
Why Foundation Models in Pathology Are Failingcs.AI updates on arXiv.org arXiv:2510.23807v1 Announce Type: new
Abstract: In non-medical domains, foundation models (FMs) have revolutionized computer vision and language processing through large-scale self-supervised and multimodal learning. Consequently, their rapid adoption in computational pathology was expected to deliver comparable breakthroughs in cancer diagnosis, prognostication, and multimodal retrieval. However, recent systematic evaluations reveal fundamental weaknesses: low diagnostic accuracy, poor robustness, geometric instability, heavy computational demands, and concerning safety vulnerabilities. This short paper examines these shortcomings and argues that they stem from deeper conceptual mismatches between the assumptions underlying generic foundation modeling in mainstream AI and the intrinsic complexity of human tissue. Seven interrelated causes are identified: biological complexity, ineffective self-supervision, overgeneralization, excessive architectural complexity, lack of domain-specific innovation, insufficient data, and a fundamental design flaw related to tissue patch size. These findings suggest that current pathology foundation models remain conceptually misaligned with the nature of tissue morphology and call for a fundamental rethinking of the paradigm itself.
arXiv:2510.23807v1 Announce Type: new
Abstract: In non-medical domains, foundation models (FMs) have revolutionized computer vision and language processing through large-scale self-supervised and multimodal learning. Consequently, their rapid adoption in computational pathology was expected to deliver comparable breakthroughs in cancer diagnosis, prognostication, and multimodal retrieval. However, recent systematic evaluations reveal fundamental weaknesses: low diagnostic accuracy, poor robustness, geometric instability, heavy computational demands, and concerning safety vulnerabilities. This short paper examines these shortcomings and argues that they stem from deeper conceptual mismatches between the assumptions underlying generic foundation modeling in mainstream AI and the intrinsic complexity of human tissue. Seven interrelated causes are identified: biological complexity, ineffective self-supervision, overgeneralization, excessive architectural complexity, lack of domain-specific innovation, insufficient data, and a fundamental design flaw related to tissue patch size. These findings suggest that current pathology foundation models remain conceptually misaligned with the nature of tissue morphology and call for a fundamental rethinking of the paradigm itself. Read More

OpenAI unveils open-weight AI safety models for developersAI News OpenAI is putting more safety controls directly into the hands of AI developers with a new research preview of “safeguard” models. The new ‘gpt-oss-safeguard’ family of open-weight models is aimed squarely at customising content classification. The new offering will include two models, gpt-oss-safeguard-120b and a smaller gpt-oss-safeguard-20b. Both are fine-tuned versions of the existing gpt-oss
The post OpenAI unveils open-weight AI safety models for developers appeared first on AI News.
OpenAI is putting more safety controls directly into the hands of AI developers with a new research preview of “safeguard” models. The new ‘gpt-oss-safeguard’ family of open-weight models is aimed squarely at customising content classification. The new offering will include two models, gpt-oss-safeguard-120b and a smaller gpt-oss-safeguard-20b. Both are fine-tuned versions of the existing gpt-oss
The post OpenAI unveils open-weight AI safety models for developers appeared first on AI News. Read More
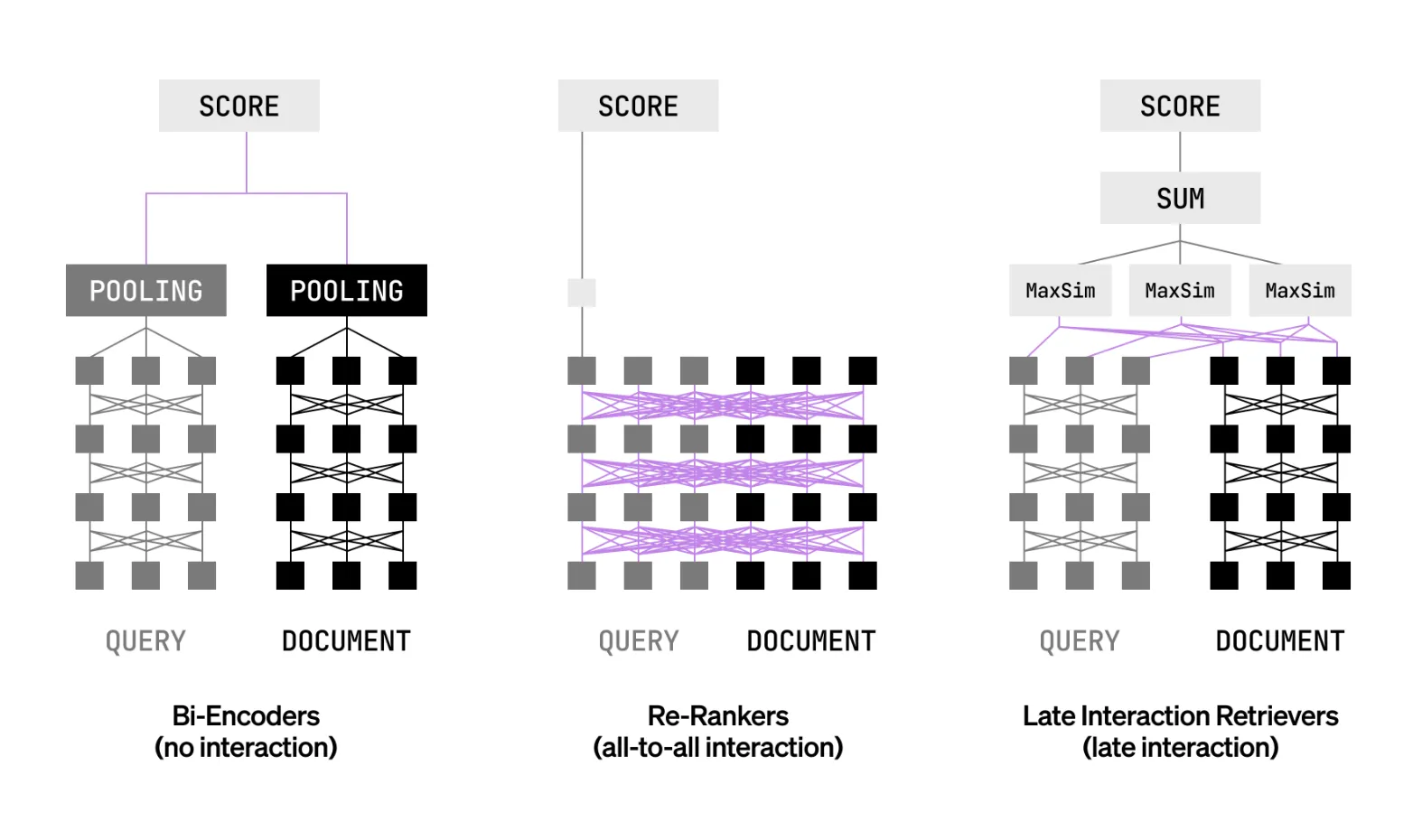
Liquid AI Releases LFM2-ColBERT-350M: A New Small Model that brings Late Interaction Retrieval to Multilingual and Cross-Lingual RAGMarkTechPost Can a compact late interaction retriever index once and deliver accurate cross lingual search with fast inference? Liquid AI released LFM2-ColBERT-350M, a compact late interaction retriever for multilingual and cross-lingual search. Documents can be indexed in one language, queries can be written in many languages, and the system retrieves with high accuracy. The Liquid AI
The post Liquid AI Releases LFM2-ColBERT-350M: A New Small Model that brings Late Interaction Retrieval to Multilingual and Cross-Lingual RAG appeared first on MarkTechPost.
Can a compact late interaction retriever index once and deliver accurate cross lingual search with fast inference? Liquid AI released LFM2-ColBERT-350M, a compact late interaction retriever for multilingual and cross-lingual search. Documents can be indexed in one language, queries can be written in many languages, and the system retrieves with high accuracy. The Liquid AI
The post Liquid AI Releases LFM2-ColBERT-350M: A New Small Model that brings Late Interaction Retrieval to Multilingual and Cross-Lingual RAG appeared first on MarkTechPost. Read More
A High-Dimensional Statistical Method for Optimizing Transfer Quantities in Multi-Source Transfer Learningcs.AI updates on arXiv.org arXiv:2502.04242v4 Announce Type: replace-cross
Abstract: Multi-source transfer learning provides an effective solution to data scarcity in real- world supervised learning scenarios by leveraging multiple source tasks. In this field, existing works typically use all available samples from sources in training, which constrains their training efficiency and may lead to suboptimal results. To address this, we propose a theoretical framework that answers the question: what is the optimal quantity of source samples needed from each source task to jointly train the target model? Specifically, we introduce a generalization error measure based on K-L divergence, and minimize it based on high-dimensional statistical analysis to determine the optimal transfer quantity for each source task. Additionally, we develop an architecture-agnostic and data-efficient algorithm OTQMS to implement our theoretical results for target model training in multi- source transfer learning. Experimental studies on diverse architectures and two real-world benchmark datasets show that our proposed algorithm significantly outperforms state-of-the-art approaches in both accuracy and data efficiency. The code and supplementary materials are available in https://github.com/zqy0126/OTQMS.
arXiv:2502.04242v4 Announce Type: replace-cross
Abstract: Multi-source transfer learning provides an effective solution to data scarcity in real- world supervised learning scenarios by leveraging multiple source tasks. In this field, existing works typically use all available samples from sources in training, which constrains their training efficiency and may lead to suboptimal results. To address this, we propose a theoretical framework that answers the question: what is the optimal quantity of source samples needed from each source task to jointly train the target model? Specifically, we introduce a generalization error measure based on K-L divergence, and minimize it based on high-dimensional statistical analysis to determine the optimal transfer quantity for each source task. Additionally, we develop an architecture-agnostic and data-efficient algorithm OTQMS to implement our theoretical results for target model training in multi- source transfer learning. Experimental studies on diverse architectures and two real-world benchmark datasets show that our proposed algorithm significantly outperforms state-of-the-art approaches in both accuracy and data efficiency. The code and supplementary materials are available in https://github.com/zqy0126/OTQMS. Read More
Understanding AI Trustworthiness: A Scoping Review of AIES & FAccT Articlescs.AI updates on arXiv.org arXiv:2510.21293v2 Announce Type: replace
Abstract: Background: Trustworthy AI serves as a foundational pillar for two major AI ethics conferences: AIES and FAccT. However, current research often adopts techno-centric approaches, focusing primarily on technical attributes such as reliability, robustness, and fairness, while overlooking the sociotechnical dimensions critical to understanding AI trustworthiness in real-world contexts.
Objectives: This scoping review aims to examine how the AIES and FAccT communities conceptualize, measure, and validate AI trustworthiness, identifying major gaps and opportunities for advancing a holistic understanding of trustworthy AI systems.
Methods: We conduct a scoping review of AIES and FAccT conference proceedings to date, systematically analyzing how trustworthiness is defined, operationalized, and applied across different research domains. Our analysis focuses on conceptualization approaches, measurement methods, verification and validation techniques, application areas, and underlying values.
Results: While significant progress has been made in defining technical attributes such as transparency, accountability, and robustness, our findings reveal critical gaps. Current research often predominantly emphasizes technical precision at the expense of social and ethical considerations. The sociotechnical nature of AI systems remains less explored and trustworthiness emerges as a contested concept shaped by those with the power to define it.
Conclusions: An interdisciplinary approach combining technical rigor with social, cultural, and institutional considerations is essential for advancing trustworthy AI. We propose actionable measures for the AI ethics community to adopt holistic frameworks that genuinely address the complex interplay between AI systems and society, ultimately promoting responsible technological development that benefits all stakeholders.
arXiv:2510.21293v2 Announce Type: replace
Abstract: Background: Trustworthy AI serves as a foundational pillar for two major AI ethics conferences: AIES and FAccT. However, current research often adopts techno-centric approaches, focusing primarily on technical attributes such as reliability, robustness, and fairness, while overlooking the sociotechnical dimensions critical to understanding AI trustworthiness in real-world contexts.
Objectives: This scoping review aims to examine how the AIES and FAccT communities conceptualize, measure, and validate AI trustworthiness, identifying major gaps and opportunities for advancing a holistic understanding of trustworthy AI systems.
Methods: We conduct a scoping review of AIES and FAccT conference proceedings to date, systematically analyzing how trustworthiness is defined, operationalized, and applied across different research domains. Our analysis focuses on conceptualization approaches, measurement methods, verification and validation techniques, application areas, and underlying values.
Results: While significant progress has been made in defining technical attributes such as transparency, accountability, and robustness, our findings reveal critical gaps. Current research often predominantly emphasizes technical precision at the expense of social and ethical considerations. The sociotechnical nature of AI systems remains less explored and trustworthiness emerges as a contested concept shaped by those with the power to define it.
Conclusions: An interdisciplinary approach combining technical rigor with social, cultural, and institutional considerations is essential for advancing trustworthy AI. We propose actionable measures for the AI ethics community to adopt holistic frameworks that genuinely address the complex interplay between AI systems and society, ultimately promoting responsible technological development that benefits all stakeholders. Read More
ComboBench: Can LLMs Manipulate Physical Devices to Play Virtual Reality Games?cs.AI updates on arXiv.org arXiv:2510.24706v1 Announce Type: cross
Abstract: Virtual Reality (VR) games require players to translate high-level semantic actions into precise device manipulations using controllers and head-mounted displays (HMDs). While humans intuitively perform this translation based on common sense and embodied understanding, whether Large Language Models (LLMs) can effectively replicate this ability remains underexplored. This paper introduces a benchmark, ComboBench, evaluating LLMs’ capability to translate semantic actions into VR device manipulation sequences across 262 scenarios from four popular VR games: Half-Life: Alyx, Into the Radius, Moss: Book II, and Vivecraft. We evaluate seven LLMs, including GPT-3.5, GPT-4, GPT-4o, Gemini-1.5-Pro, LLaMA-3-8B, Mixtral-8x7B, and GLM-4-Flash, compared against annotated ground truth and human performance. Our results reveal that while top-performing models like Gemini-1.5-Pro demonstrate strong task decomposition capabilities, they still struggle with procedural reasoning and spatial understanding compared to humans. Performance varies significantly across games, suggesting sensitivity to interaction complexity. Few-shot examples substantially improve performance, indicating potential for targeted enhancement of LLMs’ VR manipulation capabilities. We release all materials at https://sites.google.com/view/combobench.
arXiv:2510.24706v1 Announce Type: cross
Abstract: Virtual Reality (VR) games require players to translate high-level semantic actions into precise device manipulations using controllers and head-mounted displays (HMDs). While humans intuitively perform this translation based on common sense and embodied understanding, whether Large Language Models (LLMs) can effectively replicate this ability remains underexplored. This paper introduces a benchmark, ComboBench, evaluating LLMs’ capability to translate semantic actions into VR device manipulation sequences across 262 scenarios from four popular VR games: Half-Life: Alyx, Into the Radius, Moss: Book II, and Vivecraft. We evaluate seven LLMs, including GPT-3.5, GPT-4, GPT-4o, Gemini-1.5-Pro, LLaMA-3-8B, Mixtral-8x7B, and GLM-4-Flash, compared against annotated ground truth and human performance. Our results reveal that while top-performing models like Gemini-1.5-Pro demonstrate strong task decomposition capabilities, they still struggle with procedural reasoning and spatial understanding compared to humans. Performance varies significantly across games, suggesting sensitivity to interaction complexity. Few-shot examples substantially improve performance, indicating potential for targeted enhancement of LLMs’ VR manipulation capabilities. We release all materials at https://sites.google.com/view/combobench. Read More
Metadata-Driven Retrieval-Augmented Generation for Financial Question Answeringcs.AI updates on arXiv.org arXiv:2510.24402v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) struggles on long, structured financial filings where relevant evidence is sparse and cross-referenced. This paper presents a systematic investigation of advanced metadata-driven Retrieval-Augmented Generation (RAG) techniques, proposing and evaluating a novel, multi-stage RAG architecture that leverages LLM-generated metadata. We introduce a sophisticated indexing pipeline to create contextually rich document chunks and benchmark a spectrum of enhancements, including pre-retrieval filtering, post-retrieval reranking, and enriched embeddings, benchmarked on the FinanceBench dataset. Our results reveal that while a powerful reranker is essential for precision, the most significant performance gains come from embedding chunk metadata directly with text (“contextual chunks”). Our proposed optimal architecture combines LLM-driven pre-retrieval optimizations with these contextual embeddings to achieve superior performance. Additionally, we present a custom metadata reranker that offers a compelling, cost-effective alternative to commercial solutions, highlighting a practical trade-off between peak performance and operational efficiency. This study provides a blueprint for building robust, metadata-aware RAG systems for financial document analysis.
arXiv:2510.24402v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) struggles on long, structured financial filings where relevant evidence is sparse and cross-referenced. This paper presents a systematic investigation of advanced metadata-driven Retrieval-Augmented Generation (RAG) techniques, proposing and evaluating a novel, multi-stage RAG architecture that leverages LLM-generated metadata. We introduce a sophisticated indexing pipeline to create contextually rich document chunks and benchmark a spectrum of enhancements, including pre-retrieval filtering, post-retrieval reranking, and enriched embeddings, benchmarked on the FinanceBench dataset. Our results reveal that while a powerful reranker is essential for precision, the most significant performance gains come from embedding chunk metadata directly with text (“contextual chunks”). Our proposed optimal architecture combines LLM-driven pre-retrieval optimizations with these contextual embeddings to achieve superior performance. Additionally, we present a custom metadata reranker that offers a compelling, cost-effective alternative to commercial solutions, highlighting a practical trade-off between peak performance and operational efficiency. This study provides a blueprint for building robust, metadata-aware RAG systems for financial document analysis. Read More
GraSS: Scalable Data Attribution with Gradient Sparsification and Sparse Projectioncs.AI updates on arXiv.org arXiv:2505.18976v3 Announce Type: replace-cross
Abstract: Gradient-based data attribution methods, such as influence functions, are critical for understanding the impact of individual training samples without requiring repeated model retraining. However, their scalability is often limited by the high computational and memory costs associated with per-sample gradient computation. In this work, we propose GraSS, a novel gradient compression algorithm and its variants FactGraSS for linear layers specifically, that explicitly leverage the inherent sparsity of per-sample gradients to achieve sub-linear space and time complexity. Extensive experiments demonstrate the effectiveness of our approach, achieving substantial speedups while preserving data influence fidelity. In particular, FactGraSS achieves up to 165% faster throughput on billion-scale models compared to the previous state-of-the-art baselines. Our code is publicly available at https://github.com/TRAIS-Lab/GraSS.
arXiv:2505.18976v3 Announce Type: replace-cross
Abstract: Gradient-based data attribution methods, such as influence functions, are critical for understanding the impact of individual training samples without requiring repeated model retraining. However, their scalability is often limited by the high computational and memory costs associated with per-sample gradient computation. In this work, we propose GraSS, a novel gradient compression algorithm and its variants FactGraSS for linear layers specifically, that explicitly leverage the inherent sparsity of per-sample gradients to achieve sub-linear space and time complexity. Extensive experiments demonstrate the effectiveness of our approach, achieving substantial speedups while preserving data influence fidelity. In particular, FactGraSS achieves up to 165% faster throughput on billion-scale models compared to the previous state-of-the-art baselines. Our code is publicly available at https://github.com/TRAIS-Lab/GraSS. Read More
HyPerNav: Hybrid Perception for Object-Oriented Navigation in Unknown Environmentcs.AI updates on arXiv.org arXiv:2510.22917v2 Announce Type: replace-cross
Abstract: Objective-oriented navigation(ObjNav) enables robot to navigate to target object directly and autonomously in an unknown environment. Effective perception in navigation in unknown environment is critical for autonomous robots. While egocentric observations from RGB-D sensors provide abundant local information, real-time top-down maps offer valuable global context for ObjNav. Nevertheless, the majority of existing studies focus on a single source, seldom integrating these two complementary perceptual modalities, despite the fact that humans naturally attend to both. With the rapid advancement of Vision-Language Models(VLMs), we propose Hybrid Perception Navigation (HyPerNav), leveraging VLMs’ strong reasoning and vision-language understanding capabilities to jointly perceive both local and global information to enhance the effectiveness and intelligence of navigation in unknown environments. In both massive simulation evaluation and real-world validation, our methods achieved state-of-the-art performance against popular baselines. Benefiting from hybrid perception approach, our method captures richer cues and finds the objects more effectively, by simultaneously leveraging information understanding from egocentric observations and the top-down map. Our ablation study further proved that either of the hybrid perception contributes to the navigation performance.
arXiv:2510.22917v2 Announce Type: replace-cross
Abstract: Objective-oriented navigation(ObjNav) enables robot to navigate to target object directly and autonomously in an unknown environment. Effective perception in navigation in unknown environment is critical for autonomous robots. While egocentric observations from RGB-D sensors provide abundant local information, real-time top-down maps offer valuable global context for ObjNav. Nevertheless, the majority of existing studies focus on a single source, seldom integrating these two complementary perceptual modalities, despite the fact that humans naturally attend to both. With the rapid advancement of Vision-Language Models(VLMs), we propose Hybrid Perception Navigation (HyPerNav), leveraging VLMs’ strong reasoning and vision-language understanding capabilities to jointly perceive both local and global information to enhance the effectiveness and intelligence of navigation in unknown environments. In both massive simulation evaluation and real-world validation, our methods achieved state-of-the-art performance against popular baselines. Benefiting from hybrid perception approach, our method captures richer cues and finds the objects more effectively, by simultaneously leveraging information understanding from egocentric observations and the top-down map. Our ablation study further proved that either of the hybrid perception contributes to the navigation performance. Read More
Test-Time Tuned Language Models Enable End-to-end De Novo Molecular Structure Generation from MS/MS Spectracs.AI updates on arXiv.org arXiv:2510.23746v1 Announce Type: new
Abstract: Tandem Mass Spectrometry enables the identification of unknown compounds in crucial fields such as metabolomics, natural product discovery and environmental analysis. However, current methods rely on database matching from previously observed molecules, or on multi-step pipelines that require intermediate fragment or fingerprint prediction. This makes finding the correct molecule highly challenging, particularly for compounds absent from reference databases. We introduce a framework that, by leveraging test-time tuning, enhances the learning of a pre-trained transformer model to address this gap, enabling end-to-end de novo molecular structure generation directly from the tandem mass spectra and molecular formulae, bypassing manual annotations and intermediate steps. We surpass the de-facto state-of-the-art approach DiffMS on two popular benchmarks NPLIB1 and MassSpecGym by 100% and 20%, respectively. Test-time tuning on experimental spectra allows the model to dynamically adapt to novel spectra, and the relative performance gain over conventional fine-tuning is of 62% on MassSpecGym. When predictions deviate from the ground truth, the generated molecular candidates remain structurally accurate, providing valuable guidance for human interpretation and more reliable identification.
arXiv:2510.23746v1 Announce Type: new
Abstract: Tandem Mass Spectrometry enables the identification of unknown compounds in crucial fields such as metabolomics, natural product discovery and environmental analysis. However, current methods rely on database matching from previously observed molecules, or on multi-step pipelines that require intermediate fragment or fingerprint prediction. This makes finding the correct molecule highly challenging, particularly for compounds absent from reference databases. We introduce a framework that, by leveraging test-time tuning, enhances the learning of a pre-trained transformer model to address this gap, enabling end-to-end de novo molecular structure generation directly from the tandem mass spectra and molecular formulae, bypassing manual annotations and intermediate steps. We surpass the de-facto state-of-the-art approach DiffMS on two popular benchmarks NPLIB1 and MassSpecGym by 100% and 20%, respectively. Test-time tuning on experimental spectra allows the model to dynamically adapt to novel spectra, and the relative performance gain over conventional fine-tuning is of 62% on MassSpecGym. When predictions deviate from the ground truth, the generated molecular candidates remain structurally accurate, providing valuable guidance for human interpretation and more reliable identification. Read More