
LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI ModelsTowards Data Science A step-by-step guide to building AI quality control using large language models
The post LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI Models appeared first on Towards Data Science.
A step-by-step guide to building AI quality control using large language models
The post LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI Models appeared first on Towards Data Science. Read More
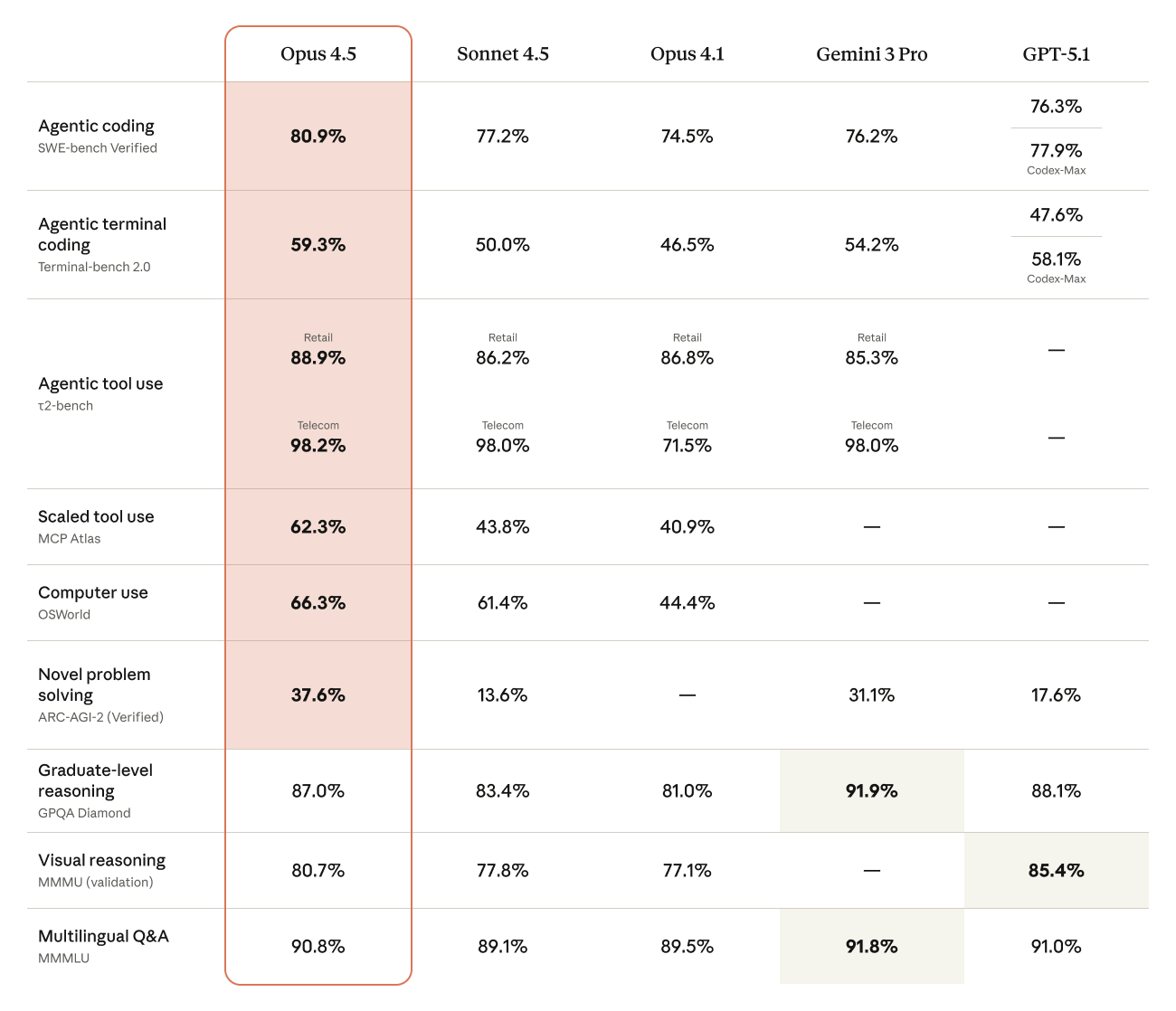
Claude Opus 4.5 now in Amazon BedrockArtificial Intelligence Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock.
Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock. Read More

ZAYA1: AI model using AMD GPUs for training hits milestoneAI News Zyphra, AMD, and IBM spent a year testing whether AMD’s GPUs and platform can support large-scale AI model training, and the result is ZAYA1. In partnership, the three companies trained ZAYA1 – described as the first major Mixture-of-Experts foundation model built entirely on AMD GPUs and networking – which they see as proof that the
The post ZAYA1: AI model using AMD GPUs for training hits milestone appeared first on AI News.
Zyphra, AMD, and IBM spent a year testing whether AMD’s GPUs and platform can support large-scale AI model training, and the result is ZAYA1. In partnership, the three companies trained ZAYA1 – described as the first major Mixture-of-Experts foundation model built entirely on AMD GPUs and networking – which they see as proof that the
The post ZAYA1: AI model using AMD GPUs for training hits milestone appeared first on AI News. Read More

My Honest Review on Abacus AI: ChatLLM, DeepAgent & EnterpriseKDnuggets Abacus AI offers the world’s first professional and enterprise AI Super Assistant. It’s an all-in-one AI platform for the top language, image, voic,e and video models along with all the tooling and infrastructure to support them. Abacus can connect to all YOUR data and apply AI to automate work.
Abacus AI offers the world’s first professional and enterprise AI Super Assistant. It’s an all-in-one AI platform for the top language, image, voic,e and video models along with all the tooling and infrastructure to support them. Abacus can connect to all YOUR data and apply AI to automate work. Read More
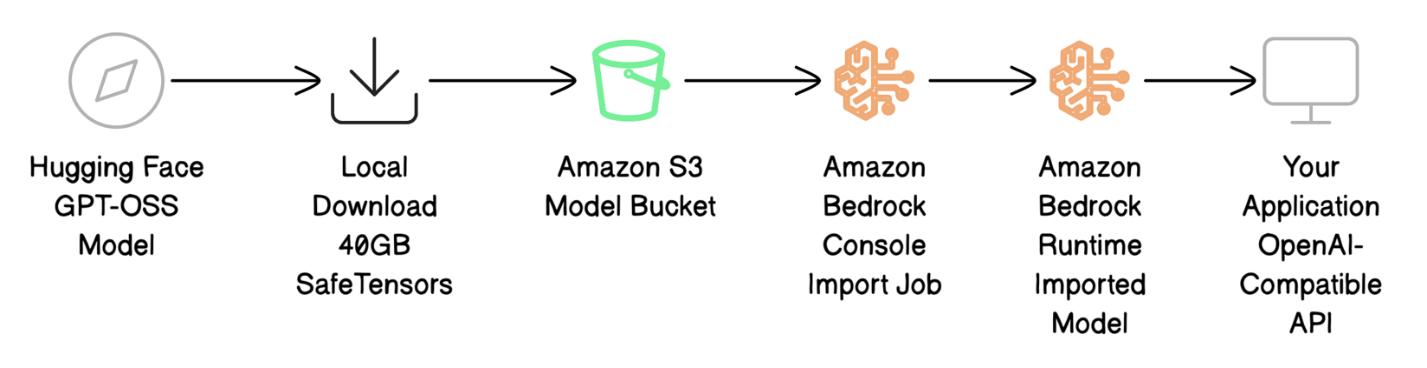
Deploy GPT-OSS models with Amazon Bedrock Custom Model ImportArtificial Intelligence In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications.
In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications. Read More

Lux + Pandas: Auto-Visualizations for Lazy AnalystsKDnuggets Why write 10 lines of matplotlib code when Lux can show you what you need in one click?
Why write 10 lines of matplotlib code when Lux can show you what you need in one click? Read More

Make.com Automations for Saving Time as a Data ProfessionalKDnuggets Make.com enables data professionals to automate tedious tasks, such as data collection and reporting, without coding, saving hours weekly and enhancing accuracy.
Make.com enables data professionals to automate tedious tasks, such as data collection and reporting, without coding, saving hours weekly and enhancing accuracy. Read More

Accelerate generative AI innovation in Canada with Amazon Bedrock cross-Region inferenceArtificial Intelligence We are excited to announce that customers in Canada can now access advanced foundation models including Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5 on Amazon Bedrock through cross-Region inference (CRIS). This post explores how Canadian organizations can use cross-Region inference profiles from the Canada (Central) Region to access the latest foundation models to accelerate AI initiatives. We will demonstrate how to get started with these new capabilities, provide guidance for migrating from older models, and share recommended practices for quota management.
We are excited to announce that customers in Canada can now access advanced foundation models including Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5 on Amazon Bedrock through cross-Region inference (CRIS). This post explores how Canadian organizations can use cross-Region inference profiles from the Canada (Central) Region to access the latest foundation models to accelerate AI initiatives. We will demonstrate how to get started with these new capabilities, provide guidance for migrating from older models, and share recommended practices for quota management. Read More

How artificial intelligence can help achieve a clean energy futureMIT News – Machine learning AI supports the clean energy transition as it manages power grid operations, helps plan infrastructure investments, guides development of novel materials, and more.
AI supports the clean energy transition as it manages power grid operations, helps plan infrastructure investments, guides development of novel materials, and more. Read More
Preventing Shortcut Learning in Medical Image Analysis through Intermediate Layer Knowledge Distillation from Specialist Teacherscs.AI updates on arXiv.org arXiv:2511.17421v1 Announce Type: cross
Abstract: Deep learning models are prone to learning shortcut solutions to problems using spuriously correlated yet irrelevant features of their training data. In high-risk applications such as medical image analysis, this phenomenon may prevent models from using clinically meaningful features when making predictions, potentially leading to poor robustness and harm to patients. We demonstrate that different types of shortcuts (those that are diffuse and spread throughout the image, as well as those that are localized to specific areas) manifest distinctly across network layers and can, therefore, be more effectively targeted through mitigation strategies that target the intermediate layers. We propose a novel knowledge distillation framework that leverages a teacher network fine-tuned on a small subset of task-relevant data to mitigate shortcut learning in a student network trained on a large dataset corrupted with a bias feature. Through extensive experiments on CheXpert, ISIC 2017, and SimBA datasets using various architectures (ResNet-18, AlexNet, DenseNet-121, and 3D CNNs), we demonstrate consistent improvements over traditional Empirical Risk Minimization, augmentation-based bias-mitigation, and group-based bias-mitigation approaches. In many cases, we achieve comparable performance with a baseline model trained on bias-free data, even on out-of-distribution test data. Our results demonstrate the practical applicability of our approach to real-world medical imaging scenarios where bias annotations are limited and shortcut features are difficult to identify a priori.
arXiv:2511.17421v1 Announce Type: cross
Abstract: Deep learning models are prone to learning shortcut solutions to problems using spuriously correlated yet irrelevant features of their training data. In high-risk applications such as medical image analysis, this phenomenon may prevent models from using clinically meaningful features when making predictions, potentially leading to poor robustness and harm to patients. We demonstrate that different types of shortcuts (those that are diffuse and spread throughout the image, as well as those that are localized to specific areas) manifest distinctly across network layers and can, therefore, be more effectively targeted through mitigation strategies that target the intermediate layers. We propose a novel knowledge distillation framework that leverages a teacher network fine-tuned on a small subset of task-relevant data to mitigate shortcut learning in a student network trained on a large dataset corrupted with a bias feature. Through extensive experiments on CheXpert, ISIC 2017, and SimBA datasets using various architectures (ResNet-18, AlexNet, DenseNet-121, and 3D CNNs), we demonstrate consistent improvements over traditional Empirical Risk Minimization, augmentation-based bias-mitigation, and group-based bias-mitigation approaches. In many cases, we achieve comparable performance with a baseline model trained on bias-free data, even on out-of-distribution test data. Our results demonstrate the practical applicability of our approach to real-world medical imaging scenarios where bias annotations are limited and shortcut features are difficult to identify a priori. Read More