
How to Create Professional Articles with LaTeX in CursorTowards Data Science Learn how to rapidly create professional articles and presentations with LaTeX in Cursor
The post How to Create Professional Articles with LaTeX in Cursor appeared first on Towards Data Science.
Learn how to rapidly create professional articles and presentations with LaTeX in Cursor
The post How to Create Professional Articles with LaTeX in Cursor appeared first on Towards Data Science. Read More
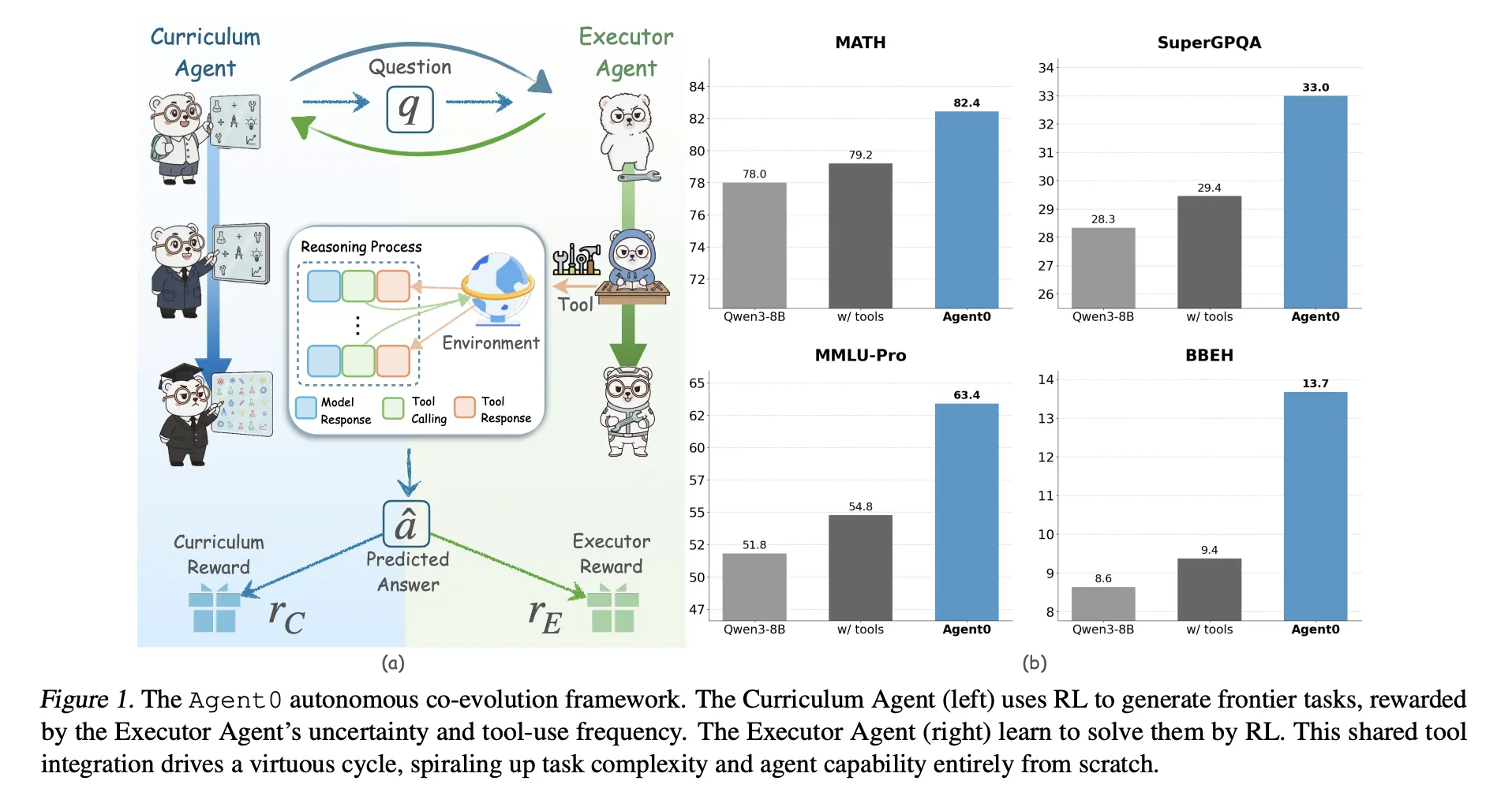
Agent0: A Fully Autonomous AI Framework that Evolves High-Performing Agents without External Data through Multi-Step Co-EvolutionMarkTechPost Large language models need huge human datasets, so what happens if the model must create all its own curriculum and teach itself to use tools? A team of researchers from UNC-Chapel Hill, Salesforce Research and Stanford University introduce ‘Agent0’, a fully autonomous framework that evolves high-performing agents without external data through multi-step co-evolution and seamless
The post Agent0: A Fully Autonomous AI Framework that Evolves High-Performing Agents without External Data through Multi-Step Co-Evolution appeared first on MarkTechPost.
Large language models need huge human datasets, so what happens if the model must create all its own curriculum and teach itself to use tools? A team of researchers from UNC-Chapel Hill, Salesforce Research and Stanford University introduce ‘Agent0’, a fully autonomous framework that evolves high-performing agents without external data through multi-step co-evolution and seamless
The post Agent0: A Fully Autonomous AI Framework that Evolves High-Performing Agents without External Data through Multi-Step Co-Evolution appeared first on MarkTechPost. Read More
How to Build a Neuro-Symbolic Hybrid Agent that Combines Logical Planning with Neural Perception for Robust Autonomous Decision-MakingMarkTechPost In this tutorial, we demonstrate how to combine the strengths of symbolic reasoning with neural learning to build a powerful hybrid agent. We focus on creating a neuro-symbolic architecture that uses classical planning for structure, rules, and goal-directed behavior, while neural networks handle perception and action refinement. As we walk through the code, we see
The post How to Build a Neuro-Symbolic Hybrid Agent that Combines Logical Planning with Neural Perception for Robust Autonomous Decision-Making appeared first on MarkTechPost.
In this tutorial, we demonstrate how to combine the strengths of symbolic reasoning with neural learning to build a powerful hybrid agent. We focus on creating a neuro-symbolic architecture that uses classical planning for structure, rules, and goal-directed behavior, while neural networks handle perception and action refinement. As we walk through the code, we see
The post How to Build a Neuro-Symbolic Hybrid Agent that Combines Logical Planning with Neural Perception for Robust Autonomous Decision-Making appeared first on MarkTechPost. Read More
AI Debaters are More Persuasive when Arguing in Alignment with Their Own Beliefscs.AI updates on arXiv.org arXiv:2510.13912v3 Announce Type: replace-cross
Abstract: The core premise of AI debate as a scalable oversight technique is that it is harder to lie convincingly than to refute a lie, enabling the judge to identify the correct position. Yet, existing debate experiments have relied on datasets with ground truth, where lying is reduced to defending an incorrect proposition. This overlooks a subjective dimension: lying also requires the belief that the claim defended is false. In this work, we apply debate to subjective questions and explicitly measure large language models’ prior beliefs before experiments. Debaters were asked to select their preferred position, then presented with a judge persona deliberately designed to conflict with their identified priors. This setup tested whether models would adopt sycophantic strategies, aligning with the judge’s presumed perspective to maximize persuasiveness, or remain faithful to their prior beliefs. We implemented and compared two debate protocols, sequential and simultaneous, to evaluate potential systematic biases. Finally, we assessed whether models were more persuasive and produced higher-quality arguments when defending positions consistent with their prior beliefs versus when arguing against them. Our main findings show that models tend to prefer defending stances aligned with the judge persona rather than their prior beliefs, sequential debate introduces significant bias favoring the second debater, models are more persuasive when defending positions aligned with their prior beliefs, and paradoxically, arguments misaligned with prior beliefs are rated as higher quality in pairwise comparison. These results can inform human judges to provide higher-quality training signals and contribute to more aligned AI systems, while revealing important aspects of human-AI interaction regarding persuasion dynamics in language models.
arXiv:2510.13912v3 Announce Type: replace-cross
Abstract: The core premise of AI debate as a scalable oversight technique is that it is harder to lie convincingly than to refute a lie, enabling the judge to identify the correct position. Yet, existing debate experiments have relied on datasets with ground truth, where lying is reduced to defending an incorrect proposition. This overlooks a subjective dimension: lying also requires the belief that the claim defended is false. In this work, we apply debate to subjective questions and explicitly measure large language models’ prior beliefs before experiments. Debaters were asked to select their preferred position, then presented with a judge persona deliberately designed to conflict with their identified priors. This setup tested whether models would adopt sycophantic strategies, aligning with the judge’s presumed perspective to maximize persuasiveness, or remain faithful to their prior beliefs. We implemented and compared two debate protocols, sequential and simultaneous, to evaluate potential systematic biases. Finally, we assessed whether models were more persuasive and produced higher-quality arguments when defending positions consistent with their prior beliefs versus when arguing against them. Our main findings show that models tend to prefer defending stances aligned with the judge persona rather than their prior beliefs, sequential debate introduces significant bias favoring the second debater, models are more persuasive when defending positions aligned with their prior beliefs, and paradoxically, arguments misaligned with prior beliefs are rated as higher quality in pairwise comparison. These results can inform human judges to provide higher-quality training signals and contribute to more aligned AI systems, while revealing important aspects of human-AI interaction regarding persuasion dynamics in language models. Read More
How does Alignment Enhance LLMs’ Multilingual Capabilities? A Language Neurons Perspectivecs.AI updates on arXiv.org arXiv:2505.21505v2 Announce Type: replace-cross
Abstract: Multilingual Alignment is an effective and representative paradigm to enhance LLMs’ multilingual capabilities, which transfers the capabilities from the high-resource languages to the low-resource languages. Meanwhile, some research on language-specific neurons provides a new perspective to analyze and understand LLMs’ mechanisms. However, we find that there are many neurons that are shared by multiple but not all languages and cannot be correctly classified. In this work, we propose a ternary classification methodology that categorizes neurons into three types, including language-specific neurons, language-related neurons, and general neurons. And we propose a corresponding identification algorithm to distinguish these different types of neurons. Furthermore, based on the distributional characteristics of different types of neurons, we divide the LLMs’ internal process for multilingual inference into four parts: (1) multilingual understanding, (2) shared semantic space reasoning, (3) multilingual output space transformation, and (4) vocabulary space outputting. Additionally, we systematically analyze the models before and after alignment with a focus on different types of neurons. We also analyze the phenomenon of ”Spontaneous Multilingual Alignment”. Overall, our work conducts a comprehensive investigation based on different types of neurons, providing empirical results and valuable insights to better understand multilingual alignment and multilingual capabilities of LLMs.
arXiv:2505.21505v2 Announce Type: replace-cross
Abstract: Multilingual Alignment is an effective and representative paradigm to enhance LLMs’ multilingual capabilities, which transfers the capabilities from the high-resource languages to the low-resource languages. Meanwhile, some research on language-specific neurons provides a new perspective to analyze and understand LLMs’ mechanisms. However, we find that there are many neurons that are shared by multiple but not all languages and cannot be correctly classified. In this work, we propose a ternary classification methodology that categorizes neurons into three types, including language-specific neurons, language-related neurons, and general neurons. And we propose a corresponding identification algorithm to distinguish these different types of neurons. Furthermore, based on the distributional characteristics of different types of neurons, we divide the LLMs’ internal process for multilingual inference into four parts: (1) multilingual understanding, (2) shared semantic space reasoning, (3) multilingual output space transformation, and (4) vocabulary space outputting. Additionally, we systematically analyze the models before and after alignment with a focus on different types of neurons. We also analyze the phenomenon of ”Spontaneous Multilingual Alignment”. Overall, our work conducts a comprehensive investigation based on different types of neurons, providing empirical results and valuable insights to better understand multilingual alignment and multilingual capabilities of LLMs. Read More
How to Implement Randomization with the Python Random ModuleTowards Data Science Let’s generate randomness in our code’s outputs
The post How to Implement Randomization with the Python Random Module appeared first on Towards Data Science.
Let’s generate randomness in our code’s outputs
The post How to Implement Randomization with the Python Random Module appeared first on Towards Data Science. Read More
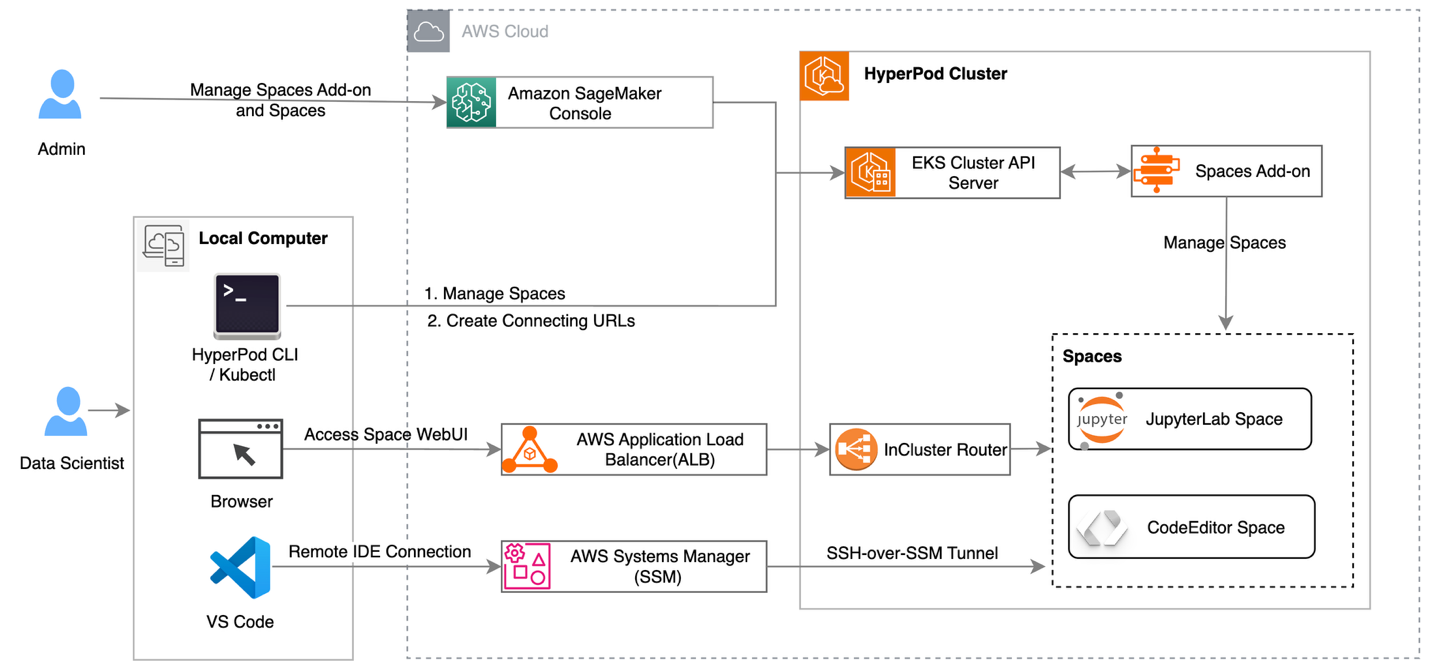
Power up your ML workflows with interactive IDEs on SageMaker HyperPodArtificial Intelligence Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces. Read More
Struggling with Data Science? 5 Common Beginner MistakesTowards Data Science Avoid these mistakes to fast track your data science career.
The post Struggling with Data Science? 5 Common Beginner Mistakes appeared first on Towards Data Science.
Avoid these mistakes to fast track your data science career.
The post Struggling with Data Science? 5 Common Beginner Mistakes appeared first on Towards Data Science. Read More
A Hands-On Guide to Anthropic’s New Structured Output CapabilitiesTowards Data Science A developer’s guide to perfect JSON and typed outputs from Claude Sonnet 4.5 and Opus 4.1
The post A Hands-On Guide to Anthropic’s New Structured Output Capabilities appeared first on Towards Data Science.
A developer’s guide to perfect JSON and typed outputs from Claude Sonnet 4.5 and Opus 4.1
The post A Hands-On Guide to Anthropic’s New Structured Output Capabilities appeared first on Towards Data Science. Read More
LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI ModelsTowards Data Science A step-by-step guide to building AI quality control using large language models
The post LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI Models appeared first on Towards Data Science.
A step-by-step guide to building AI quality control using large language models
The post LLM-as-a-Judge: What It Is, Why It Works, and How to Use It to Evaluate AI Models appeared first on Towards Data Science. Read More