

Hackers are exploiting critical-severity vulnerabilities affecting multiple Fortinet products to get unauthorized access to admin accounts and steal system configuration files. […] Read More
A new Android malware-as-a-service (MaaS) named Cellik is being advertised on underground cybercrime forums offering a robust set of capabilities that include the option to embed it in any app available on the Google Play Store. […] Read More
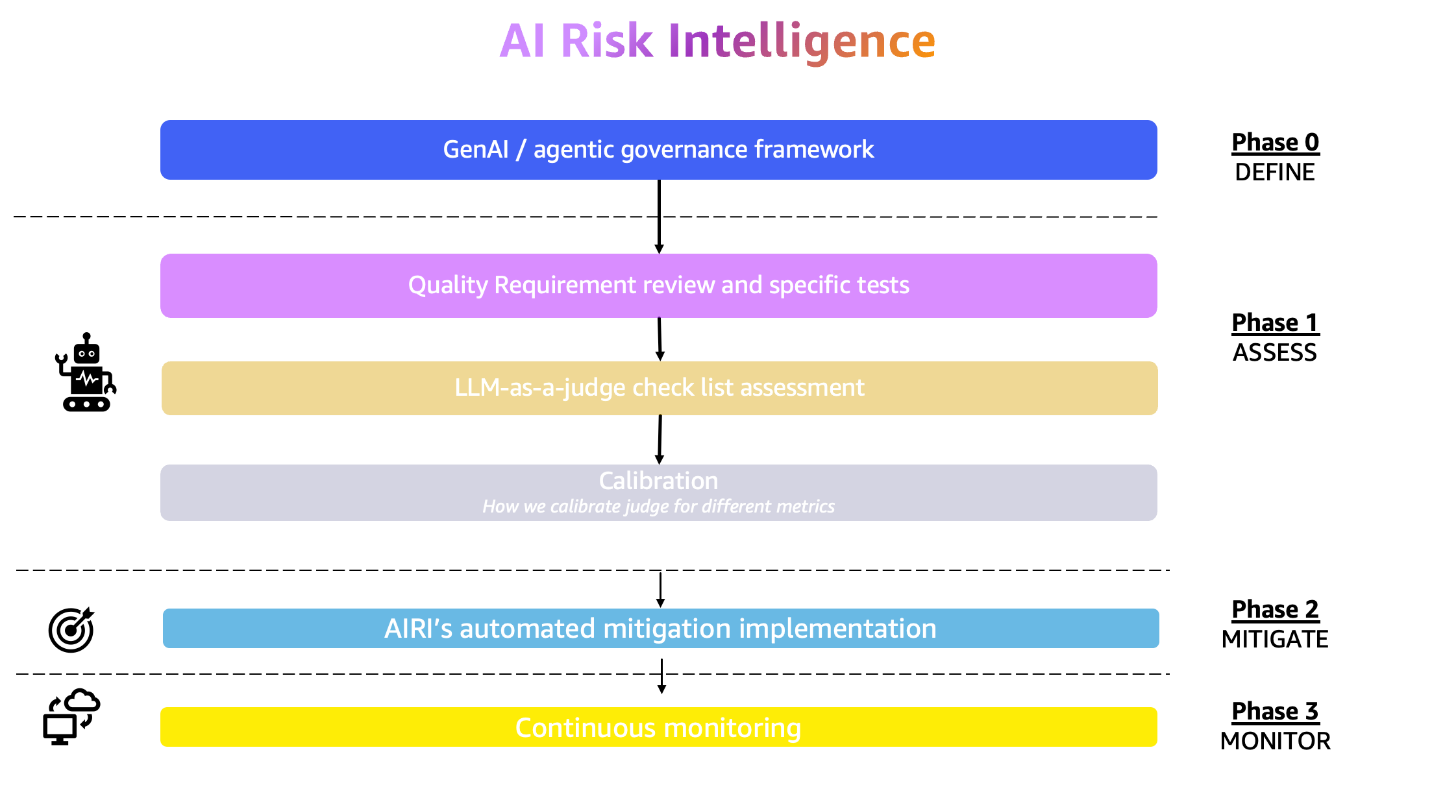
Governance by design: The essential guide for successful AI scalingArtificial Intelligence Picture this: Your enterprise has just deployed its first generative AI application. The initial results are promising, but as you plan to scale across departments, critical questions emerge. How will you enforce consistent security, prevent model bias, and maintain control as AI applications multiply?
Picture this: Your enterprise has just deployed its first generative AI application. The initial results are promising, but as you plan to scale across departments, critical questions emerge. How will you enforce consistent security, prevent model bias, and maintain control as AI applications multiply? Read More
How Tata Power CoE built a scalable AI-powered solar panel inspection solution with Amazon SageMaker AI and Amazon BedrockArtificial Intelligence In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end.
In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end. Read More
Unlocking video understanding with TwelveLabs Marengo on Amazon BedrockArtificial Intelligence In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery.
In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery. Read More

When (Not) to Use Vector DBTowards Data Science When indexing hurts more than it helps: how we realized our RAG use case needed a key-value store, not a vector database
The post When (Not) to Use Vector DB appeared first on Towards Data Science.
When indexing hurts more than it helps: how we realized our RAG use case needed a key-value store, not a vector database
The post When (Not) to Use Vector DB appeared first on Towards Data Science. Read More
What AI search tools mean for the future of SEO specialistsAI News AI search engines and generative AI tools are certainly transforming how people discover information online. Far from making SEO specialists obsolete, the shift highlights clearly why skilled human optimisers remain more important than ever. As generative AI search tools reshape the digital landscape, many wonder whether traditional SEO has reached the end. Despite AI’s growing
The post What AI search tools mean for the future of SEO specialists appeared first on AI News.
AI search engines and generative AI tools are certainly transforming how people discover information online. Far from making SEO specialists obsolete, the shift highlights clearly why skilled human optimisers remain more important than ever. As generative AI search tools reshape the digital landscape, many wonder whether traditional SEO has reached the end. Despite AI’s growing
The post What AI search tools mean for the future of SEO specialists appeared first on AI News. Read More
Separate Numbers and Text in One Column Using Power QueryTowards Data Science An Excel sheet with a column containing numbers and text? What a mess!
The post Separate Numbers and Text in One Column Using Power Query appeared first on Towards Data Science.
An Excel sheet with a column containing numbers and text? What a mess!
The post Separate Numbers and Text in One Column Using Power Query appeared first on Towards Data Science. Read More
The Machine Learning “Advent Calendar” Day 16: Kernel Trick in ExcelTowards Data Science Kernel SVM often feels abstract, with kernels, dual formulations, and support vectors. In this article, we take a different path. Starting from Kernel Density Estimation, we build Kernel SVM step by step as a sum of local bells, weighted and selected by hinge loss, until only the essential data points remain.
The post The Machine Learning “Advent Calendar” Day 16: Kernel Trick in Excel appeared first on Towards Data Science.
Kernel SVM often feels abstract, with kernels, dual formulations, and support vectors. In this article, we take a different path. Starting from Kernel Density Estimation, we build Kernel SVM step by step as a sum of local bells, weighted and selected by hinge loss, until only the essential data points remain.
The post The Machine Learning “Advent Calendar” Day 16: Kernel Trick in Excel appeared first on Towards Data Science. Read More

An ongoing campaign has been observed targeting Amazon Web Services (AWS) customers using compromised Identity and Access Management (IAM) credentials to enable cryptocurrency mining. The activity, first detected by Amazon’s GuardDuty managed threat detection service and its automated security monitoring systems on November 2, 2025, employs never-before-seen persistence techniques to hamper Read More
