
Multimodal Multi-Agent Empowered Legal Judgment Predictioncs.AI updates on arXiv.org arXiv:2601.12815v5 Announce Type: cross
Abstract: Legal Judgment Prediction (LJP) aims to predict the outcomes of legal cases based on factual descriptions, serving as a fundamental task to advance the development of legal systems. Traditional methods often rely on statistical analyses or role-based simulations but face challenges with multiple allegations, diverse evidence, and lack adaptability. In this paper, we introduce JurisMMA, a novel framework for LJP that effectively decomposes trial tasks, standardizes processes, and organizes them into distinct stages. Furthermore, we build JurisMM, a large dataset with over 100,000 recent Chinese judicial records, including both text and multimodal video-text data, enabling comprehensive evaluation. Experiments on JurisMM and the benchmark LawBench validate our framework’s effectiveness. These results indicate that our framework is effective not only for LJP but also for a broader range of legal applications, offering new perspectives for the development of future legal methods and datasets.
arXiv:2601.12815v5 Announce Type: cross
Abstract: Legal Judgment Prediction (LJP) aims to predict the outcomes of legal cases based on factual descriptions, serving as a fundamental task to advance the development of legal systems. Traditional methods often rely on statistical analyses or role-based simulations but face challenges with multiple allegations, diverse evidence, and lack adaptability. In this paper, we introduce JurisMMA, a novel framework for LJP that effectively decomposes trial tasks, standardizes processes, and organizes them into distinct stages. Furthermore, we build JurisMM, a large dataset with over 100,000 recent Chinese judicial records, including both text and multimodal video-text data, enabling comprehensive evaluation. Experiments on JurisMM and the benchmark LawBench validate our framework’s effectiveness. These results indicate that our framework is effective not only for LJP but also for a broader range of legal applications, offering new perspectives for the development of future legal methods and datasets. Read More
No One Size Fits All: QueryBandits for Hallucination Mitigationcs.AI updates on arXiv.org arXiv:2602.20332v1 Announce Type: cross
Abstract: Advanced reasoning capabilities in Large Language Models (LLMs) have led to more frequent hallucinations; yet most mitigation work focuses on open-source models for post-hoc detection and parameter editing. The dearth of studies focusing on hallucinations in closed-source models is especially concerning, as they constitute the vast majority of models in institutional deployments. We introduce QueryBandits, a model-agnostic contextual bandit framework that adaptively learns online to select the optimal query-rewrite strategy by leveraging an empirically validated and calibrated reward function. Across 16 QA scenarios, our top QueryBandit (Thompson Sampling) achieves an 87.5% win rate over a No-Rewrite baseline and outperforms zero-shot static policies (e.g., Paraphrase or Expand) by 42.6% and 60.3%, respectively. Moreover, all contextual bandits outperform vanilla bandits across all datasets, with higher feature variance coinciding with greater variance in arm selection. This substantiates our finding that there is no single rewrite policy optimal for all queries. We also discover that certain static policies incur higher cumulative regret than No-Rewrite, indicating that an inflexible query-rewriting policy can worsen hallucinations. Thus, learning an online policy over semantic features with QueryBandits can shift model behavior purely through forward-pass mechanisms, enabling its use with closed-source models and bypassing the need for retraining or gradient-based adaptation.
arXiv:2602.20332v1 Announce Type: cross
Abstract: Advanced reasoning capabilities in Large Language Models (LLMs) have led to more frequent hallucinations; yet most mitigation work focuses on open-source models for post-hoc detection and parameter editing. The dearth of studies focusing on hallucinations in closed-source models is especially concerning, as they constitute the vast majority of models in institutional deployments. We introduce QueryBandits, a model-agnostic contextual bandit framework that adaptively learns online to select the optimal query-rewrite strategy by leveraging an empirically validated and calibrated reward function. Across 16 QA scenarios, our top QueryBandit (Thompson Sampling) achieves an 87.5% win rate over a No-Rewrite baseline and outperforms zero-shot static policies (e.g., Paraphrase or Expand) by 42.6% and 60.3%, respectively. Moreover, all contextual bandits outperform vanilla bandits across all datasets, with higher feature variance coinciding with greater variance in arm selection. This substantiates our finding that there is no single rewrite policy optimal for all queries. We also discover that certain static policies incur higher cumulative regret than No-Rewrite, indicating that an inflexible query-rewriting policy can worsen hallucinations. Thus, learning an online policy over semantic features with QueryBandits can shift model behavior purely through forward-pass mechanisms, enabling its use with closed-source models and bypassing the need for retraining or gradient-based adaptation. Read More
Autonomous AI and Ownership Rulescs.AI updates on arXiv.org arXiv:2602.20169v1 Announce Type: cross
Abstract: This Article examines the circumstances in which AI-generated outputs remain linked to their creators and the points at which they lose that connection, whether through accident, deliberate design, or emergent behavior. In cases where AI is traceable to an originator, accession doctrine provides an efficient means of assigning ownership, preserving investment incentives while maintaining accountability. When AI becomes untraceable — whether through carelessness, deliberate obfuscation, or emergent behavior — first possession rules can encourage reallocation to new custodians who are incentivized to integrate AI into productive use. The analysis further explores strategic ownership dissolution, where autonomous AI is intentionally designed to evade attribution, creating opportunities for tax arbitrage and regulatory avoidance. To counteract these inefficiencies, bounty systems, private incentives, and government subsidies are proposed as mechanisms to encourage AI capture and prevent ownerless AI from distorting markets.
arXiv:2602.20169v1 Announce Type: cross
Abstract: This Article examines the circumstances in which AI-generated outputs remain linked to their creators and the points at which they lose that connection, whether through accident, deliberate design, or emergent behavior. In cases where AI is traceable to an originator, accession doctrine provides an efficient means of assigning ownership, preserving investment incentives while maintaining accountability. When AI becomes untraceable — whether through carelessness, deliberate obfuscation, or emergent behavior — first possession rules can encourage reallocation to new custodians who are incentivized to integrate AI into productive use. The analysis further explores strategic ownership dissolution, where autonomous AI is intentionally designed to evade attribution, creating opportunities for tax arbitrage and regulatory avoidance. To counteract these inefficiencies, bounty systems, private incentives, and government subsidies are proposed as mechanisms to encourage AI capture and prevent ownerless AI from distorting markets. Read More
Optimizing Token Generation in PyTorch Decoder ModelsTowards Data Science Hiding host-device synchronization via CUDA stream interleaving
The post Optimizing Token Generation in PyTorch Decoder Models appeared first on Towards Data Science.
Hiding host-device synchronization via CUDA stream interleaving
The post Optimizing Token Generation in PyTorch Decoder Models appeared first on Towards Data Science. Read More
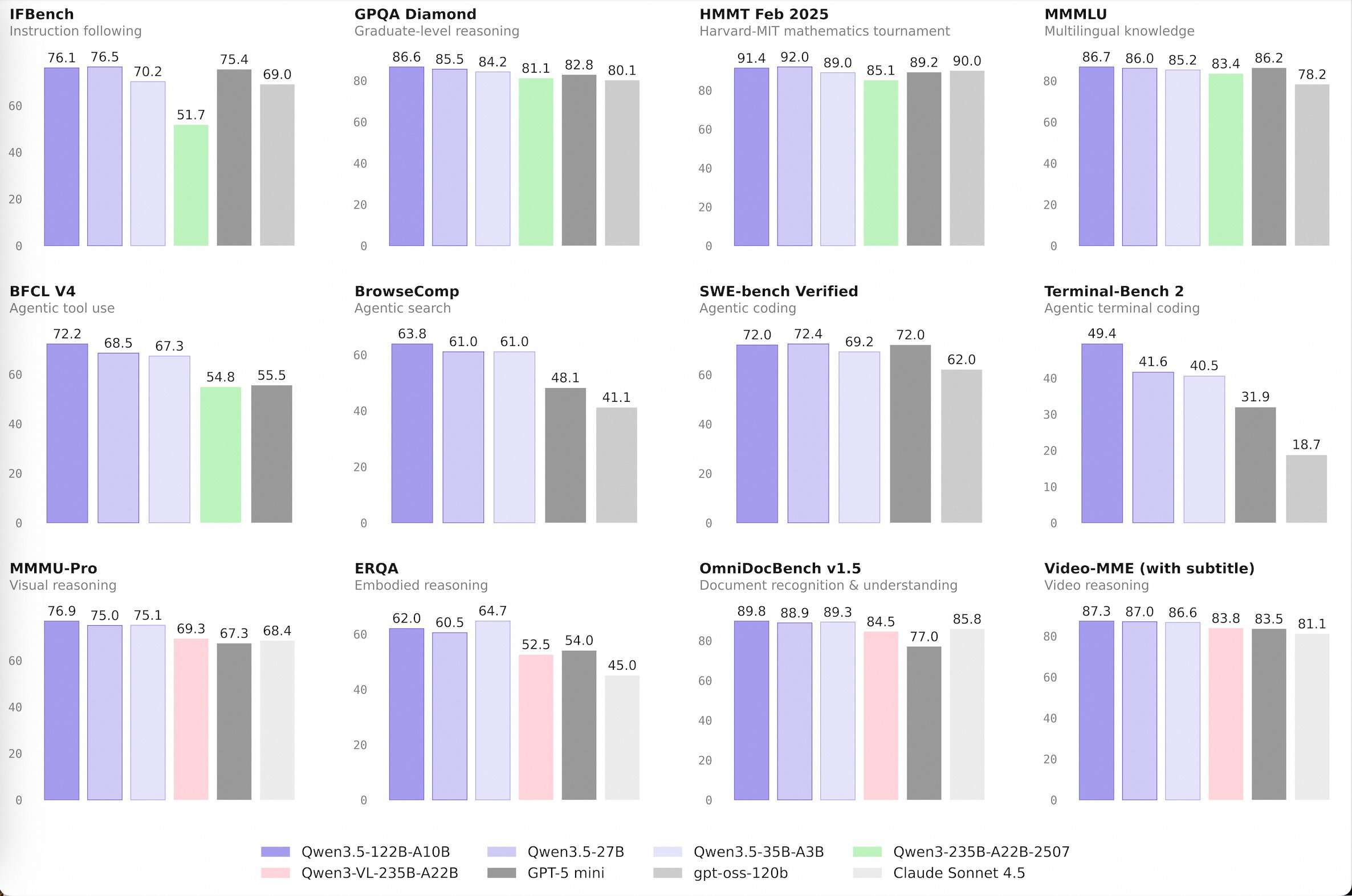
Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models are SmarterMarkTechPost The development of large language models (LLMs) has been defined by the pursuit of raw scale. While increasing parameter counts into the trillions initially drove performance gains, it also introduced significant infrastructure overhead and diminishing marginal utility. The release of the Qwen 3.5 Medium Model Series signals a shift in Alibaba’s Qwen approach, prioritizing architectural
The post Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models are Smarter appeared first on MarkTechPost.
The development of large language models (LLMs) has been defined by the pursuit of raw scale. While increasing parameter counts into the trillions initially drove performance gains, it also introduced significant infrastructure overhead and diminishing marginal utility. The release of the Qwen 3.5 Medium Model Series signals a shift in Alibaba’s Qwen approach, prioritizing architectural
The post Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models are Smarter appeared first on MarkTechPost. Read More
Decisioning at the Edge: Policy Matching at ScaleTowards Data Science Policy-to-Agency Optimization with PuLP
The post Decisioning at the Edge: Policy Matching at Scale appeared first on Towards Data Science.
Policy-to-Agency Optimization with PuLP
The post Decisioning at the Edge: Policy Matching at Scale appeared first on Towards Data Science. Read More
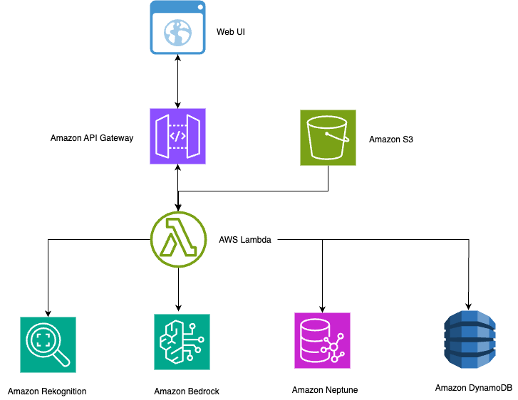
Build an intelligent photo search using Amazon Rekognition, Amazon Neptune, and Amazon BedrockArtificial Intelligence In this post, we show you how to build a comprehensive photo search system using the AWS Cloud Development Kit (AWS CDK) that integrates Amazon Rekognition for face and object detection, Amazon Neptune for relationship mapping, and Amazon Bedrock for AI-powered captioning.
In this post, we show you how to build a comprehensive photo search system using the AWS Cloud Development Kit (AWS CDK) that integrates Amazon Rekognition for face and object detection, Amazon Neptune for relationship mapping, and Amazon Bedrock for AI-powered captioning. Read More

Grounded PRD Generation with NotebookLMKDnuggets Leverage NotebookLM’s features to turn raw, sometimes chaotic information into a grounded PRD in a matter of minutes.
Leverage NotebookLM’s features to turn raw, sometimes chaotic information into a grounded PRD in a matter of minutes. Read More

Anthropic: Claude faces ‘industrial-scale’ AI model distillationAI News Anthropic has detailed three “industrial-scale” AI model distillation campaigns by overseas labs designed to extract abilities from Claude. These competitors generated over 16 million exchanges using approximately 24,000 deceptive accounts. Their goal was to acquire proprietary logic to improve their competing platforms. The extraction technique, known as distillation, involves training a weaker system on the
The post Anthropic: Claude faces ‘industrial-scale’ AI model distillation appeared first on AI News.
Anthropic has detailed three “industrial-scale” AI model distillation campaigns by overseas labs designed to extract abilities from Claude. These competitors generated over 16 million exchanges using approximately 24,000 deceptive accounts. Their goal was to acquire proprietary logic to improve their competing platforms. The extraction technique, known as distillation, involves training a weaker system on the
The post Anthropic: Claude faces ‘industrial-scale’ AI model distillation appeared first on AI News. Read More

Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobsArtificial Intelligence In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads. Read More