
How accounting firms are using AI agents to reclaim time and trustAI News For CFOs and CIOs under pressure to modernise finance operations, automation, as seen in several generations of RPA (robotic process automation), isn’t enough. It’s apparent that transparency and explainability matter just as much. Accounting firms and finance functions inside organisations are now turning to AI systems that reason, not just compute. One of the most
The post How accounting firms are using AI agents to reclaim time and trust appeared first on AI News.
For CFOs and CIOs under pressure to modernise finance operations, automation, as seen in several generations of RPA (robotic process automation), isn’t enough. It’s apparent that transparency and explainability matter just as much. Accounting firms and finance functions inside organisations are now turning to AI systems that reason, not just compute. One of the most
The post How accounting firms are using AI agents to reclaim time and trust appeared first on AI News. Read More

China’s generative AI user base doubles to 515 million in six monthsAI News The AI adoption in China has reached unprecedented levels, with the country’s generative artificial intelligence user base doubling to 515 million in just six months, according to a report released by the China Internet Network Information Centre (CNNIC). This dramatic expansion represents an adoption rate of 36.5% in the first half of 2025, positioning China
The post China’s generative AI user base doubles to 515 million in six months appeared first on AI News.
The AI adoption in China has reached unprecedented levels, with the country’s generative artificial intelligence user base doubling to 515 million in just six months, according to a report released by the China Internet Network Information Centre (CNNIC). This dramatic expansion represents an adoption rate of 36.5% in the first half of 2025, positioning China
The post China’s generative AI user base doubles to 515 million in six months appeared first on AI News. Read More
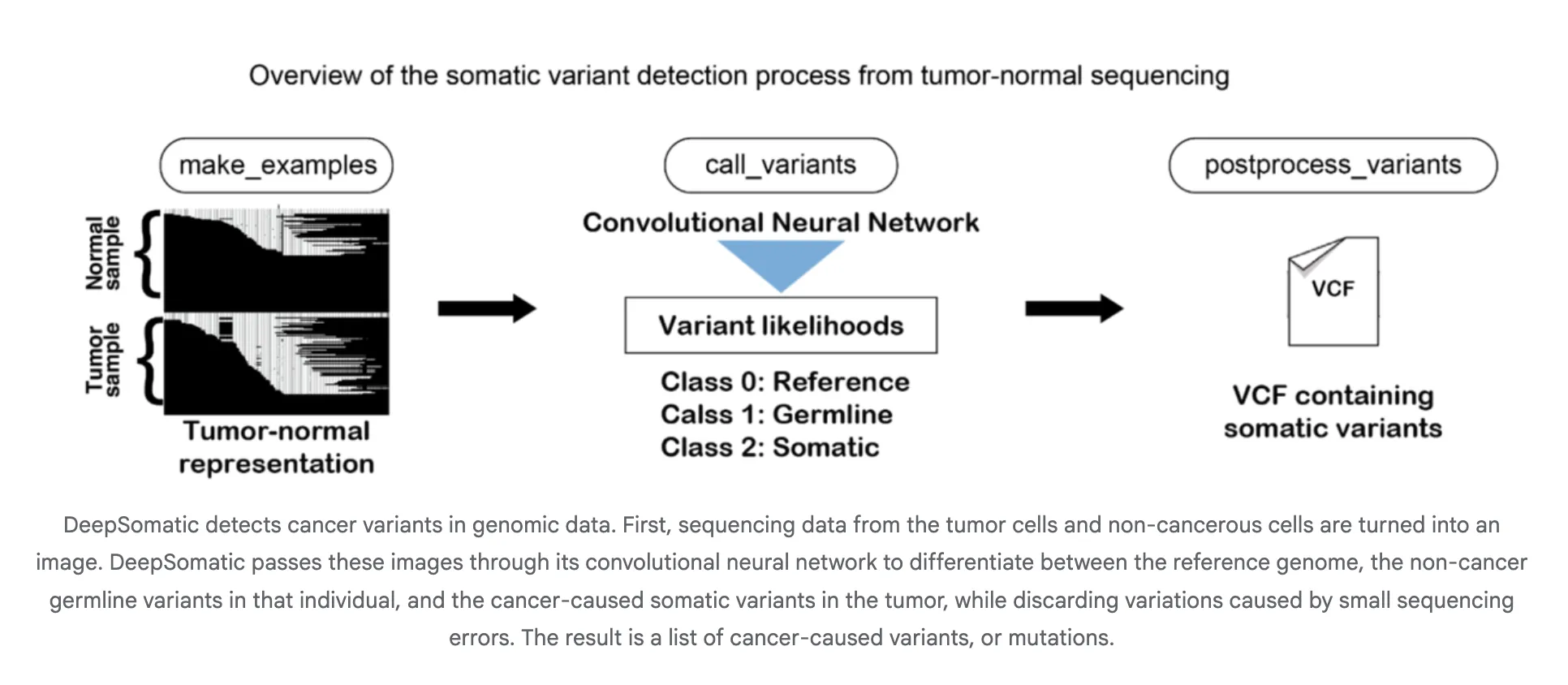
Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic VariantsMarkTechPost A team of researchers from Google Research and UC Santa Cruz released DeepSomatic, an AI model that identifies cancer cell genetic variants. In research with Children’s Mercy, it found 10 variants in pediatric leukemia cells missed by other tools. DeepSomatic has a somatic small variant caller for cancer genomes that works across Illumina short reads,
The post Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic Variants appeared first on MarkTechPost.
A team of researchers from Google Research and UC Santa Cruz released DeepSomatic, an AI model that identifies cancer cell genetic variants. In research with Children’s Mercy, it found 10 variants in pediatric leukemia cells missed by other tools. DeepSomatic has a somatic small variant caller for cancer genomes that works across Illumina short reads,
The post Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic Variants appeared first on MarkTechPost. Read More
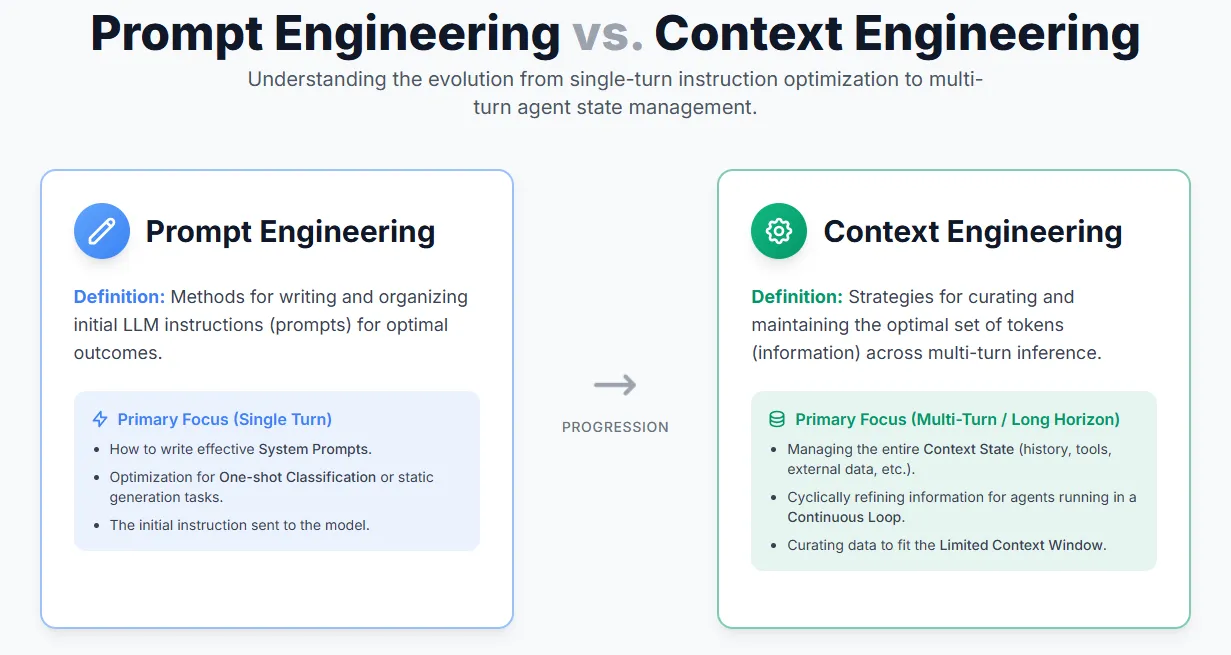
A Guide for Effective Context Engineering for AI AgentsMarkTechPost Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost.
Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost. Read More

Learning to Interpret Weight Differences in Language Modelscs.AI updates on arXiv.org arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions.
arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions. Read More
Changing Base Without Losing Pace: A GPU-Efficient Alternative to MatMul in DNNscs.AI updates on arXiv.org arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI.
arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI. Read More
AppCopilot: Toward General, Accurate, Long-Horizon, and Efficient Mobile Agentcs.AI updates on arXiv.org arXiv:2509.02444v2 Announce Type: replace
Abstract: With the raid evolution of large language models and multimodal models, the mobile-agent landscape has proliferated without converging on the fundamental challenges. This paper identifies four core problems that should be solved for mobile agents to deliver practical, scalable impact: (1) generalization across tasks, APPs, and devices; (2) accuracy, specifically precise on-screen interaction and click targeting; (3) long-horizon capability for sustained, multi-step goals; and (4) efficiency, specifically high-performance runtime on resource-constrained devices. We present AppCopilot, a multimodal, multi-agent, general-purpose mobile agent that operates across applications. AppCopilot operationalizes this position through an end-to-end pipeline spanning data collection, training, finetuning, efficient inference, and PC/mobile application. At the model layer, it integrates multimodal foundation models with robust Chinese-English support. At the reasoning and control layer, it combines chain-of-thought reasoning, hierarchical task planning and decomposition, and multi-agent collaboration. At the execution layer, it enables experiential adaptation, voice interaction, function calling, cross-APP and cross-device orchestration, and comprehensive mobile APP support. The system design incorporates profiling-driven optimization for latency and memory across heterogeneous hardware. Empirically, AppCopilot achieves significant improvements on four dimensions: stronger generalization, higher precision of on screen actions, more reliable long horizon task completion, and faster, more resource efficient runtime. By articulating a cohesive position and a reference architecture that closes the loop from data collection, training to finetuning and efficient inference, this paper offers a concrete roadmap for general purpose mobile agent and provides actionable guidance.
arXiv:2509.02444v2 Announce Type: replace
Abstract: With the raid evolution of large language models and multimodal models, the mobile-agent landscape has proliferated without converging on the fundamental challenges. This paper identifies four core problems that should be solved for mobile agents to deliver practical, scalable impact: (1) generalization across tasks, APPs, and devices; (2) accuracy, specifically precise on-screen interaction and click targeting; (3) long-horizon capability for sustained, multi-step goals; and (4) efficiency, specifically high-performance runtime on resource-constrained devices. We present AppCopilot, a multimodal, multi-agent, general-purpose mobile agent that operates across applications. AppCopilot operationalizes this position through an end-to-end pipeline spanning data collection, training, finetuning, efficient inference, and PC/mobile application. At the model layer, it integrates multimodal foundation models with robust Chinese-English support. At the reasoning and control layer, it combines chain-of-thought reasoning, hierarchical task planning and decomposition, and multi-agent collaboration. At the execution layer, it enables experiential adaptation, voice interaction, function calling, cross-APP and cross-device orchestration, and comprehensive mobile APP support. The system design incorporates profiling-driven optimization for latency and memory across heterogeneous hardware. Empirically, AppCopilot achieves significant improvements on four dimensions: stronger generalization, higher precision of on screen actions, more reliable long horizon task completion, and faster, more resource efficient runtime. By articulating a cohesive position and a reference architecture that closes the loop from data collection, training to finetuning and efficient inference, this paper offers a concrete roadmap for general purpose mobile agent and provides actionable guidance. Read More

5 Docker Containers for Your AI InfrastructureKDnuggets Below are five of the most useful Docker containers that can help you build a powerful AI infrastructure in 2026, without the need to wrestle with environment mismatches or missing dependencies.
Below are five of the most useful Docker containers that can help you build a powerful AI infrastructure in 2026, without the need to wrestle with environment mismatches or missing dependencies. Read More
How to Build Guardrails for Effective AgentsTowards Data Science Learn how to set up effective guardrails to enforce desired behaviour from your agents
The post How to Build Guardrails for Effective Agents appeared first on Towards Data Science.
Learn how to set up effective guardrails to enforce desired behaviour from your agents
The post How to Build Guardrails for Effective Agents appeared first on Towards Data Science. Read More
What Layers When: Learning to Skip Compute in LLMs with Residual Gatescs.AI updates on arXiv.org arXiv:2510.13876v2 Announce Type: replace-cross
Abstract: We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch’s output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding.
arXiv:2510.13876v2 Announce Type: replace-cross
Abstract: We introduce GateSkip, a simple residual-stream gating mechanism that enables token-wise layer skipping in decoder-only LMs. Each Attention/MLP branch is equipped with a sigmoid-linear gate that condenses the branch’s output before it re-enters the residual stream. During inference we rank tokens by the gate values and skip low-importance ones using a per-layer budget. While early-exit or router-based Mixture-of-Depths models are known to be unstable and need extensive retraining, our smooth, differentiable gates fine-tune stably on top of pretrained models. On long-form reasoning, we save up to 15% compute while retaining over 90% of baseline accuracy. For increasingly larger models, this tradeoff improves drastically. On instruction-tuned models we see accuracy gains at full compute and match baseline quality near 50% savings. The learned gates give insight into transformer information flow (e.g., BOS tokens act as anchors), and the method combines easily with quantization, pruning, and self-speculative decoding. Read More