
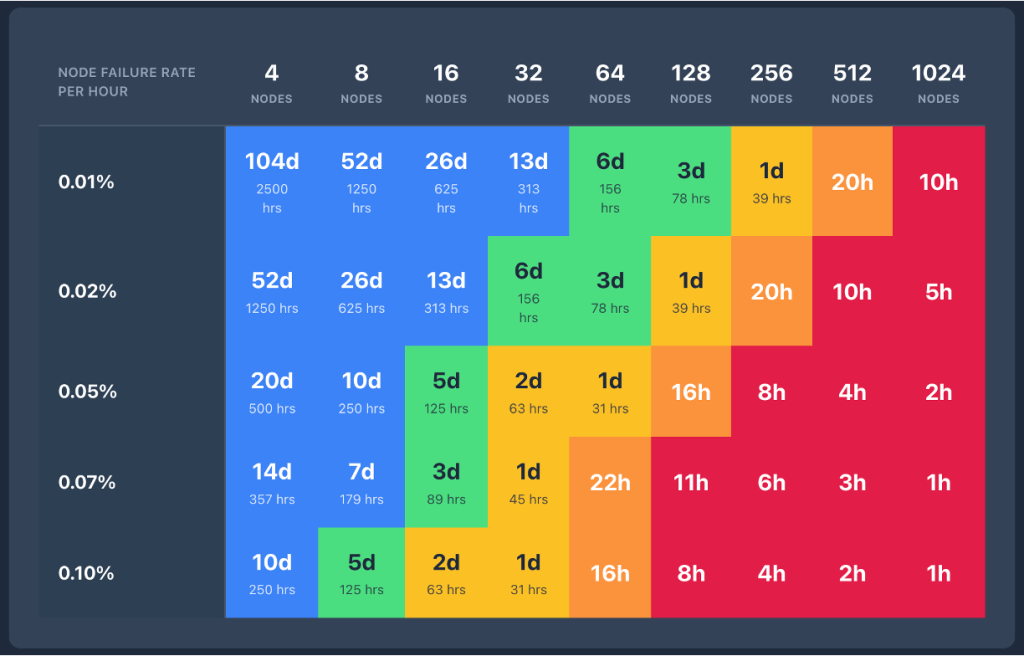
Checkpointless training on Amazon SageMaker HyperPod: Production-scale training with faster fault recoveryArtificial Intelligence In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators.
In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators. Read More

The Machine Learning “Advent Calendar” Day 15: SVM in ExcelTowards Data Science Instead of starting with margins and geometry, this article builds the Support Vector Machine step by step from familiar models. By changing the loss function and reusing regularization, SVM appears naturally as a linear classifier trained by optimization. This perspective unifies logistic regression, SVM, and other linear models into a single, coherent framework.
The post The Machine Learning “Advent Calendar” Day 15: SVM in Excel appeared first on Towards Data Science.
Instead of starting with margins and geometry, this article builds the Support Vector Machine step by step from familiar models. By changing the loss function and reusing regularization, SVM appears naturally as a linear classifier trained by optimization. This perspective unifies logistic regression, SVM, and other linear models into a single, coherent framework.
The post The Machine Learning “Advent Calendar” Day 15: SVM in Excel appeared first on Towards Data Science. Read More
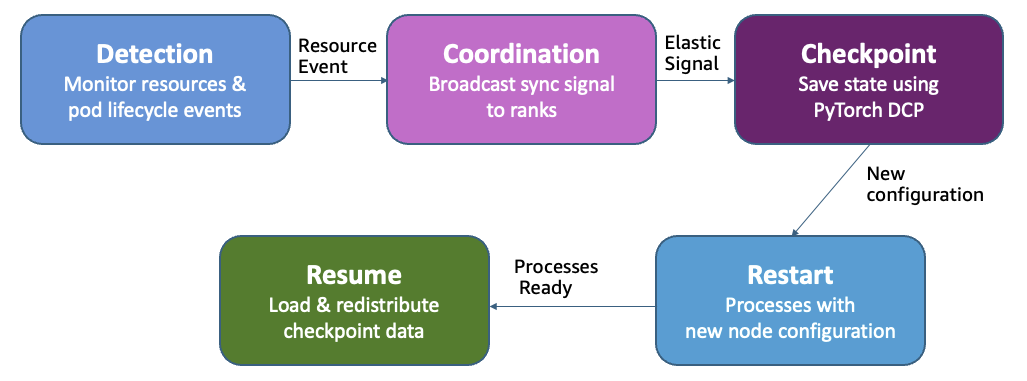
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPodArtificial Intelligence Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention.
Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention. Read More

A new malware-as-a-service (MaaS) information stealer named SantaStealer is being advertised on Telegram and hacker forums as operating in memory to avoid file-based detection. […] Read More

Two Apple zero-day vulnerabilities discovered this month have overlap with another mysterious zero-day flaw Google patched last week. Read More
Google is discontinuing its “dark web report” security tool, stating that it wants to focus on other tools it believes are more helpful. […] Read More
Japanese e-commerce giant Askul Corporation has confirmed that RansomHouse hackers stole around 740,000 customer records in the ransomware attack it suffered in October. […] Read More
700Credit, a U.S.-based financial services and fintech company, will start notifying more than 5.8 million people that their personal information has been exposed in a data breach incident. […] Read More
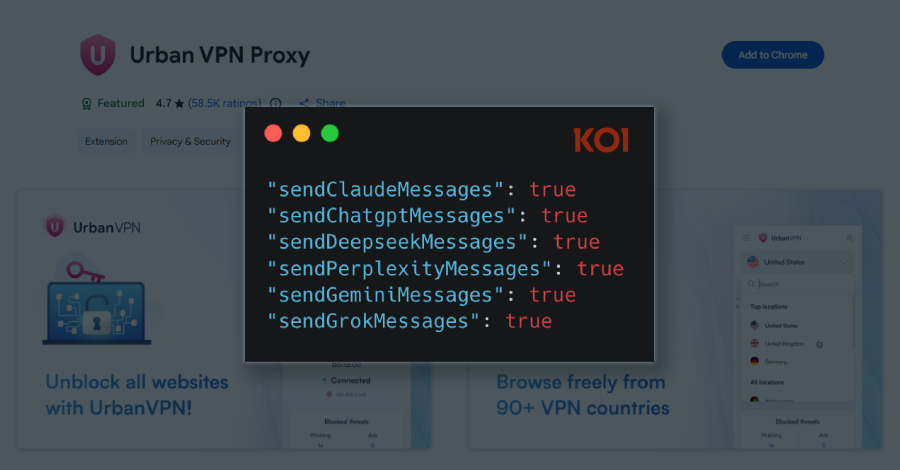
A Google Chrome extension with a “Featured” badge and six million users has been observed silently gathering every prompt entered by users into artificial intelligence (AI)-powered chatbots like OpenAI ChatGPT, Anthropic Claude, Microsoft Copilot, DeepSeek, Google Gemini, xAI Grok, Meta AI, and Perplexity. The extension in question is Urban VPN Proxy, which has a 4.7 […]
Users accessing the SoundCloud audio streaming platform through a virtual private network (VPN) connection are denied access to the service and see a 403 ‘forbidden’ error. […] Read More
