
UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Editingcs.AI updates on arXiv.org arXiv:2602.02437v4 Announce Type: replace-cross
Abstract: Unified multimodal models often struggle with complex synthesis tasks that demand deep reasoning, and typically treat text-to-image generation and image editing as isolated capabilities rather than interconnected reasoning steps. To address this, we propose UniReason, a unified framework that harmonizes these two tasks through two complementary reasoning paradigms. We incorporate world knowledge-enhanced textual reasoning into generation to infer implicit knowledge, and leverage editing capabilities for fine-grained editing-like visual refinement to further correct visual errors via self-reflection. This approach unifies generation and editing within a shared architecture, mirroring the human cognitive process of planning followed by refinement. We support this framework by systematically constructing a large-scale reasoning-centric dataset (~300k samples) covering five major knowledge domains (e.g., cultural commonsense, physics, etc.) for textual reasoning, alongside an agent-generated corpus for visual refinement. Extensive experiments demonstrate that UniReason achieves advanced performance on reasoning-intensive benchmarks such as WISE, KrisBench and UniREditBench, while maintaining superior general synthesis capabilities.
arXiv:2602.02437v4 Announce Type: replace-cross
Abstract: Unified multimodal models often struggle with complex synthesis tasks that demand deep reasoning, and typically treat text-to-image generation and image editing as isolated capabilities rather than interconnected reasoning steps. To address this, we propose UniReason, a unified framework that harmonizes these two tasks through two complementary reasoning paradigms. We incorporate world knowledge-enhanced textual reasoning into generation to infer implicit knowledge, and leverage editing capabilities for fine-grained editing-like visual refinement to further correct visual errors via self-reflection. This approach unifies generation and editing within a shared architecture, mirroring the human cognitive process of planning followed by refinement. We support this framework by systematically constructing a large-scale reasoning-centric dataset (~300k samples) covering five major knowledge domains (e.g., cultural commonsense, physics, etc.) for textual reasoning, alongside an agent-generated corpus for visual refinement. Extensive experiments demonstrate that UniReason achieves advanced performance on reasoning-intensive benchmarks such as WISE, KrisBench and UniREditBench, while maintaining superior general synthesis capabilities. Read More

Hitachi bets on industrial expertise to win the physical AI raceAI News Physical AI–the branch of artificial intelligence that controls robots and industrial machinery in the real world–has a hierarchy problem. At the top, OpenAI and Google are scaling multimodal foundation models. In the middle, Nvidia is building the platforms and tools for physical AI development. And then there is a third camp: industrial manufacturers like Hitachi
The post Hitachi bets on industrial expertise to win the physical AI race appeared first on AI News.
Physical AI–the branch of artificial intelligence that controls robots and industrial machinery in the real world–has a hierarchy problem. At the top, OpenAI and Google are scaling multimodal foundation models. In the middle, Nvidia is building the platforms and tools for physical AI development. And then there is a third camp: industrial manufacturers like Hitachi
The post Hitachi bets on industrial expertise to win the physical AI race appeared first on AI News. Read More

Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inferenceMarkTechPost In the high-stakes world of AI infrastructure, the industry has operated under a singular assumption: flexibility is king. We build general-purpose GPUs because AI models change every week, and we need programmable silicon that can adapt to the next research breakthrough. But Taalas, the Toronto-based startup thinks that flexibility is exactly what’s holding AI back.
The post Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inference appeared first on MarkTechPost.
In the high-stakes world of AI infrastructure, the industry has operated under a singular assumption: flexibility is king. We build general-purpose GPUs because AI models change every week, and we need programmable silicon that can adapt to the next research breakthrough. But Taalas, the Toronto-based startup thinks that flexibility is exactly what’s holding AI back.
The post Taalas is replacing programmable GPUs with hardwired AI chips to achieve 17,000 tokens per second for ubiquitous inference appeared first on MarkTechPost. Read More
The Reality of Vibe Coding: AI Agents and the Security Debt CrisisTowards Data Science Why optimizing for speed over safety is leaving applications vulnerable, and how to fix it.
The post The Reality of Vibe Coding: AI Agents and the Security Debt Crisis appeared first on Towards Data Science.
Why optimizing for speed over safety is leaving applications vulnerable, and how to fix it.
The post The Reality of Vibe Coding: AI Agents and the Security Debt Crisis appeared first on Towards Data Science. Read More
Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use CasesMarkTechPost The balance of power in the digital age is shifting. While governments and large corporations have long used data to track individuals, a new open-source project called OpenPlanter is giving that power back to the public. Created by a developer ‘Shin Megami Boson‘, OpenPlanter is a recursive-language-model investigation agent. Its goal is simple: help you
The post Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use Cases appeared first on MarkTechPost.
The balance of power in the digital age is shifting. While governments and large corporations have long used data to track individuals, a new open-source project called OpenPlanter is giving that power back to the public. Created by a developer ‘Shin Megami Boson‘, OpenPlanter is a recursive-language-model investigation agent. Its goal is simple: help you
The post Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use Cases appeared first on MarkTechPost. Read More
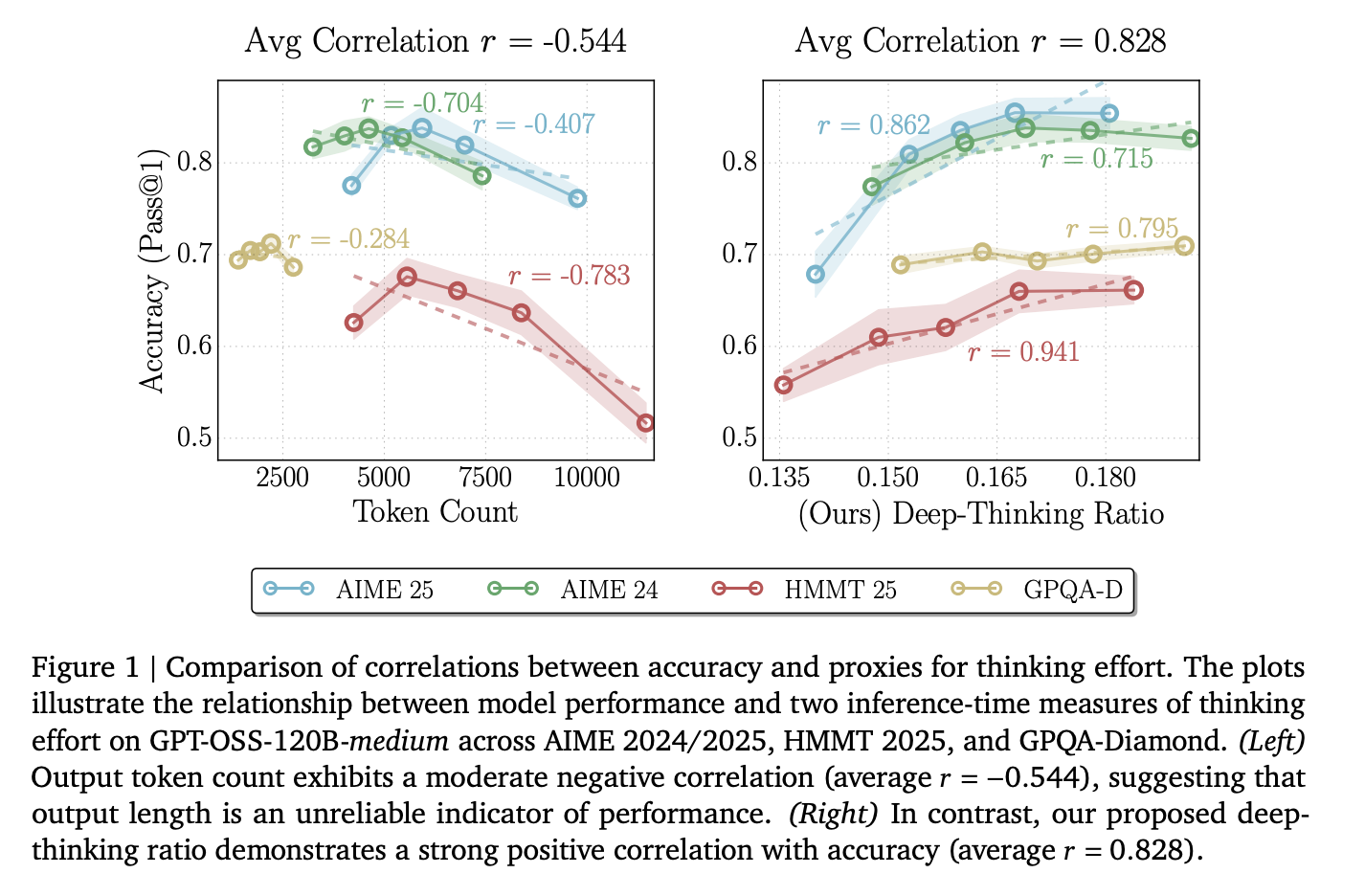
A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by HalfMarkTechPost For the last few years, the AI world has followed a simple rule: if you want a Large Language Model (LLM) to solve a harder problem, make its Chain-of-Thought (CoT) longer. But new research from the University of Virginia and Google proves that ‘thinking long’ is not the same as ‘thinking hard’. The research team
The post A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half appeared first on MarkTechPost.
For the last few years, the AI world has followed a simple rule: if you want a Large Language Model (LLM) to solve a harder problem, make its Chain-of-Thought (CoT) longer. But new research from the University of Virginia and Google proves that ‘thinking long’ is not the same as ‘thinking hard’. The research team
The post A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half appeared first on MarkTechPost. Read More
How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured OutputsMarkTechPost In this tutorial, we build a production-style Route Optimizer Agent for a logistics dispatch center using the latest LangChain agent APIs. We design a tool-driven workflow in which the agent reliably computes distances, ETAs, and optimal routes rather than guessing, and we enforce structured outputs to make the results directly usable in downstream systems. We
The post How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured Outputs appeared first on MarkTechPost.
In this tutorial, we build a production-style Route Optimizer Agent for a logistics dispatch center using the latest LangChain agent APIs. We design a tool-driven workflow in which the agent reliably computes distances, ETAs, and optimal routes rather than guessing, and we enforce structured outputs to make the results directly usable in downstream systems. We
The post How to Design an Agentic Workflow for Tool-Driven Route Optimization with Deterministic Computation and Structured Outputs appeared first on MarkTechPost. Read More

NVIDIA Releases DreamDojo: An Open-Source Robot World Model Trained on 44,711 Hours of Real-World Human Video DataMarkTechPost Building simulators for robots has been a long term challenge. Traditional engines require manual coding of physics and perfect 3D models. NVIDIA is changing this with DreamDojo, a fully open-source, generalizable robot world model. Instead of using a physics engine, DreamDojo ‘dreams’ the results of robot actions directly in pixels. Scaling Robotics with 44k+ Hours
The post NVIDIA Releases DreamDojo: An Open-Source Robot World Model Trained on 44,711 Hours of Real-World Human Video Data appeared first on MarkTechPost.
Building simulators for robots has been a long term challenge. Traditional engines require manual coding of physics and perfect 3D models. NVIDIA is changing this with DreamDojo, a fully open-source, generalizable robot world model. Instead of using a physics engine, DreamDojo ‘dreams’ the results of robot actions directly in pixels. Scaling Robotics with 44k+ Hours
The post NVIDIA Releases DreamDojo: An Open-Source Robot World Model Trained on 44,711 Hours of Real-World Human Video Data appeared first on MarkTechPost. Read More
Amazon SageMaker AI in 2025, a year in review part 2: Improved observability and enhanced features for SageMaker AI model customization and hostingArtificial Intelligence In 2025, Amazon SageMaker AI made several improvements designed to help you train, tune, and host generative AI workloads. In Part 1 of this series, we discussed Flexible Training Plans and price performance improvements made to inference components. In this post, we discuss enhancements made to observability, model customization, and model hosting. These improvements facilitate a whole new class of customer use cases to be hosted on SageMaker AI.
In 2025, Amazon SageMaker AI made several improvements designed to help you train, tune, and host generative AI workloads. In Part 1 of this series, we discussed Flexible Training Plans and price performance improvements made to inference components. In this post, we discuss enhancements made to observability, model customization, and model hosting. These improvements facilitate a whole new class of customer use cases to be hosted on SageMaker AI. Read More
How to Design a Swiss Army Knife Research Agent with Tool-Using AI, Web Search, PDF Analysis, Vision, and Automated ReportingMarkTechPost In this tutorial, we build a “Swiss Army Knife” research agent that goes far beyond simple chat interactions and actively solves multi-step research problems end-to-end. We combine a tool-using agent architecture with live web search, local PDF ingestion, vision-based chart analysis, and automated report generation to demonstrate how modern agents can reason, verify, and produce
The post How to Design a Swiss Army Knife Research Agent with Tool-Using AI, Web Search, PDF Analysis, Vision, and Automated Reporting appeared first on MarkTechPost.
In this tutorial, we build a “Swiss Army Knife” research agent that goes far beyond simple chat interactions and actively solves multi-step research problems end-to-end. We combine a tool-using agent architecture with live web search, local PDF ingestion, vision-based chart analysis, and automated report generation to demonstrate how modern agents can reason, verify, and produce
The post How to Design a Swiss Army Knife Research Agent with Tool-Using AI, Web Search, PDF Analysis, Vision, and Automated Reporting appeared first on MarkTechPost. Read More