
The Machine Learning “Advent Calendar” Day 16: Kernel Trick in ExcelTowards Data Science Kernel SVM often feels abstract, with kernels, dual formulations, and support vectors. In this article, we take a different path. Starting from Kernel Density Estimation, we build Kernel SVM step by step as a sum of local bells, weighted and selected by hinge loss, until only the essential data points remain.
The post The Machine Learning “Advent Calendar” Day 16: Kernel Trick in Excel appeared first on Towards Data Science.
Kernel SVM often feels abstract, with kernels, dual formulations, and support vectors. In this article, we take a different path. Starting from Kernel Density Estimation, we build Kernel SVM step by step as a sum of local bells, weighted and selected by hinge loss, until only the essential data points remain.
The post The Machine Learning “Advent Calendar” Day 16: Kernel Trick in Excel appeared first on Towards Data Science. Read More
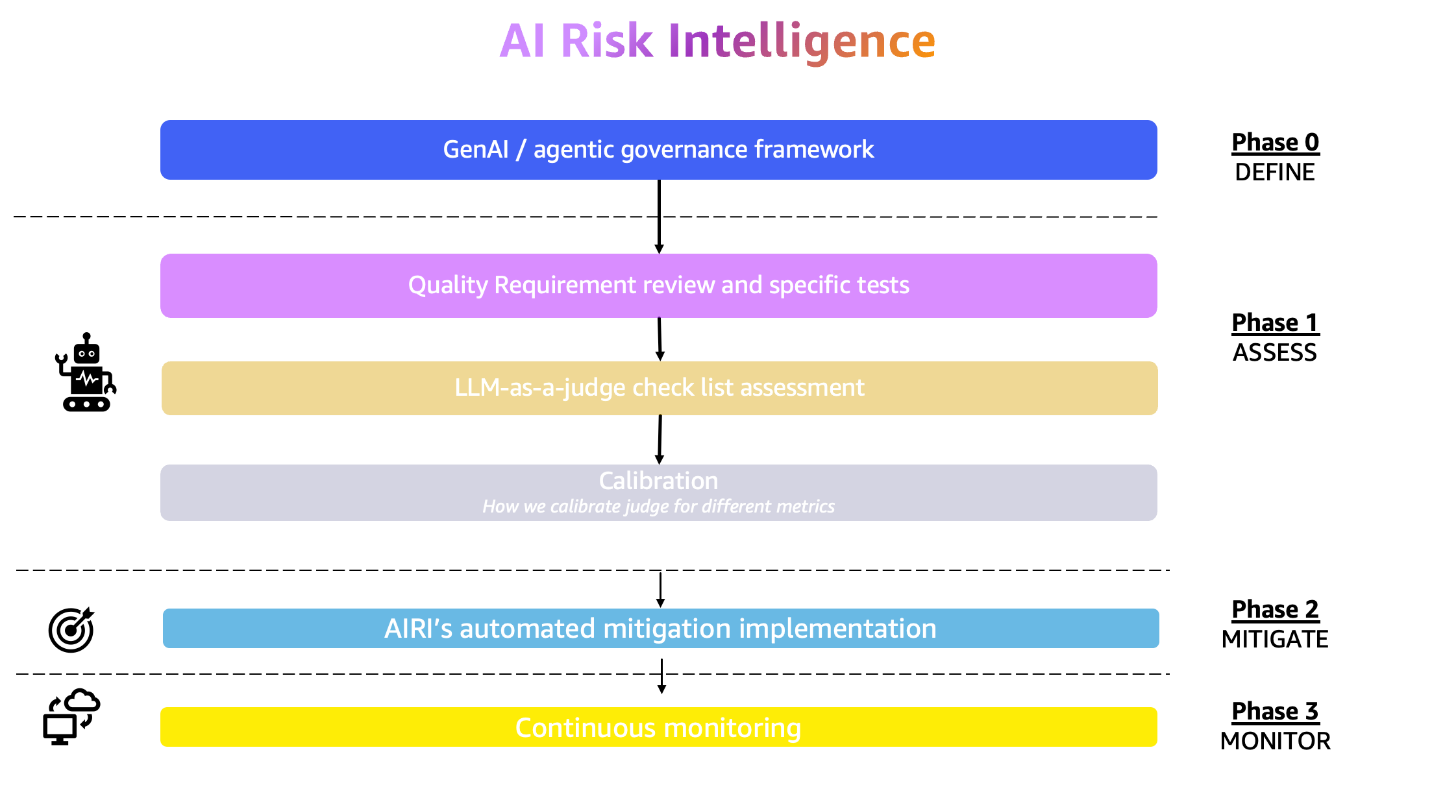
Governance by design: The essential guide for successful AI scalingArtificial Intelligence Picture this: Your enterprise has just deployed its first generative AI application. The initial results are promising, but as you plan to scale across departments, critical questions emerge. How will you enforce consistent security, prevent model bias, and maintain control as AI applications multiply?
Picture this: Your enterprise has just deployed its first generative AI application. The initial results are promising, but as you plan to scale across departments, critical questions emerge. How will you enforce consistent security, prevent model bias, and maintain control as AI applications multiply? Read More
How Tata Power CoE built a scalable AI-powered solar panel inspection solution with Amazon SageMaker AI and Amazon BedrockArtificial Intelligence In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end.
In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end. Read More
Unlocking video understanding with TwelveLabs Marengo on Amazon BedrockArtificial Intelligence In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery.
In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery. Read More
When (Not) to Use Vector DBTowards Data Science When indexing hurts more than it helps: how we realized our RAG use case needed a key-value store, not a vector database
The post When (Not) to Use Vector DB appeared first on Towards Data Science.
When indexing hurts more than it helps: how we realized our RAG use case needed a key-value store, not a vector database
The post When (Not) to Use Vector DB appeared first on Towards Data Science. Read More
What AI search tools mean for the future of SEO specialistsAI News AI search engines and generative AI tools are certainly transforming how people discover information online. Far from making SEO specialists obsolete, the shift highlights clearly why skilled human optimisers remain more important than ever. As generative AI search tools reshape the digital landscape, many wonder whether traditional SEO has reached the end. Despite AI’s growing
The post What AI search tools mean for the future of SEO specialists appeared first on AI News.
AI search engines and generative AI tools are certainly transforming how people discover information online. Far from making SEO specialists obsolete, the shift highlights clearly why skilled human optimisers remain more important than ever. As generative AI search tools reshape the digital landscape, many wonder whether traditional SEO has reached the end. Despite AI’s growing
The post What AI search tools mean for the future of SEO specialists appeared first on AI News. Read More
Harmonizing Generalization and Specialization: Uncertainty-Informed Collaborative Learning for Semi-supervised Medical Image Segmentationcs.AI updates on arXiv.org arXiv:2512.13101v1 Announce Type: cross
Abstract: Vision foundation models have demonstrated strong generalization in medical image segmentation by leveraging large-scale, heterogeneous pretraining. However, they often struggle to generalize to specialized clinical tasks under limited annotations or rare pathological variations, due to a mismatch between general priors and task-specific requirements. To address this, we propose Uncertainty-informed Collaborative Learning (UnCoL), a dual-teacher framework that harmonizes generalization and specialization in semi-supervised medical image segmentation. Specifically, UnCoL distills both visual and semantic representations from a frozen foundation model to transfer general knowledge, while concurrently maintaining a progressively adapting teacher to capture fine-grained and task-specific representations. To balance guidance from both teachers, pseudo-label learning in UnCoL is adaptively regulated by predictive uncertainty, which selectively suppresses unreliable supervision and stabilizes learning in ambiguous regions. Experiments on diverse 2D and 3D segmentation benchmarks show that UnCoL consistently outperforms state-of-the-art semi-supervised methods and foundation model baselines. Moreover, our model delivers near fully supervised performance with markedly reduced annotation requirements.
arXiv:2512.13101v1 Announce Type: cross
Abstract: Vision foundation models have demonstrated strong generalization in medical image segmentation by leveraging large-scale, heterogeneous pretraining. However, they often struggle to generalize to specialized clinical tasks under limited annotations or rare pathological variations, due to a mismatch between general priors and task-specific requirements. To address this, we propose Uncertainty-informed Collaborative Learning (UnCoL), a dual-teacher framework that harmonizes generalization and specialization in semi-supervised medical image segmentation. Specifically, UnCoL distills both visual and semantic representations from a frozen foundation model to transfer general knowledge, while concurrently maintaining a progressively adapting teacher to capture fine-grained and task-specific representations. To balance guidance from both teachers, pseudo-label learning in UnCoL is adaptively regulated by predictive uncertainty, which selectively suppresses unreliable supervision and stabilizes learning in ambiguous regions. Experiments on diverse 2D and 3D segmentation benchmarks show that UnCoL consistently outperforms state-of-the-art semi-supervised methods and foundation model baselines. Moreover, our model delivers near fully supervised performance with markedly reduced annotation requirements. Read More
Synthetic bootstrapped pretrainingcs.AI updates on arXiv.org arXiv:2509.15248v3 Announce Type: replace-cross
Abstract: We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter and a 6B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers up to 60% of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases — SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
arXiv:2509.15248v3 Announce Type: replace-cross
Abstract: We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter and a 6B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers up to 60% of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases — SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents. Read More
BNP Paribas introduces AI tool for investment bankingAI News BNP Paribas is testing how far AI can be pushed into the day-to-day mechanics of investment banking. According to Financial News, the bank has rolled out an internal tool called IB Portal, designed to help bankers assemble client pitches more quickly and with less repetition. Pitch preparation sits at the centre of investment banking work.
The post BNP Paribas introduces AI tool for investment banking appeared first on AI News.
BNP Paribas is testing how far AI can be pushed into the day-to-day mechanics of investment banking. According to Financial News, the bank has rolled out an internal tool called IB Portal, designed to help bankers assemble client pitches more quickly and with less repetition. Pitch preparation sits at the centre of investment banking work.
The post BNP Paribas introduces AI tool for investment banking appeared first on AI News. Read More
Lessons Learned After 8 Years of Machine LearningTowards Data Science Deep work, over-identification, sports, and blogging
The post Lessons Learned After 8 Years of Machine Learning appeared first on Towards Data Science.
Deep work, over-identification, sports, and blogging
The post Lessons Learned After 8 Years of Machine Learning appeared first on Towards Data Science. Read More