

Geospatial exploratory data analysis with GeoPandas and DuckDBTowards Data Science In this article, I’ll show you how to use two popular Python libraries to carry out some geospatial analysis of traffic accident data within the UK. I was a relatively early adopter of DuckDB, the fast OLAP database, after it became available, but only recently realised that, through an extension, it offered a large number
The post Geospatial exploratory data analysis with GeoPandas and DuckDB appeared first on Towards Data Science.
In this article, I’ll show you how to use two popular Python libraries to carry out some geospatial analysis of traffic accident data within the UK. I was a relatively early adopter of DuckDB, the fast OLAP database, after it became available, but only recently realised that, through an extension, it offered a large number
The post Geospatial exploratory data analysis with GeoPandas and DuckDB appeared first on Towards Data Science. Read More
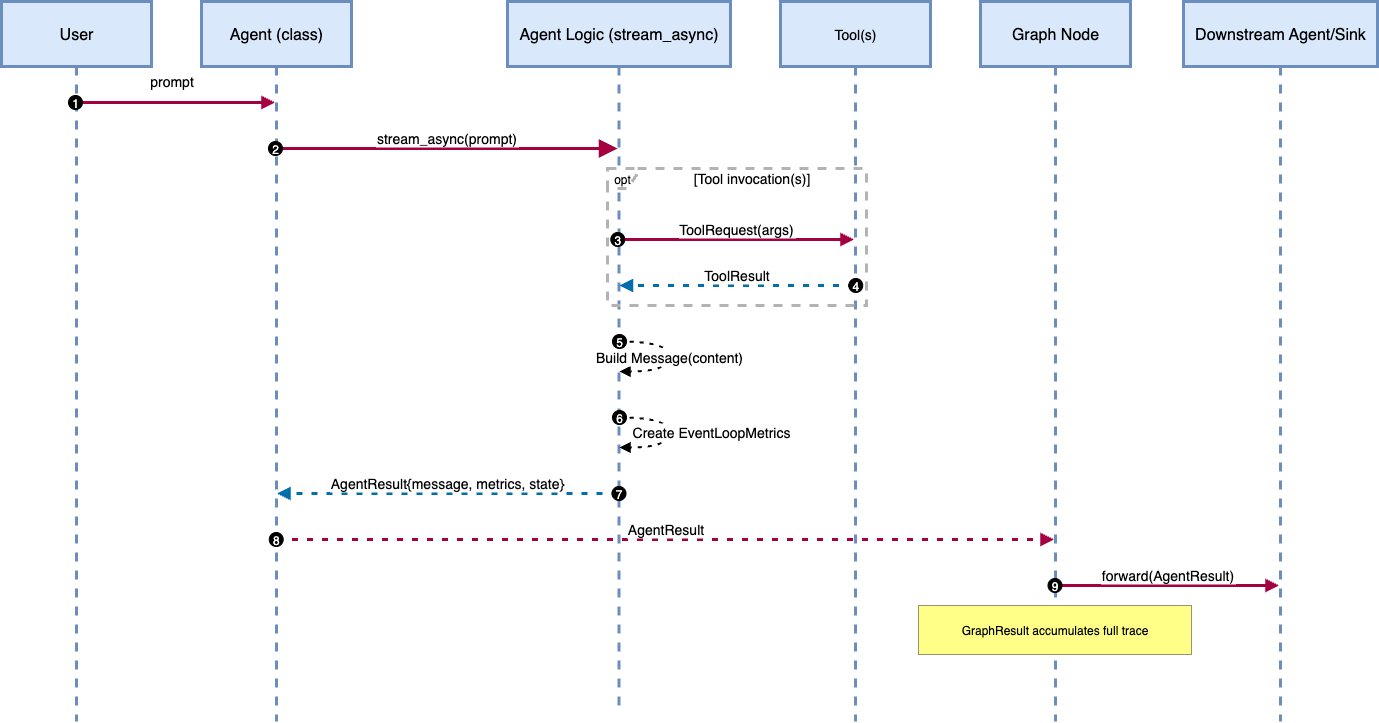
Customize agent workflows with advanced orchestration techniques using Strands AgentsArtificial Intelligence In this post, we explore two powerful orchestration patterns implemented with Strands Agents. Using a common set of travel planning tools, we demonstrate how different orchestration strategies can solve the same problem through distinct reasoning approaches,
In this post, we explore two powerful orchestration patterns implemented with Strands Agents. Using a common set of travel planning tools, we demonstrate how different orchestration strategies can solve the same problem through distinct reasoning approaches, Read More
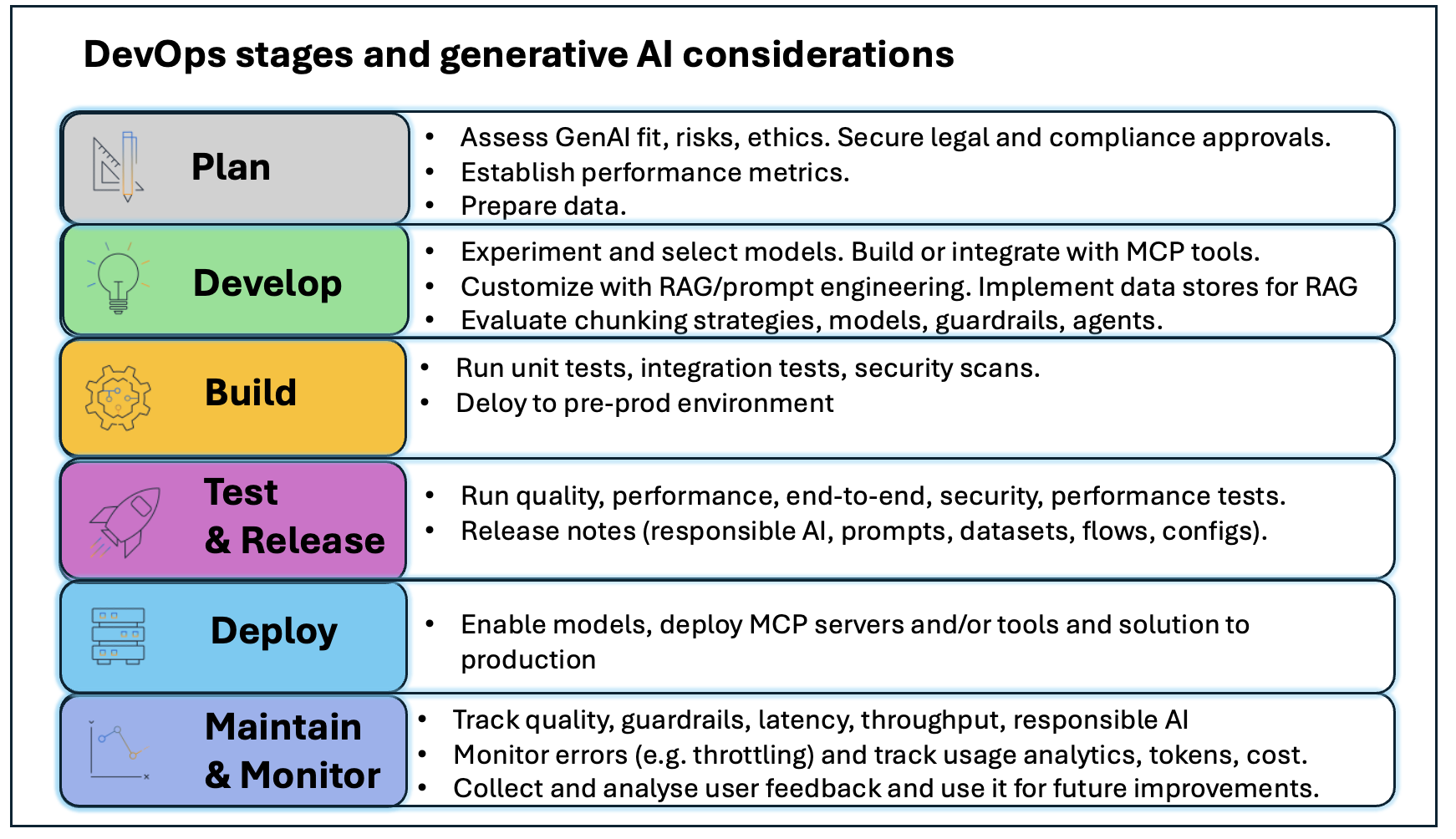
Operationalize generative AI workloads and scale to hundreds of use cases with Amazon Bedrock – Part 1: GenAIOpsArtificial Intelligence In this first part of our two-part series, you’ll learn how to evolve your existing DevOps architecture for generative AI workloads and implement GenAIOps practices. We’ll showcase practical implementation strategies for different generative AI adoption levels, focusing on consuming foundation models.
In this first part of our two-part series, you’ll learn how to evolve your existing DevOps architecture for generative AI workloads and implement GenAIOps practices. We’ll showcase practical implementation strategies for different generative AI adoption levels, focusing on consuming foundation models. Read More
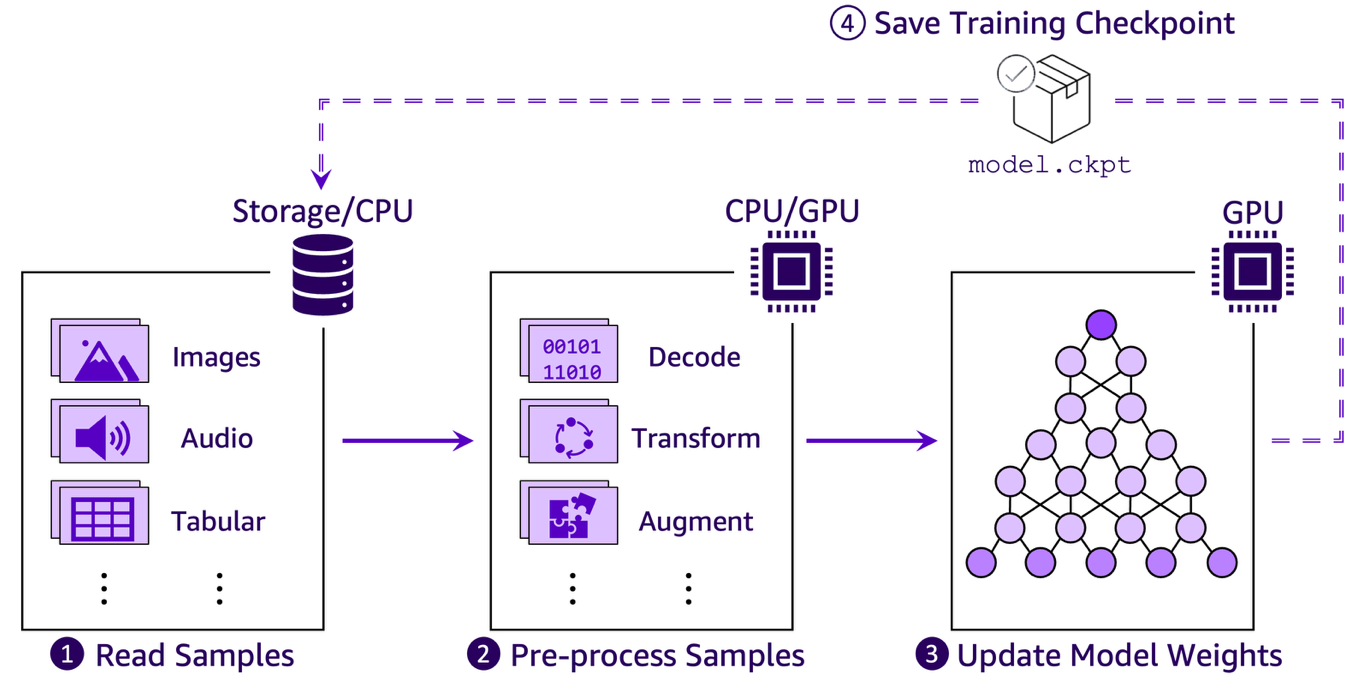
Applying data loading best practices for ML training with Amazon S3 clientsArtificial Intelligence In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets.
In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets. Read More

The Data Detox: Training Yourself for the Messy, Noisy, Real WorldKDnuggets In this article, we’ll use a real-life data project to explore four practical steps for preparing to deal with messy, real-life datasets.
In this article, we’ll use a real-life data project to explore four practical steps for preparing to deal with messy, real-life datasets. Read More
6 Technical Skills That Make You a Senior Data ScientistTowards Data Science Beyond writing code, these are the design-level decisions, trade-offs, and habits that quietly separate senior data scientists from everyone else.
The post 6 Technical Skills That Make You a Senior Data Scientist appeared first on Towards Data Science.
Beyond writing code, these are the design-level decisions, trade-offs, and habits that quietly separate senior data scientists from everyone else.
The post 6 Technical Skills That Make You a Senior Data Scientist appeared first on Towards Data Science. Read More

How Transformers Think: The Information Flow That Makes Language Models WorkKDnuggets Let’s uncover how transformer models sitting behind LLMs analyze input information like user prompts and how they generate coherent, meaningful, and relevant output text “word by word”.
Let’s uncover how transformer models sitting behind LLMs analyze input information like user prompts and how they generate coherent, meaningful, and relevant output text “word by word”. Read More
How to Design a Gemini-Powered Self-Correcting Multi-Agent AI System with Semantic Routing, Symbolic Guardrails, and Reflexive OrchestrationMarkTechPost In this tutorial, we explore how we design and run a full agentic AI orchestration pipeline powered by semantic routing, symbolic guardrails, and self-correction loops using Gemini. We walk through how we structure agents, dispatch tasks, enforce constraints, and refine outputs using a clean, modular architecture. As we progress through each snippet, we see how
The post How to Design a Gemini-Powered Self-Correcting Multi-Agent AI System with Semantic Routing, Symbolic Guardrails, and Reflexive Orchestration appeared first on MarkTechPost.
In this tutorial, we explore how we design and run a full agentic AI orchestration pipeline powered by semantic routing, symbolic guardrails, and self-correction loops using Gemini. We walk through how we structure agents, dispatch tasks, enforce constraints, and refine outputs using a clean, modular architecture. As we progress through each snippet, we see how
The post How to Design a Gemini-Powered Self-Correcting Multi-Agent AI System with Semantic Routing, Symbolic Guardrails, and Reflexive Orchestration appeared first on MarkTechPost. Read More

3 Questions: Using computation to study the world’s best single-celled chemistsMIT News – Machine learning Assistant Professor Yunha Hwang utilizes microbial genomes to examine the language of biology. Her appointment reflects MIT’s commitment to exploring the intersection of genetics research and AI.
Assistant Professor Yunha Hwang utilizes microbial genomes to examine the language of biology. Her appointment reflects MIT’s commitment to exploring the intersection of genetics research and AI. Read More
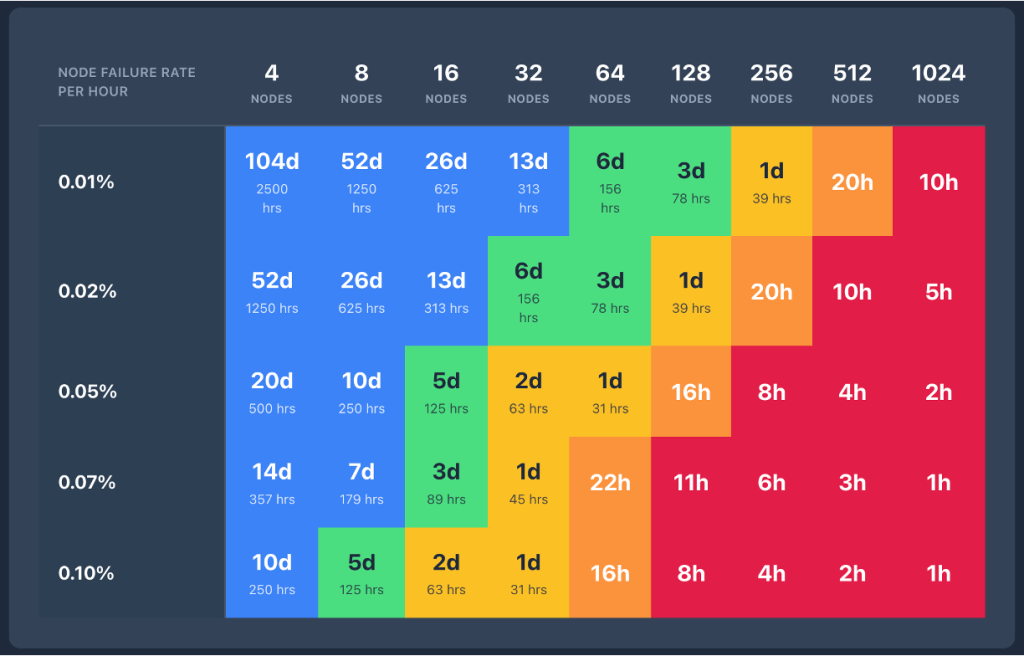
Checkpointless training on Amazon SageMaker HyperPod: Production-scale training with faster fault recoveryArtificial Intelligence In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators.
In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators. Read More
