
“The success of an AI product depends on how intuitively users can interact with its capabilities”Towards Data Science Janna Lipenkova on AI strategy, AI products, and how domain knowledge can change the entire shape of an AI solution.
The post “The success of an AI product depends on how intuitively users can interact with its capabilities” appeared first on Towards Data Science.
Janna Lipenkova on AI strategy, AI products, and how domain knowledge can change the entire shape of an AI solution.
The post “The success of an AI product depends on how intuitively users can interact with its capabilities” appeared first on Towards Data Science. Read More
How to Crack Machine Learning System-Design InterviewsTowards Data Science A comprehensive guide into Meta, Apple, Reddit, Amazon, Google, and Snap ML design interviews
The post How to Crack Machine Learning System-Design Interviews appeared first on Towards Data Science.
A comprehensive guide into Meta, Apple, Reddit, Amazon, Google, and Snap ML design interviews
The post How to Crack Machine Learning System-Design Interviews appeared first on Towards Data Science. Read More

Building AI Automations with Google OpalKDnuggets Google Opal is a no-code, experimental tool from Google Labs. It is designed to enable users to build and share AI-powered micro-applications using natural language.
Google Opal is a no-code, experimental tool from Google Labs. It is designed to enable users to build and share AI-powered micro-applications using natural language. Read More
How to Design an Advanced Multi-Agent Reasoning System with spaCy Featuring Planning, Reflection, Memory, and Knowledge GraphsMarkTechPost In this tutorial, we build an advanced Agentic AI system using spaCy, designed to allow multiple intelligent agents to reason, collaborate, reflect, and learn from experience. We work through the entire pipeline step by step, observing how each agent processes tasks using planning, memory, communication, and semantic reasoning. By the end, we see how the
The post How to Design an Advanced Multi-Agent Reasoning System with spaCy Featuring Planning, Reflection, Memory, and Knowledge Graphs appeared first on MarkTechPost.
In this tutorial, we build an advanced Agentic AI system using spaCy, designed to allow multiple intelligent agents to reason, collaborate, reflect, and learn from experience. We work through the entire pipeline step by step, observing how each agent processes tasks using planning, memory, communication, and semantic reasoning. By the end, we see how the
The post How to Design an Advanced Multi-Agent Reasoning System with spaCy Featuring Planning, Reflection, Memory, and Knowledge Graphs appeared first on MarkTechPost. Read More
Comparing the Top 6 Agent-Native Rails for the Agentic Internet: MCP, A2A, AP2, ACP, x402, and KiteMarkTechPost As AI agents move from single-app copilots to autonomous systems that browse, transact, and coordinate with each other, a new infrastructure layer is emerging underneath them. This article compares six key “agent-native rails” — MCP, A2A, AP2, ACP, x402, and Kite — focusing on how they standardize tool access, inter-agent communication, payment authorization, and settlement,
The post Comparing the Top 6 Agent-Native Rails for the Agentic Internet: MCP, A2A, AP2, ACP, x402, and Kite appeared first on MarkTechPost.
As AI agents move from single-app copilots to autonomous systems that browse, transact, and coordinate with each other, a new infrastructure layer is emerging underneath them. This article compares six key “agent-native rails” — MCP, A2A, AP2, ACP, x402, and Kite — focusing on how they standardize tool access, inter-agent communication, payment authorization, and settlement,
The post Comparing the Top 6 Agent-Native Rails for the Agentic Internet: MCP, A2A, AP2, ACP, x402, and Kite appeared first on MarkTechPost. Read More
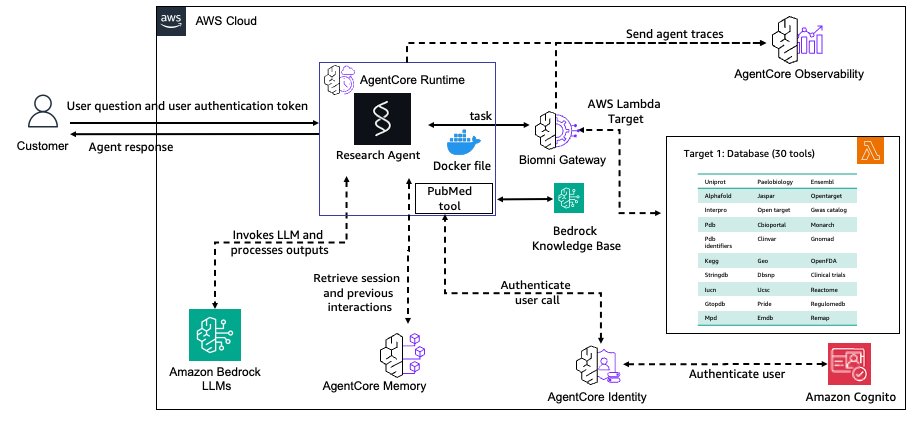
Build a biomedical research agent with Biomni tools and Amazon Bedrock AgentCore GatewayArtificial Intelligence In this post, we demonstrate how to build a production-ready biomedical research agent by integrating Biomni’s specialized tools with Amazon Bedrock AgentCore Gateway, enabling researchers to access over 30 biomedical databases through a secure, scalable infrastructure. The implementation showcases how to transform research prototypes into enterprise-grade systems with persistent memory, semantic tool discovery, and comprehensive observability for scientific reproducibility .
In this post, we demonstrate how to build a production-ready biomedical research agent by integrating Biomni’s specialized tools with Amazon Bedrock AgentCore Gateway, enabling researchers to access over 30 biomedical databases through a secure, scalable infrastructure. The implementation showcases how to transform research prototypes into enterprise-grade systems with persistent memory, semantic tool discovery, and comprehensive observability for scientific reproducibility . Read More
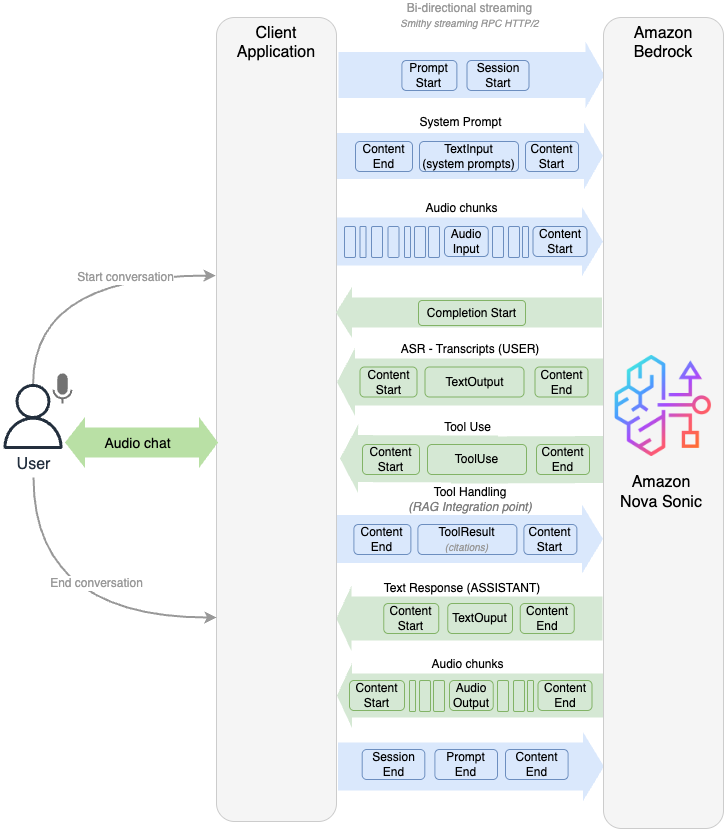
Make your web apps hands-free with Amazon Nova SonicArtificial Intelligence Graphical user interfaces have carried the torch for decades, but today’s users increasingly expect to talk to their applications. In this post we show how we added a true voice-first experience to a reference application—the Smart Todo App—turning routine task management into a fluid, hands-free conversation.
Graphical user interfaces have carried the torch for decades, but today’s users increasingly expect to talk to their applications. In this post we show how we added a true voice-first experience to a reference application—the Smart Todo App—turning routine task management into a fluid, hands-free conversation. Read More

Anthropic details cyber espionage campaign orchestrated by AIAI News Security leaders face a new class of autonomous threat as Anthropic details the first cyber espionage campaign orchestrated by AI. In a report released this week, the company’s Threat Intelligence team outlined its disruption of a sophisticated operation by a Chinese state-sponsored group – an assessment made with high confidence – dubbed GTG-1002 and detected
The post Anthropic details cyber espionage campaign orchestrated by AI appeared first on AI News.
Security leaders face a new class of autonomous threat as Anthropic details the first cyber espionage campaign orchestrated by AI. In a report released this week, the company’s Threat Intelligence team outlined its disruption of a sophisticated operation by a Chinese state-sponsored group – an assessment made with high confidence – dubbed GTG-1002 and detected
The post Anthropic details cyber espionage campaign orchestrated by AI appeared first on AI News. Read More
Meet SDialog: An Open-Source Python Toolkit for Building, Simulating, and Evaluating LLM-based Conversational Agents End-to-EndMarkTechPost How can developers reliably generate, control, and inspect large volumes of realistic dialogue data without building a custom simulation stack every time? Meet SDialog, an open sourced Python toolkit for synthetic dialogue generation, evaluation, and interpretability that targets the full conversational pipeline from agent definition to analysis. It standardizes how a Dialog is represented and
The post Meet SDialog: An Open-Source Python Toolkit for Building, Simulating, and Evaluating LLM-based Conversational Agents End-to-End appeared first on MarkTechPost.
How can developers reliably generate, control, and inspect large volumes of realistic dialogue data without building a custom simulation stack every time? Meet SDialog, an open sourced Python toolkit for synthetic dialogue generation, evaluation, and interpretability that targets the full conversational pipeline from agent definition to analysis. It standardizes how a Dialog is represented and
The post Meet SDialog: An Open-Source Python Toolkit for Building, Simulating, and Evaluating LLM-based Conversational Agents End-to-End appeared first on MarkTechPost. Read More
Visa builds AI commerce infrastructure for the Asia Pacific’s 2026 PilotAI News When Visa unveiled its Intelligent Commerce platform for Asia Pacific on November 12, it wasn’t just launching another payment feature—it was building AI commerce infrastructure to solve a crisis most merchants haven’t noticed yet: their websites are being flooded by AI agents, and there’s no reliable way to tell which ones are legitimate shoppers and which are malicious bots.
The post Visa builds AI commerce infrastructure for the Asia Pacific’s 2026 Pilot appeared first on AI News.
When Visa unveiled its Intelligent Commerce platform for Asia Pacific on November 12, it wasn’t just launching another payment feature—it was building AI commerce infrastructure to solve a crisis most merchants haven’t noticed yet: their websites are being flooded by AI agents, and there’s no reliable way to tell which ones are legitimate shoppers and which are malicious bots.
The post Visa builds AI commerce infrastructure for the Asia Pacific’s 2026 Pilot appeared first on AI News. Read More