
Enhancing Renal Tumor Malignancy Prediction: Deep Learning with Automatic 3D CT Organ Focused Attentioncs.AI updates on arXiv.org arXiv:2602.22381v1 Announce Type: cross
Abstract: Accurate prediction of malignancy in renal tumors is crucial for informing clinical decisions and optimizing treatment strategies. However, existing imaging modalities lack the necessary accuracy to reliably predict malignancy before surgical intervention. While deep learning has shown promise in malignancy prediction using 3D CT images, traditional approaches often rely on manual segmentation to isolate the tumor region and reduce noise, which enhances predictive performance. Manual segmentation, however, is labor-intensive, costly, and dependent on expert knowledge. In this study, a deep learning framework was developed utilizing an Organ Focused Attention (OFA) loss function to modify the attention of image patches so that organ patches attend only to other organ patches. Hence, no segmentation of 3D renal CT images is required at deployment time for malignancy prediction. The proposed framework achieved an AUC of 0.685 and an F1-score of 0.872 on a private dataset from the UF Integrated Data Repository (IDR), and an AUC of 0.760 and an F1-score of 0.852 on the publicly available KiTS21 dataset. These results surpass the performance of conventional models that rely on segmentation-based cropping for noise reduction, demonstrating the frameworks ability to enhance predictive accuracy without explicit segmentation input. The findings suggest that this approach offers a more efficient and reliable method for malignancy prediction, thereby enhancing clinical decision-making in renal cancer diagnosis.
arXiv:2602.22381v1 Announce Type: cross
Abstract: Accurate prediction of malignancy in renal tumors is crucial for informing clinical decisions and optimizing treatment strategies. However, existing imaging modalities lack the necessary accuracy to reliably predict malignancy before surgical intervention. While deep learning has shown promise in malignancy prediction using 3D CT images, traditional approaches often rely on manual segmentation to isolate the tumor region and reduce noise, which enhances predictive performance. Manual segmentation, however, is labor-intensive, costly, and dependent on expert knowledge. In this study, a deep learning framework was developed utilizing an Organ Focused Attention (OFA) loss function to modify the attention of image patches so that organ patches attend only to other organ patches. Hence, no segmentation of 3D renal CT images is required at deployment time for malignancy prediction. The proposed framework achieved an AUC of 0.685 and an F1-score of 0.872 on a private dataset from the UF Integrated Data Repository (IDR), and an AUC of 0.760 and an F1-score of 0.852 on the publicly available KiTS21 dataset. These results surpass the performance of conventional models that rely on segmentation-based cropping for noise reduction, demonstrating the frameworks ability to enhance predictive accuracy without explicit segmentation input. The findings suggest that this approach offers a more efficient and reliable method for malignancy prediction, thereby enhancing clinical decision-making in renal cancer diagnosis. Read More
ASML’s high-NA EUV tools clear the runway for next-gen AI chipsAI News The machine that will make tomorrow’s AI chips possible has just been declared ready for mass production–and the clock for the industry’s next leap has officially started. ASML, the Dutch company that holds a global monopoly on commercial extreme ultraviolet lithography equipment, confirmed this week that its High-NA EUV tools have crossed the threshold from
The post ASML’s high-NA EUV tools clear the runway for next-gen AI chips appeared first on AI News.
The machine that will make tomorrow’s AI chips possible has just been declared ready for mass production–and the clock for the industry’s next leap has officially started. ASML, the Dutch company that holds a global monopoly on commercial extreme ultraviolet lithography equipment, confirmed this week that its High-NA EUV tools have crossed the threshold from
The post ASML’s high-NA EUV tools clear the runway for next-gen AI chips appeared first on AI News. Read More

Top 7 OpenClaw Tools & Integrations You Are Missing Out OnKDnuggets Most people are only using 10% of OpenClaw. These integrations unlock what it is truly capable of.
Most people are only using 10% of OpenClaw. These integrations unlock what it is truly capable of. Read More
Detecting and Editing Visual Objects with GeminiTowards Data Science A practical guide to identifying, restoring, and transforming elements within your images
The post Detecting and Editing Visual Objects with Gemini appeared first on Towards Data Science.
A practical guide to identifying, restoring, and transforming elements within your images
The post Detecting and Editing Visual Objects with Gemini appeared first on Towards Data Science. Read More

Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh: What’s the Difference?KDnuggets Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh explained simply. Learn the key differences and which architecture fits your data needs
Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh explained simply. Learn the key differences and which architecture fits your data needs Read More
A Generalizable MARL-LP Approach for Scheduling in LogisticsTowards Data Science Part 1. Hybrid Solution for Dynamic Vehicle Routing — Context and Architecture
The post A Generalizable MARL-LP Approach for Scheduling in Logistics appeared first on Towards Data Science.
Part 1. Hybrid Solution for Dynamic Vehicle Routing — Context and Architecture
The post A Generalizable MARL-LP Approach for Scheduling in Logistics appeared first on Towards Data Science. Read More
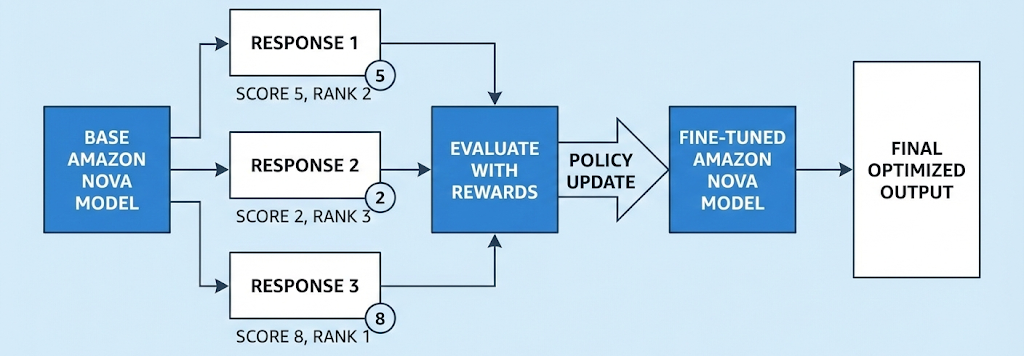
Reinforcement fine-tuning for Amazon Nova: Teaching AI through feedbackArtificial Intelligence In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results.
In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results. Read More

Large model inference container – latest capabilities and performance enhancementsArtificial Intelligence AWS recently released significant updates to the Large Model Inference (LMI) container, delivering comprehensive performance improvements, expanded model support, and streamlined deployment capabilities for customers hosting LLMs on AWS. These releases focus on reducing operational complexity while delivering measurable performance gains across popular model architectures.
AWS recently released significant updates to the Large Model Inference (LMI) container, delivering comprehensive performance improvements, expanded model support, and streamlined deployment capabilities for customers hosting LLMs on AWS. These releases focus on reducing operational complexity while delivering measurable performance gains across popular model architectures. Read More

5 Useful Python Scripts for Automated Data Quality ChecksKDnuggets Bad data leads to bad decisions. These Python scripts will help you catch data quality issues before they cause problems.
Bad data leads to bad decisions. These Python scripts will help you catch data quality issues before they cause problems. Read More
Designing Data and AI Systems That Hold Up in ProductionTowards Data Science A system-level perspective on architecture, agents, and responsible scale
The post Designing Data and AI Systems That Hold Up in Production appeared first on Towards Data Science.
A system-level perspective on architecture, agents, and responsible scale
The post Designing Data and AI Systems That Hold Up in Production appeared first on Towards Data Science. Read More