

RePo: Language Models with Context Re-Positioningcs.AI updates on arXiv.org arXiv:2512.14391v1 Announce Type: cross
Abstract: In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_phi$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo.
arXiv:2512.14391v1 Announce Type: cross
Abstract: In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_phi$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo. Read More

Within the past year, artificial intelligence copilots and agents have quietly permeated the SaaS applications businesses use every day. Tools like Zoom, Slack, Microsoft 365, Salesforce, and ServiceNow now come with built-in AI assistants or agent-like features. Virtually every major SaaS vendor has rushed to embed AI into their offerings. The result is an explosion […]
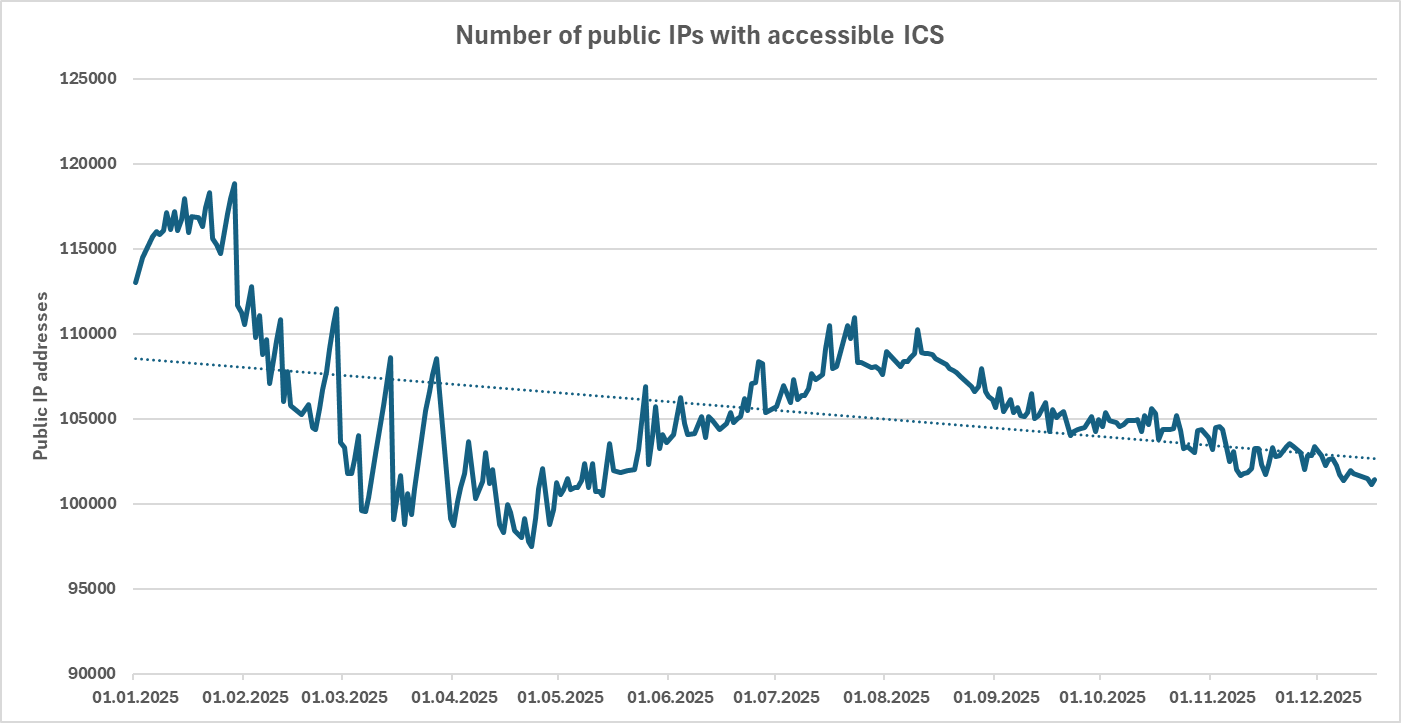
Since the end of the year is quickly approaching, it is undoubtedly a good time to look back at what the past twelve months have brought to us… And given that the entire cyber security profession is about protecting various systems from “bad things” (and we’ve all correspondingly seen more than our share of the […]

Cisco has alerted users to a maximum-severity zero-day flaw in Cisco AsyncOS software that has been actively exploited by a China-nexus advanced persistent threat (APT) actor codenamed UAT-9686 in attacks targeting Cisco Secure Email Gateway and Cisco Secure Email and Web Manager. The networking equipment major said it became aware of the intrusion campaign on […]

Microsoft has confirmed that recent Windows updates trigger RemoteApp connection failures on Windows 11 24H2/25H2 and Windows Server 2025 devices in Azure Virtual Desktop environments. […] Read More

The U.S. Cybersecurity and Infrastructure Security Agency (CISA) on Wednesday added a critical flaw impacting ASUS Live Update to its Known Exploited Vulnerabilities (KEV) catalog, citing evidence of active exploitation. The vulnerability, tracked as CVE-2025-59374 (CVSS score: 9.3), has been described as an “embedded malicious code vulnerability” introduced by means of a supply chain compromise Read […]
Scale-Agnostic Kolmogorov-Arnold Geometry in Neural Networkscs.AI updates on arXiv.org arXiv:2511.21626v3 Announce Type: replace-cross
Abstract: Recent work by Freedman and Mulligan demonstrated that shallow multilayer perceptrons spontaneously develop Kolmogorov-Arnold geometric (KAG) structure during training on synthetic three-dimensional tasks. However, it remained unclear whether this phenomenon persists in realistic high-dimensional settings and what spatial properties this geometry exhibits.
We extend KAG analysis to MNIST digit classification (784 dimensions) using 2-layer MLPs with systematic spatial analysis at multiple scales. We find that KAG emerges during training and appears consistently across spatial scales, from local 7-pixel neighborhoods to the full 28×28 image. This scale-agnostic property holds across different training procedures: both standard training and training with spatial augmentation produce the same qualitative pattern. These findings reveal that neural networks spontaneously develop organized, scale-invariant geometric structure during learning on realistic high-dimensional data.
arXiv:2511.21626v3 Announce Type: replace-cross
Abstract: Recent work by Freedman and Mulligan demonstrated that shallow multilayer perceptrons spontaneously develop Kolmogorov-Arnold geometric (KAG) structure during training on synthetic three-dimensional tasks. However, it remained unclear whether this phenomenon persists in realistic high-dimensional settings and what spatial properties this geometry exhibits.
We extend KAG analysis to MNIST digit classification (784 dimensions) using 2-layer MLPs with systematic spatial analysis at multiple scales. We find that KAG emerges during training and appears consistently across spatial scales, from local 7-pixel neighborhoods to the full 28×28 image. This scale-agnostic property holds across different training procedures: both standard training and training with spatial augmentation produce the same qualitative pattern. These findings reveal that neural networks spontaneously develop organized, scale-invariant geometric structure during learning on realistic high-dimensional data. Read More
STEMS: Spatial-Temporal Enhanced Safe Multi-Agent Coordination for Building Energy Managementcs.AI updates on arXiv.org arXiv:2510.14112v2 Announce Type: replace
Abstract: Building energy management is essential for achieving carbon reduction goals, improving occupant comfort, and reducing energy costs. Coordinated building energy management faces critical challenges in exploiting spatial-temporal dependencies while ensuring operational safety across multi-building systems. Current multi-building energy systems face three key challenges: insufficient spatial-temporal information exploitation, lack of rigorous safety guarantees, and system complexity. This paper proposes Spatial-Temporal Enhanced Safe Multi-Agent Coordination (STEMS), a novel safety-constrained multi-agent reinforcement learning framework for coordinated building energy management. STEMS integrates two core components: (1) a spatial-temporal graph representation learning framework using a GCN-Transformer fusion architecture to capture inter-building relationships and temporal patterns, and (2) a safety-constrained multi-agent RL algorithm incorporating Control Barrier Functions to provide mathematical safety guarantees. Extensive experiments on real-world building datasets demonstrate STEMS’s superior performance over existing methods, showing that STEMS achieves 21% cost reduction, 18% emission reduction, and dramatically reduces safety violations from 35.1% to 5.6% while maintaining optimal comfort with only 0.13 discomfort proportion. The framework also demonstrates strong robustness during extreme weather conditions and maintains effectiveness across different building types.
arXiv:2510.14112v2 Announce Type: replace
Abstract: Building energy management is essential for achieving carbon reduction goals, improving occupant comfort, and reducing energy costs. Coordinated building energy management faces critical challenges in exploiting spatial-temporal dependencies while ensuring operational safety across multi-building systems. Current multi-building energy systems face three key challenges: insufficient spatial-temporal information exploitation, lack of rigorous safety guarantees, and system complexity. This paper proposes Spatial-Temporal Enhanced Safe Multi-Agent Coordination (STEMS), a novel safety-constrained multi-agent reinforcement learning framework for coordinated building energy management. STEMS integrates two core components: (1) a spatial-temporal graph representation learning framework using a GCN-Transformer fusion architecture to capture inter-building relationships and temporal patterns, and (2) a safety-constrained multi-agent RL algorithm incorporating Control Barrier Functions to provide mathematical safety guarantees. Extensive experiments on real-world building datasets demonstrate STEMS’s superior performance over existing methods, showing that STEMS achieves 21% cost reduction, 18% emission reduction, and dramatically reduces safety violations from 35.1% to 5.6% while maintaining optimal comfort with only 0.13 discomfort proportion. The framework also demonstrates strong robustness during extreme weather conditions and maintains effectiveness across different building types. Read More
Text-guided multi-property molecular optimization with a diffusion language modelcs.AI updates on arXiv.org arXiv:2410.13597v4 Announce Type: replace-cross
Abstract: Molecular optimization (MO) is a crucial stage in drug discovery in which task-oriented generated molecules are optimized to meet practical industrial requirements. Existing mainstream MO approaches primarily utilize external property predictors to guide iterative property optimization. However, learning all molecular samples in the vast chemical space is unrealistic for predictors. As a result, errors and noise are inevitably introduced during property prediction due to the nature of approximation. This leads to discrepancy accumulation, generalization reduction and suboptimal molecular candidates. In this paper, we propose a text-guided multi-property molecular optimization method utilizing transformer-based diffusion language model (TransDLM). TransDLM leverages standardized chemical nomenclature as semantic representations of molecules and implicitly embeds property requirements into textual descriptions, thereby mitigating error propagation during diffusion process. By fusing physically and chemically detailed textual semantics with specialized molecular representations, TransDLM effectively integrates diverse information sources to guide precise optimization, which enhances the model’s ability to balance structural retention and property enhancement. Additionally, the success of a case study further demonstrates TransDLM’s ability to solve practical problems. Experimentally, our approach surpasses state-of-the-art methods in maintaining molecular structural similarity and enhancing chemical properties on the benchmark dataset.
arXiv:2410.13597v4 Announce Type: replace-cross
Abstract: Molecular optimization (MO) is a crucial stage in drug discovery in which task-oriented generated molecules are optimized to meet practical industrial requirements. Existing mainstream MO approaches primarily utilize external property predictors to guide iterative property optimization. However, learning all molecular samples in the vast chemical space is unrealistic for predictors. As a result, errors and noise are inevitably introduced during property prediction due to the nature of approximation. This leads to discrepancy accumulation, generalization reduction and suboptimal molecular candidates. In this paper, we propose a text-guided multi-property molecular optimization method utilizing transformer-based diffusion language model (TransDLM). TransDLM leverages standardized chemical nomenclature as semantic representations of molecules and implicitly embeds property requirements into textual descriptions, thereby mitigating error propagation during diffusion process. By fusing physically and chemically detailed textual semantics with specialized molecular representations, TransDLM effectively integrates diverse information sources to guide precise optimization, which enhances the model’s ability to balance structural retention and property enhancement. Additionally, the success of a case study further demonstrates TransDLM’s ability to solve practical problems. Experimentally, our approach surpasses state-of-the-art methods in maintaining molecular structural similarity and enhancing chemical properties on the benchmark dataset. Read More
Native and Compact Structured Latents for 3D Generationcs.AI updates on arXiv.org arXiv:2512.14692v1 Announce Type: cross
Abstract: Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
arXiv:2512.14692v1 Announce Type: cross
Abstract: Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling. Read More
