compiler optimization. Prevailing paradigms, however, present a dilemma. Static representations, derived from source code or intermediate representation (IR), are efficient and deterministic but offer limited insight into how a program will behave or evolve under complex code transformations. Conversely, dynamic representations, which rely on runtime profiling, provide profound insights into performance bottlenecks but are often impractical for large-scale tasks due to prohibitive overhead and inherent non-determinism. This paper transcends this trade-off by proposing a novel quasi-dynamic framework for program representation. The core insight is to model a program’s optimization sensitivity. We introduce the Program Behavior Spectrum, a new representation generated by probing a program’s IR with a diverse set of optimization sequences and quantifying the resulting changes in its static features. To effectively encode this high-dimensional, continuous spectrum, we pioneer a compositional learning approach. Product Quantization is employed to discretize the continuous reaction vectors into structured, compositional sub-words. Subsequently, a multi-task Transformer model, termed PQ-BERT, is pre-trained to learn the deep contextual grammar of these behavioral codes. Comprehensive experiments on two representative compiler optimization tasks — Best Pass Prediction and -Oz Benefit Prediction — demonstrate that our method outperforms state-of-the-art static baselines. Our code is publicly available at https://github.com/Panhaolin2001/PREP/.
arXiv:2510.13158v1 Announce Type: cross
Abstract: Learning effective numerical representations, or embeddings, of programs is a fundamental prerequisite for applying machine learning to automate and enhance compiler optimization. Prevailing paradigms, however, present a dilemma. Static representations, derived from source code or intermediate representation (IR), are efficient and deterministic but offer limited insight into how a program will behave or evolve under complex code transformations. Conversely, dynamic representations, which rely on runtime profiling, provide profound insights into performance bottlenecks but are often impractical for large-scale tasks due to prohibitive overhead and inherent non-determinism. This paper transcends this trade-off by proposing a novel quasi-dynamic framework for program representation. The core insight is to model a program’s optimization sensitivity. We introduce the Program Behavior Spectrum, a new representation generated by probing a program’s IR with a diverse set of optimization sequences and quantifying the resulting changes in its static features. To effectively encode this high-dimensional, continuous spectrum, we pioneer a compositional learning approach. Product Quantization is employed to discretize the continuous reaction vectors into structured, compositional sub-words. Subsequently, a multi-task Transformer model, termed PQ-BERT, is pre-trained to learn the deep contextual grammar of these behavioral codes. Comprehensive experiments on two representative compiler optimization tasks — Best Pass Prediction and -Oz Benefit Prediction — demonstrate that our method outperforms state-of-the-art static baselines. Our code is publicly available at https://github.com/Panhaolin2001/PREP/. Read More
Toward Reasoning-Centric Time-Series Analysiscs.AI updates on arXiv.org arXiv:2510.13029v1 Announce Type: new
Abstract: Traditional time series analysis has long relied on pattern recognition, trained on static and well-established benchmarks. However, in real-world settings — where policies shift, human behavior adapts, and unexpected events unfold — effective analysis must go beyond surface-level trends to uncover the actual forces driving them. The recent rise of Large Language Models (LLMs) presents new opportunities for rethinking time series analysis by integrating multimodal inputs. However, as the use of LLMs becomes popular, we must remain cautious, asking why we use LLMs and how to exploit them effectively. Most existing LLM-based methods still employ their numerical regression ability and ignore their deeper reasoning potential. This paper argues for rethinking time series with LLMs as a reasoning task that prioritizes causal structure and explainability. This shift brings time series analysis closer to human-aligned understanding, enabling transparent and context-aware insights in complex real-world environments.
arXiv:2510.13029v1 Announce Type: new
Abstract: Traditional time series analysis has long relied on pattern recognition, trained on static and well-established benchmarks. However, in real-world settings — where policies shift, human behavior adapts, and unexpected events unfold — effective analysis must go beyond surface-level trends to uncover the actual forces driving them. The recent rise of Large Language Models (LLMs) presents new opportunities for rethinking time series analysis by integrating multimodal inputs. However, as the use of LLMs becomes popular, we must remain cautious, asking why we use LLMs and how to exploit them effectively. Most existing LLM-based methods still employ their numerical regression ability and ignore their deeper reasoning potential. This paper argues for rethinking time series with LLMs as a reasoning task that prioritizes causal structure and explainability. This shift brings time series analysis closer to human-aligned understanding, enabling transparent and context-aware insights in complex real-world environments. Read More
From Narratives to Probabilistic Reasoning: Predicting and Interpreting Drivers’ Hazardous Actions in Crashes Using Large Language Modelcs.AI updates on arXiv.org arXiv:2510.13002v1 Announce Type: new
Abstract: Vehicle crashes involve complex interactions between road users, split-second decisions, and challenging environmental conditions. Among these, two-vehicle crashes are the most prevalent, accounting for approximately 70% of roadway crashes and posing a significant challenge to traffic safety. Identifying Driver Hazardous Action (DHA) is essential for understanding crash causation, yet the reliability of DHA data in large-scale databases is limited by inconsistent and labor-intensive manual coding practices. Here, we present an innovative framework that leverages a fine-tuned large language model to automatically infer DHAs from textual crash narratives, thereby improving the validity and interpretability of DHA classifications. Using five years of two-vehicle crash data from MTCF, we fine-tuned the Llama 3.2 1B model on detailed crash narratives and benchmarked its performance against conventional machine learning classifiers, including Random Forest, XGBoost, CatBoost, and a neural network. The fine-tuned LLM achieved an overall accuracy of 80%, surpassing all baseline models and demonstrating pronounced improvements in scenarios with imbalanced data. To increase interpretability, we developed a probabilistic reasoning approach, analyzing model output shifts across original test sets and three targeted counterfactual scenarios: variations in driver distraction and age. Our analysis revealed that introducing distraction for one driver substantially increased the likelihood of “General Unsafe Driving”; distraction for both drivers maximized the probability of “Both Drivers Took Hazardous Actions”; and assigning a teen driver markedly elevated the probability of “Speed and Stopping Violations.” Our framework and analytical methods provide a robust and interpretable solution for large-scale automated DHA detection, offering new opportunities for traffic safety analysis and intervention.
arXiv:2510.13002v1 Announce Type: new
Abstract: Vehicle crashes involve complex interactions between road users, split-second decisions, and challenging environmental conditions. Among these, two-vehicle crashes are the most prevalent, accounting for approximately 70% of roadway crashes and posing a significant challenge to traffic safety. Identifying Driver Hazardous Action (DHA) is essential for understanding crash causation, yet the reliability of DHA data in large-scale databases is limited by inconsistent and labor-intensive manual coding practices. Here, we present an innovative framework that leverages a fine-tuned large language model to automatically infer DHAs from textual crash narratives, thereby improving the validity and interpretability of DHA classifications. Using five years of two-vehicle crash data from MTCF, we fine-tuned the Llama 3.2 1B model on detailed crash narratives and benchmarked its performance against conventional machine learning classifiers, including Random Forest, XGBoost, CatBoost, and a neural network. The fine-tuned LLM achieved an overall accuracy of 80%, surpassing all baseline models and demonstrating pronounced improvements in scenarios with imbalanced data. To increase interpretability, we developed a probabilistic reasoning approach, analyzing model output shifts across original test sets and three targeted counterfactual scenarios: variations in driver distraction and age. Our analysis revealed that introducing distraction for one driver substantially increased the likelihood of “General Unsafe Driving”; distraction for both drivers maximized the probability of “Both Drivers Took Hazardous Actions”; and assigning a teen driver markedly elevated the probability of “Speed and Stopping Violations.” Our framework and analytical methods provide a robust and interpretable solution for large-scale automated DHA detection, offering new opportunities for traffic safety analysis and intervention. Read More
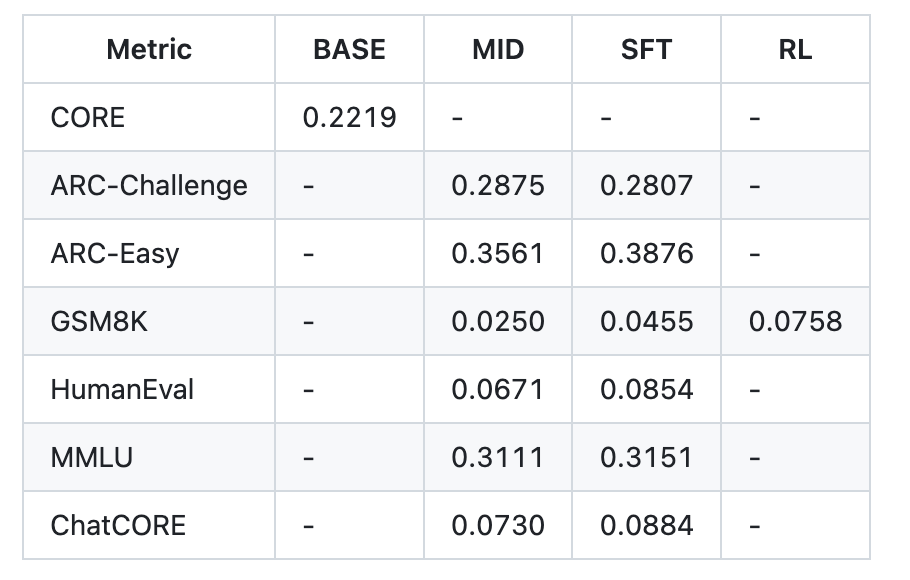
Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100MarkTechPost Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase that implements a full ChatGPT-style stack—from tokenizer training to web UI inference—aimed at reproducible, hackable LLM training on a single multi-GPU node. The repo provides a single-script “speedrun” that executes the full loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use data, Supervised Finetuning (SFT), optional RL on
The post Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100 appeared first on MarkTechPost.
Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase that implements a full ChatGPT-style stack—from tokenizer training to web UI inference—aimed at reproducible, hackable LLM training on a single multi-GPU node. The repo provides a single-script “speedrun” that executes the full loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use data, Supervised Finetuning (SFT), optional RL on
The post Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100 appeared first on MarkTechPost. Read More
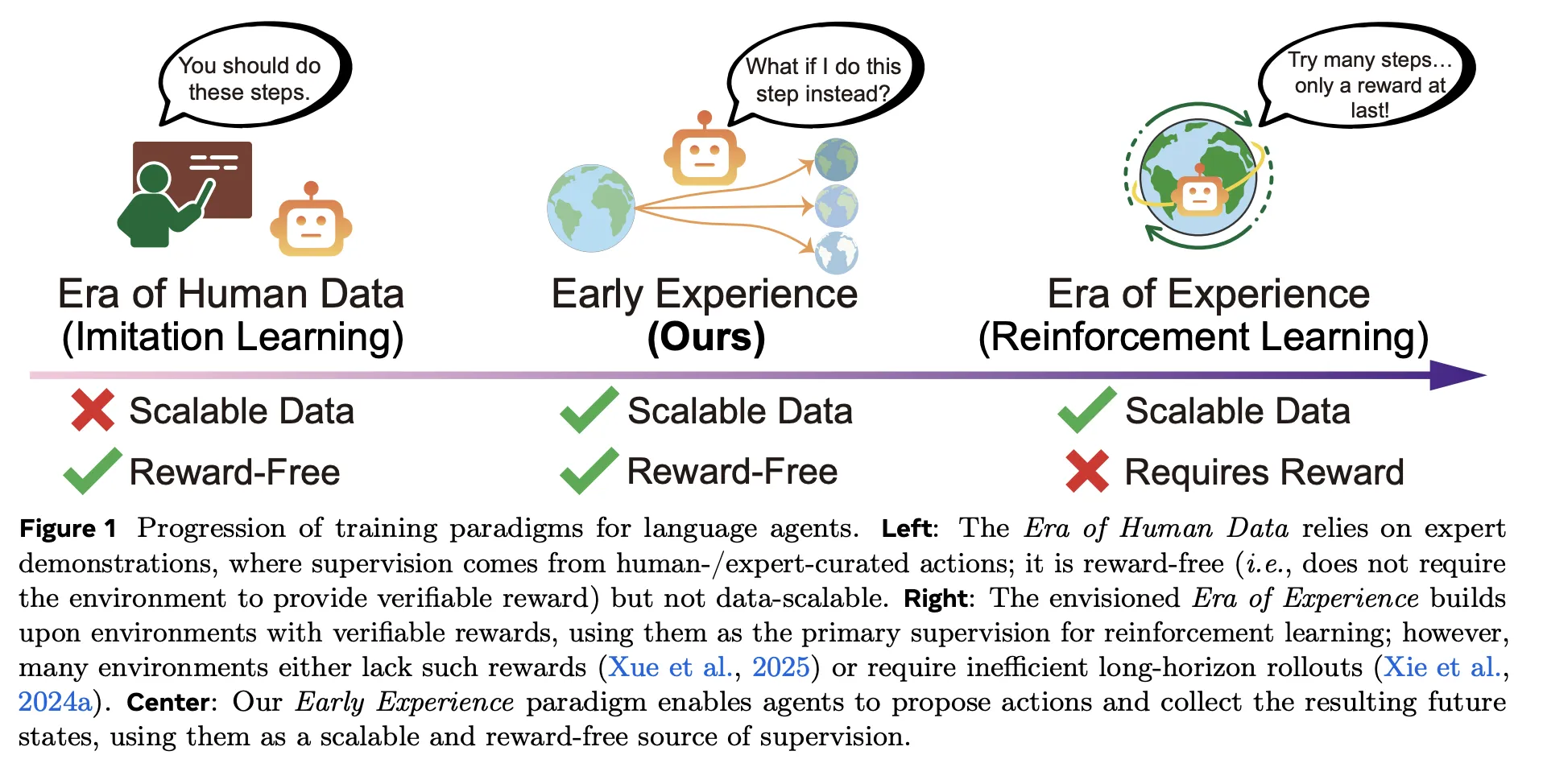
Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation LearningMarkTechPost How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet beat imitation learning across eight benchmarks? Meta Superintelligence Labs propose ‘Early Experience‘, a reward-free training approach that improves policy learning in language agents without large human demonstration sets and without reinforcement learning (RL) in the
The post Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning appeared first on MarkTechPost.
How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet beat imitation learning across eight benchmarks? Meta Superintelligence Labs propose ‘Early Experience‘, a reward-free training approach that improves policy learning in language agents without large human demonstration sets and without reinforcement learning (RL) in the
The post Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning appeared first on MarkTechPost. Read More
LiteVPNet: A Lightweight Network for Video Encoding Control in Quality-Critical Applicationscs.AI updates on arXiv.org arXiv:2510.12379v1 Announce Type: cross
Abstract: In the last decade, video workflows in the cinema production ecosystem have presented new use cases for video streaming technology. These new workflows, e.g. in On-set Virtual Production, present the challenge of requiring precise quality control and energy efficiency. Existing approaches to transcoding often fall short of these requirements, either due to a lack of quality control or computational overhead. To fill this gap, we present a lightweight neural network (LiteVPNet) for accurately predicting Quantisation Parameters for NVENC AV1 encoders that achieve a specified VMAF score. We use low-complexity features, including bitstream characteristics, video complexity measures, and CLIP-based semantic embeddings. Our results demonstrate that LiteVPNet achieves mean VMAF errors below 1.2 points across a wide range of quality targets. Notably, LiteVPNet achieves VMAF errors within 2 points for over 87% of our test corpus, c.f. approx 61% with state-of-the-art methods. LiteVPNet’s performance across various quality regions highlights its applicability for enhancing high-value content transport and streaming for more energy-efficient, high-quality media experiences.
arXiv:2510.12379v1 Announce Type: cross
Abstract: In the last decade, video workflows in the cinema production ecosystem have presented new use cases for video streaming technology. These new workflows, e.g. in On-set Virtual Production, present the challenge of requiring precise quality control and energy efficiency. Existing approaches to transcoding often fall short of these requirements, either due to a lack of quality control or computational overhead. To fill this gap, we present a lightweight neural network (LiteVPNet) for accurately predicting Quantisation Parameters for NVENC AV1 encoders that achieve a specified VMAF score. We use low-complexity features, including bitstream characteristics, video complexity measures, and CLIP-based semantic embeddings. Our results demonstrate that LiteVPNet achieves mean VMAF errors below 1.2 points across a wide range of quality targets. Notably, LiteVPNet achieves VMAF errors within 2 points for over 87% of our test corpus, c.f. approx 61% with state-of-the-art methods. LiteVPNet’s performance across various quality regions highlights its applicability for enhancing high-value content transport and streaming for more energy-efficient, high-quality media experiences. Read More