
A single beam of light runs AI with supercomputer powerArtificial Intelligence News — ScienceDaily Aalto University researchers have developed a method to execute AI tensor operations using just one pass of light. By encoding data directly into light waves, they enable calculations to occur naturally and simultaneously. The approach works passively, without electronics, and could soon be integrated into photonic chips. If adopted, it promises dramatically faster and more energy-efficient AI systems.
Aalto University researchers have developed a method to execute AI tensor operations using just one pass of light. By encoding data directly into light waves, they enable calculations to occur naturally and simultaneously. The approach works passively, without electronics, and could soon be integrated into photonic chips. If adopted, it promises dramatically faster and more energy-efficient AI systems. Read More
How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term AutonomyMarkTechPost In this tutorial, we explore how to build agentic systems that think beyond a single interaction by utilizing memory as a core capability. We walk through how we design episodic memory to store experiences and semantic memory to capture long-term patterns, allowing the agent to evolve its behaviour over multiple sessions. As we implement planning,
The post How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term Autonomy appeared first on MarkTechPost.
In this tutorial, we explore how to build agentic systems that think beyond a single interaction by utilizing memory as a core capability. We walk through how we design episodic memory to store experiences and semantic memory to capture long-term patterns, allowing the agent to evolve its behaviour over multiple sessions. As we implement planning,
The post How to Build Memory-Powered Agentic AI That Learns Continuously Through Episodic Experiences and Semantic Patterns for Long-Term Autonomy appeared first on MarkTechPost. Read More

Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding AgentsMarkTechPost Cerebras has released MiniMax-M2-REAP-162B-A10B, a compressed Sparse Mixture-of-Experts (SMoE) Causal Language Model derived from MiniMax-M2, using the new Router weighted Expert Activation Pruning (REAP) method. The model keeps the behavior of the original 230B total, 10B active MiniMax M2, while pruning experts and reducing memory for deployment focused workloads such as coding agents and tool
The post Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding Agents appeared first on MarkTechPost.
Cerebras has released MiniMax-M2-REAP-162B-A10B, a compressed Sparse Mixture-of-Experts (SMoE) Causal Language Model derived from MiniMax-M2, using the new Router weighted Expert Activation Pruning (REAP) method. The model keeps the behavior of the original 230B total, 10B active MiniMax M2, while pruning experts and reducing memory for deployment focused workloads such as coding agents and tool
The post Cerebras Releases MiniMax-M2-REAP-162B-A10B: A Memory Efficient Version of MiniMax-M2 for Long Context Coding Agents appeared first on MarkTechPost. Read More
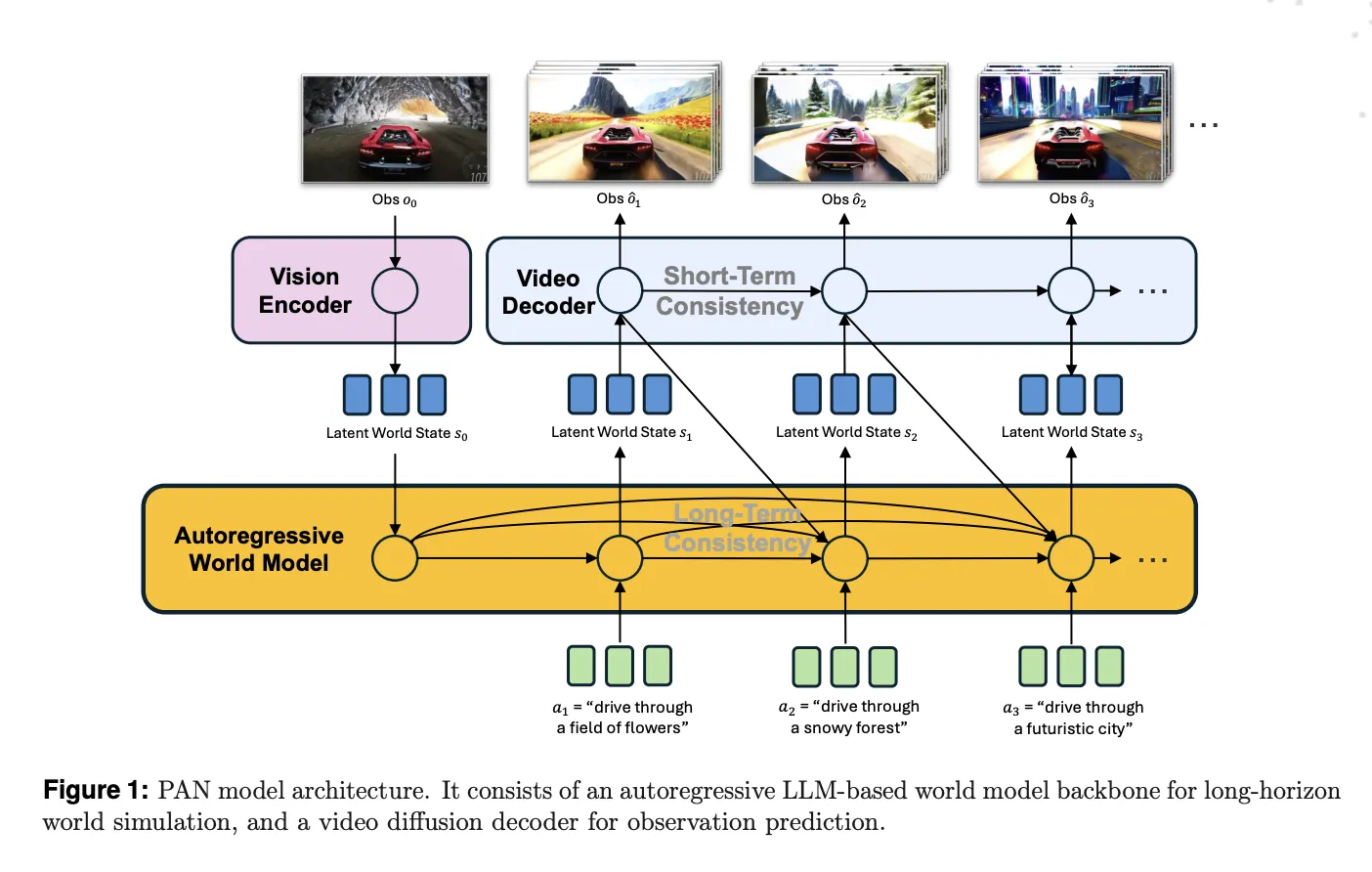
MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon SimulationMarkTechPost Most text to video models generate a single clip from a prompt and then stop. They do not keep an internal world state that persists as actions arrive over time. PAN, a new model from MBZUAI’s Institute of Foundation Models, is designed to fill that gap by acting as a general world model that predicts
The post MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon Simulation appeared first on MarkTechPost.
Most text to video models generate a single clip from a prompt and then stop. They do not keep an internal world state that persists as actions arrive over time. PAN, a new model from MBZUAI’s Institute of Foundation Models, is designed to fill that gap by acting as a general world model that predicts
The post MBZUAI Researchers Introduce PAN: A General World Model For Interactable Long Horizon Simulation appeared first on MarkTechPost. Read More
How to Automate Workflows with AITowards Data Science Learn how to take a manual process and optimize it using AI
The post How to Automate Workflows with AI appeared first on Towards Data Science.
Learn how to take a manual process and optimize it using AI
The post How to Automate Workflows with AI appeared first on Towards Data Science. Read More
How to Design a Fully Interactive, Reactive, and Dynamic Terminal-Based Data Dashboard Using Textual?MarkTechPost In this tutorial, we build an advanced interactive dashboard using Textual, and we explore how terminal-first UI frameworks can feel as expressive and dynamic as modern web dashboards. As we write and run each snippet, we actively construct the interface piece by piece, widgets, layouts, reactive state, and event flows, so we can see how
The post How to Design a Fully Interactive, Reactive, and Dynamic Terminal-Based Data Dashboard Using Textual? appeared first on MarkTechPost.
In this tutorial, we build an advanced interactive dashboard using Textual, and we explore how terminal-first UI frameworks can feel as expressive and dynamic as modern web dashboards. As we write and run each snippet, we actively construct the interface piece by piece, widgets, layouts, reactive state, and event flows, so we can see how
The post How to Design a Fully Interactive, Reactive, and Dynamic Terminal-Based Data Dashboard Using Textual? appeared first on MarkTechPost. Read More
Comparing the Top 5 AI Agent Architectures in 2025: Hierarchical, Swarm, Meta Learning, Modular, EvolutionaryMarkTechPost In 2025, ‘building an AI agent’ mostly means choosing an agent architecture: how perception, memory, learning, planning, and action are organized and coordinated. This comparison article looks at 5 concrete architectures: Comparison of the 5 architectures Architecture Control topology Learning focus Typical use cases Hierarchical Cognitive Agent Centralized, layered Layer specific control and planning Robotics,
The post Comparing the Top 5 AI Agent Architectures in 2025: Hierarchical, Swarm, Meta Learning, Modular, Evolutionary appeared first on MarkTechPost.
In 2025, ‘building an AI agent’ mostly means choosing an agent architecture: how perception, memory, learning, planning, and action are organized and coordinated. This comparison article looks at 5 concrete architectures: Comparison of the 5 architectures Architecture Control topology Learning focus Typical use cases Hierarchical Cognitive Agent Centralized, layered Layer specific control and planning Robotics,
The post Comparing the Top 5 AI Agent Architectures in 2025: Hierarchical, Swarm, Meta Learning, Modular, Evolutionary appeared first on MarkTechPost. Read More
I Measured Neural Network Training Every 5 Steps for 10,000 IterationsTowards Data Science Image by Pixabay.com
The post I Measured Neural Network Training Every 5 Steps for 10,000 Iterations appeared first on Towards Data Science.
Image by Pixabay.com
The post I Measured Neural Network Training Every 5 Steps for 10,000 Iterations appeared first on Towards Data Science. Read More
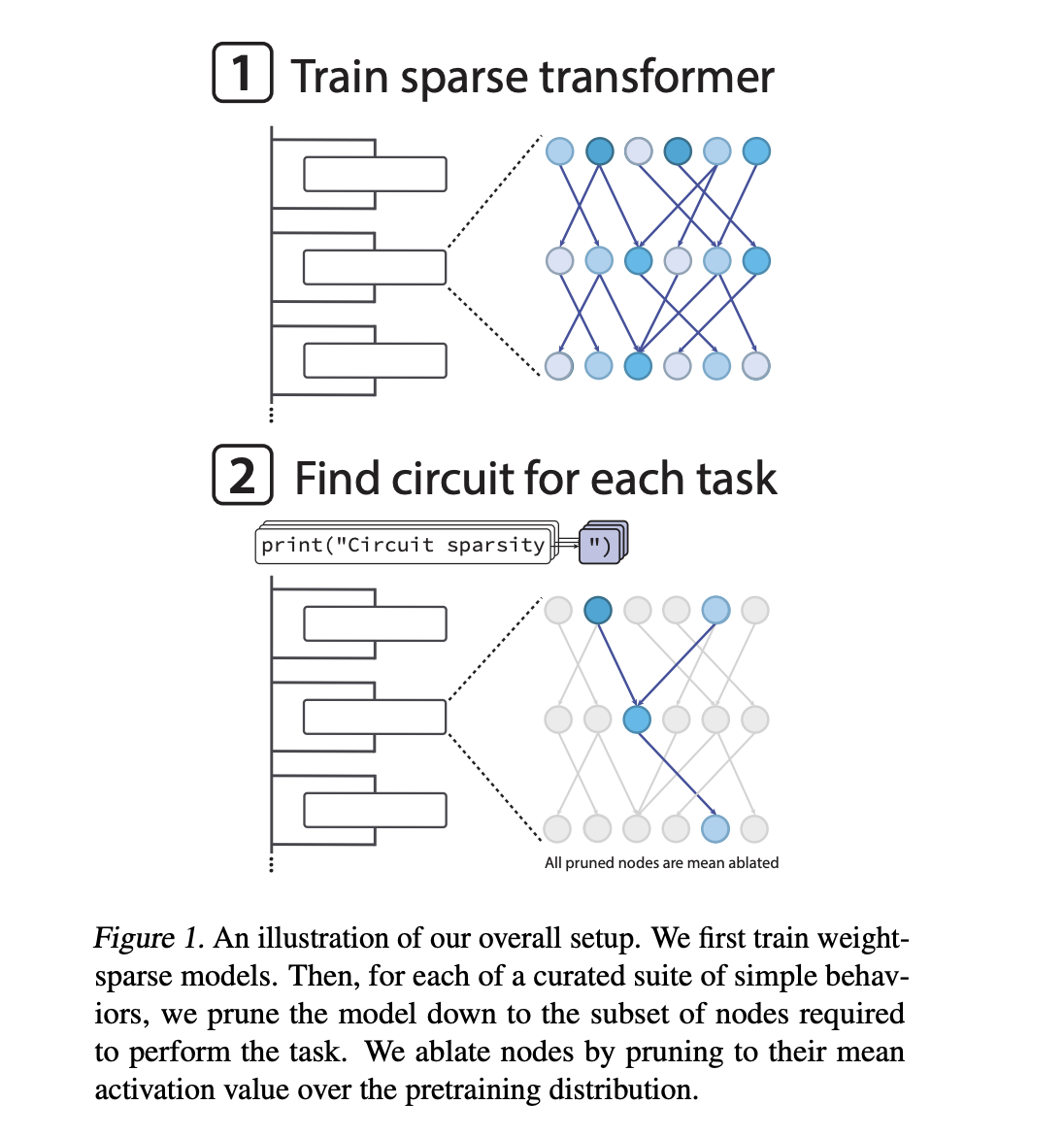
OpenAI Researchers Train Weight Sparse Transformers to Expose Interpretable CircuitsMarkTechPost If neural networks are now making decisions everywhere from code editors to safety systems, how can we actually see the specific circuits inside that drive each behavior? OpenAI has introduced a new mechanistic interpretability research study that trains language models to use sparse internal wiring, so that model behavior can be explained using small, explicit
The post OpenAI Researchers Train Weight Sparse Transformers to Expose Interpretable Circuits appeared first on MarkTechPost.
If neural networks are now making decisions everywhere from code editors to safety systems, how can we actually see the specific circuits inside that drive each behavior? OpenAI has introduced a new mechanistic interpretability research study that trains language models to use sparse internal wiring, so that model behavior can be explained using small, explicit
The post OpenAI Researchers Train Weight Sparse Transformers to Expose Interpretable Circuits appeared first on MarkTechPost. Read More
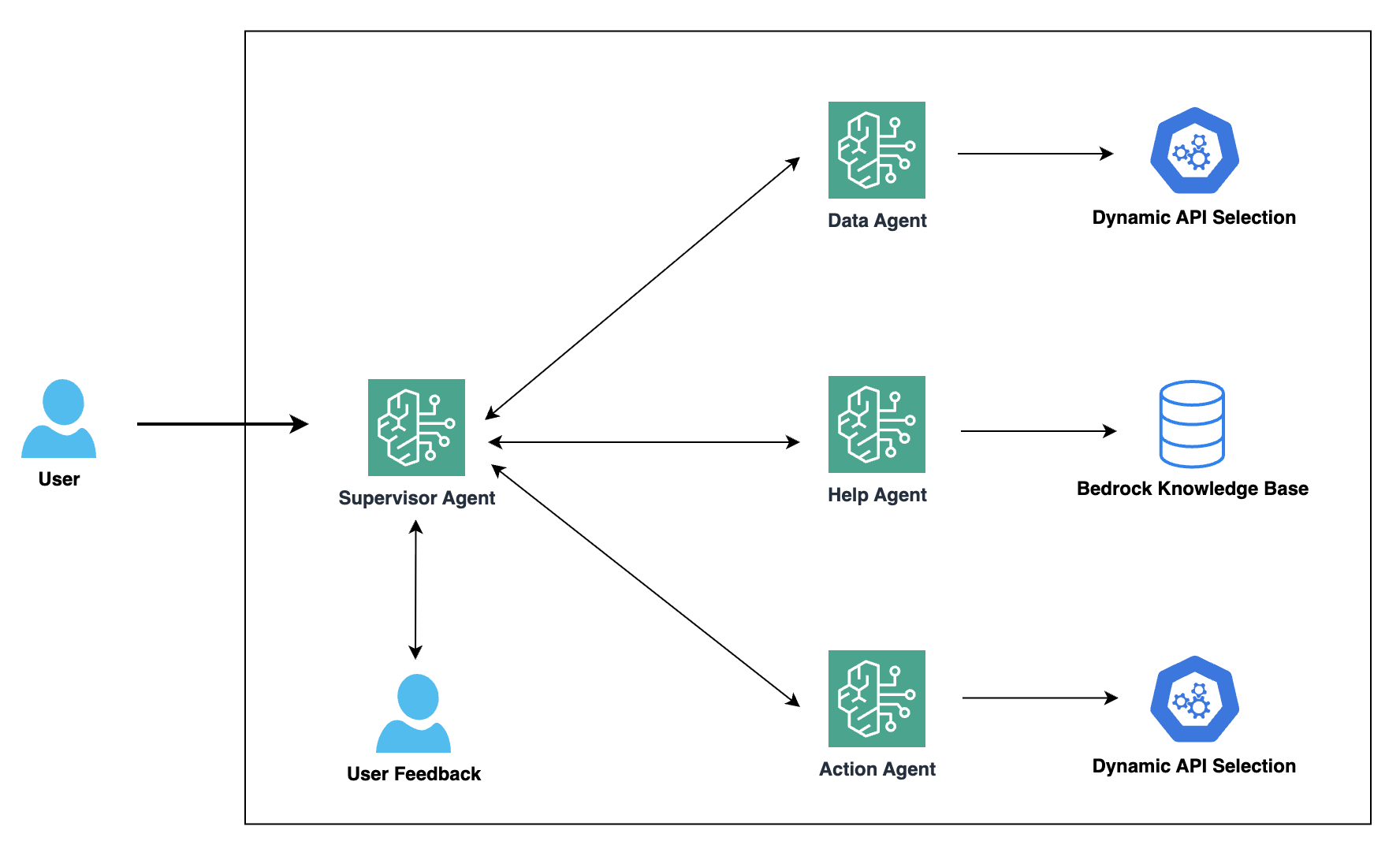
Harnessing the power of generative AI: Druva’s multi-agent copilot for streamlined data protectionArtificial Intelligence Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience.
Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience. Read More