
Why Disney is embedding generative AI into its operating modelAI News For a company built on intellectual property, scale creates a familiar tension. Disney needs to produce and distribute content across many formats and audiences, while keeping tight control over rights, safety, and brand consistency. Generative AI promises speed and flexibility, but unmanaged use risks creating legal, creative, and operational drag. Disney’s agreement with OpenAI shows
The post Why Disney is embedding generative AI into its operating model appeared first on AI News.
For a company built on intellectual property, scale creates a familiar tension. Disney needs to produce and distribute content across many formats and audiences, while keeping tight control over rights, safety, and brand consistency. Generative AI promises speed and flexibility, but unmanaged use risks creating legal, creative, and operational drag. Disney’s agreement with OpenAI shows
The post Why Disney is embedding generative AI into its operating model appeared first on AI News. Read More
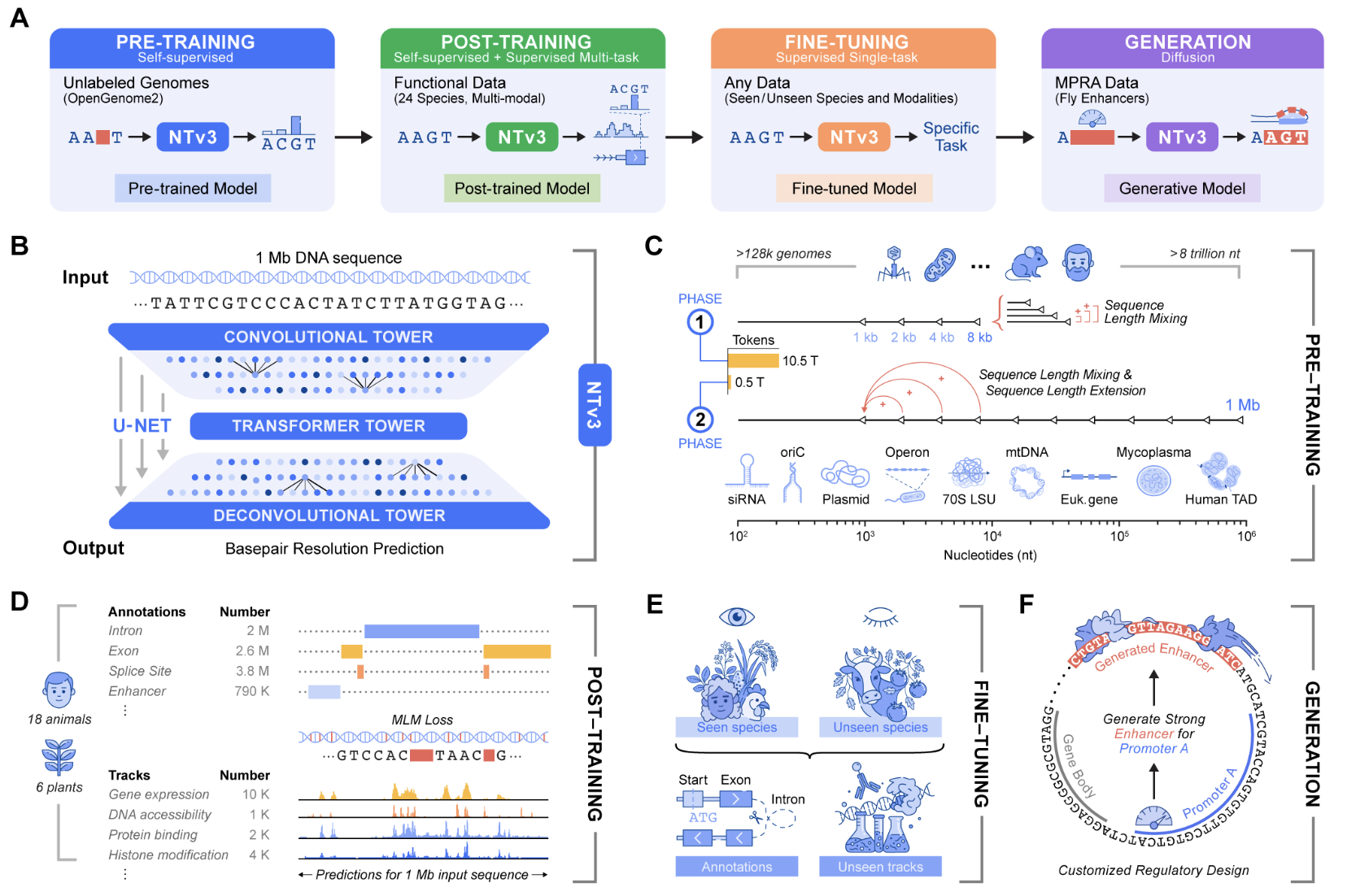
InstaDeep Introduces Nucleotide Transformer v3 (NTv3): A New Multi-Species Genomics Foundation Model, Designed for 1 Mb Context Lengths at Single-Nucleotide ResolutionMarkTechPost Genomic prediction and design now require models that connect local motifs with megabase scale regulatory context and that operate across many organisms. Nucleotide Transformer v3, or NTv3, is InstaDeep’s new multi species genomics foundation model for this setting. It unifies representation learning, functional track and genome annotation prediction, and controllable sequence generation in a single
The post InstaDeep Introduces Nucleotide Transformer v3 (NTv3): A New Multi-Species Genomics Foundation Model, Designed for 1 Mb Context Lengths at Single-Nucleotide Resolution appeared first on MarkTechPost.
Genomic prediction and design now require models that connect local motifs with megabase scale regulatory context and that operate across many organisms. Nucleotide Transformer v3, or NTv3, is InstaDeep’s new multi species genomics foundation model for this setting. It unifies representation learning, functional track and genome annotation prediction, and controllable sequence generation in a single
The post InstaDeep Introduces Nucleotide Transformer v3 (NTv3): A New Multi-Species Genomics Foundation Model, Designed for 1 Mb Context Lengths at Single-Nucleotide Resolution appeared first on MarkTechPost. Read More
A K-Means, Ward and DBSCAN repeatability studycs.AI updates on arXiv.org arXiv:2512.19772v1 Announce Type: cross
Abstract: Reproducibility is essential in machine learning because it ensures that a model or experiment yields the same scientific conclusion. For specific algorithms repeatability with bitwise identical results is also a key for scientific integrity because it allows debugging. We decomposed several very popular clustering algorithms: K-Means, DBSCAN and Ward into their fundamental steps, and we identify the conditions required to achieve repeatability at each stage. We use an implementation example with the Python library scikit-learn to examine the repeatable aspects of each method. Our results reveal inconsistent results with K-Means when the number of OpenMP threads exceeds two. This work aims to raise awareness of this issue among both users and developers, encouraging further investigation and potential fixes.
arXiv:2512.19772v1 Announce Type: cross
Abstract: Reproducibility is essential in machine learning because it ensures that a model or experiment yields the same scientific conclusion. For specific algorithms repeatability with bitwise identical results is also a key for scientific integrity because it allows debugging. We decomposed several very popular clustering algorithms: K-Means, DBSCAN and Ward into their fundamental steps, and we identify the conditions required to achieve repeatability at each stage. We use an implementation example with the Python library scikit-learn to examine the repeatable aspects of each method. Our results reveal inconsistent results with K-Means when the number of OpenMP threads exceeds two. This work aims to raise awareness of this issue among both users and developers, encouraging further investigation and potential fixes. Read More

AWS AI League: Model customization and agentic showdownArtificial Intelligence In this post, we explore the new AWS AI League challenges and how they are transforming how organizations approach AI development. The grand finale at AWS re:Invent 2025 was an exciting showcase of their ingenuity and skills.
In this post, we explore the new AWS AI League challenges and how they are transforming how organizations approach AI development. The grand finale at AWS re:Invent 2025 was an exciting showcase of their ingenuity and skills. Read More
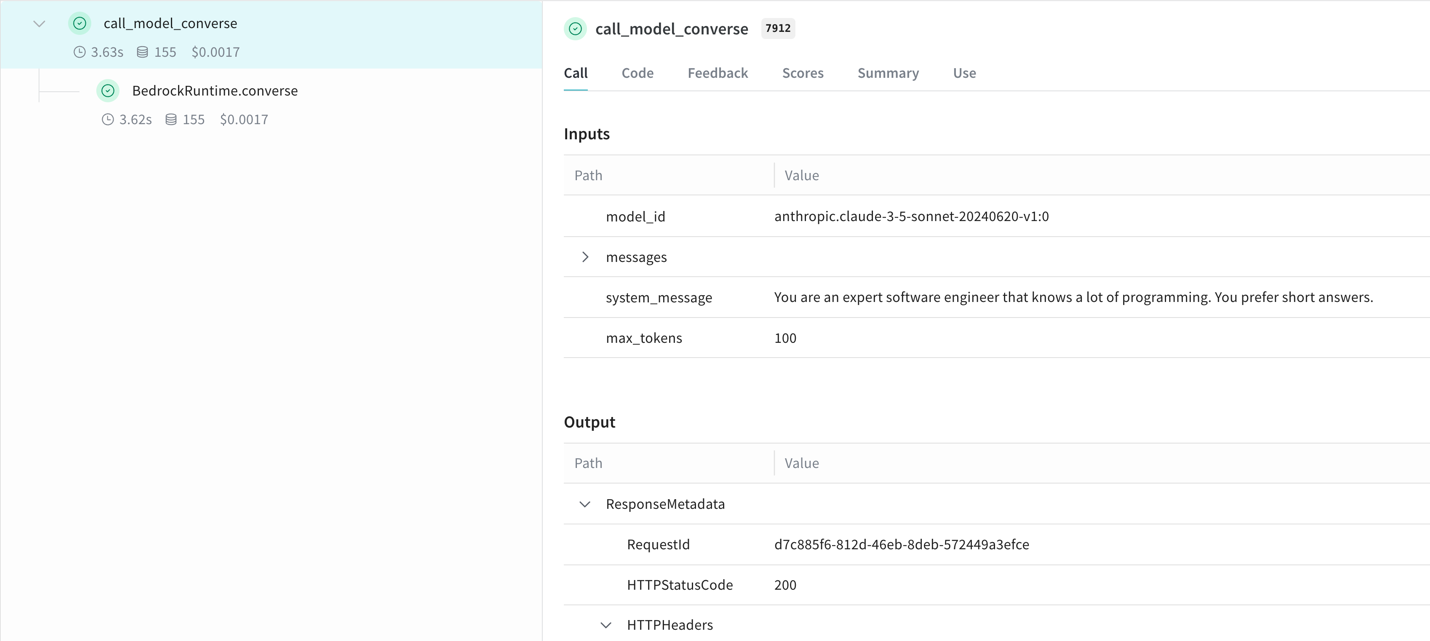
Accelerate Enterprise AI Development using Weights & Biases and Amazon Bedrock AgentCoreArtificial Intelligence In this post, we demonstrate how to use Foundation Models (FMs) from Amazon Bedrock and the newly launched Amazon Bedrock AgentCore alongside W&B Weave to help build, evaluate, and monitor enterprise AI solutions. We cover the complete development lifecycle from tracking individual FM calls to monitoring complex agent workflows in production.
In this post, we demonstrate how to use Foundation Models (FMs) from Amazon Bedrock and the newly launched Amazon Bedrock AgentCore alongside W&B Weave to help build, evaluate, and monitor enterprise AI solutions. We cover the complete development lifecycle from tracking individual FM calls to monitoring complex agent workflows in production. Read More
How to Build a Proactive Pre-Emptive Churn Prevention Agent with Intelligent Observation and Strategy FormationMarkTechPost In this tutorial, we build a fully functional Pre-Emptive Churn Agent that proactively identifies at-risk users and drafts personalized re-engagement emails before they cancel. Rather than waiting for churn to occur, we design an agentic loop in which we observe user inactivity, analyze behavioral patterns, strategize incentives, and generate human-ready email drafts using Gemini. We
The post How to Build a Proactive Pre-Emptive Churn Prevention Agent with Intelligent Observation and Strategy Formation appeared first on MarkTechPost.
In this tutorial, we build a fully functional Pre-Emptive Churn Agent that proactively identifies at-risk users and drafts personalized re-engagement emails before they cancel. Rather than waiting for churn to occur, we design an agentic loop in which we observe user inactivity, analyze behavioral patterns, strategize incentives, and generate human-ready email drafts using Gemini. We
The post How to Build a Proactive Pre-Emptive Churn Prevention Agent with Intelligent Observation and Strategy Formation appeared first on MarkTechPost. Read More
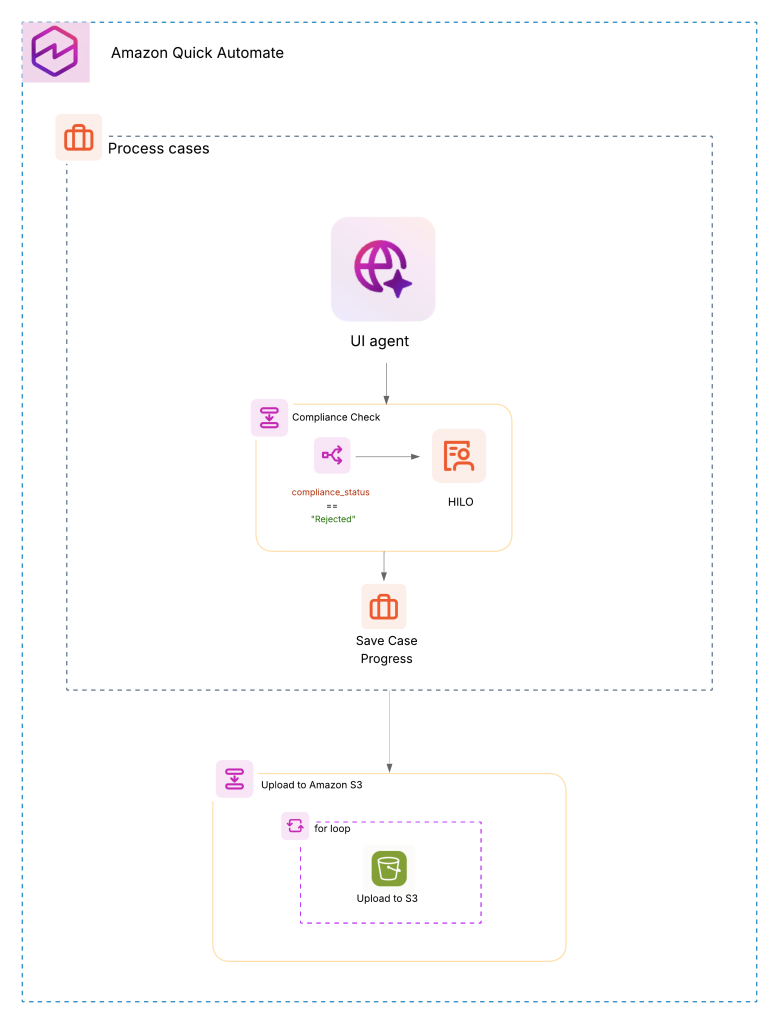
How dLocal automated compliance reviews using Amazon Quick AutomateArtificial Intelligence In this post, we share how dLocal worked closely with the AWS team to help shape the product roadmap, reinforce its role as an industry innovator, and set new benchmarks for operational excellence in the global fintech landscape.
In this post, we share how dLocal worked closely with the AWS team to help shape the product roadmap, reinforce its role as an industry innovator, and set new benchmarks for operational excellence in the global fintech landscape. Read More
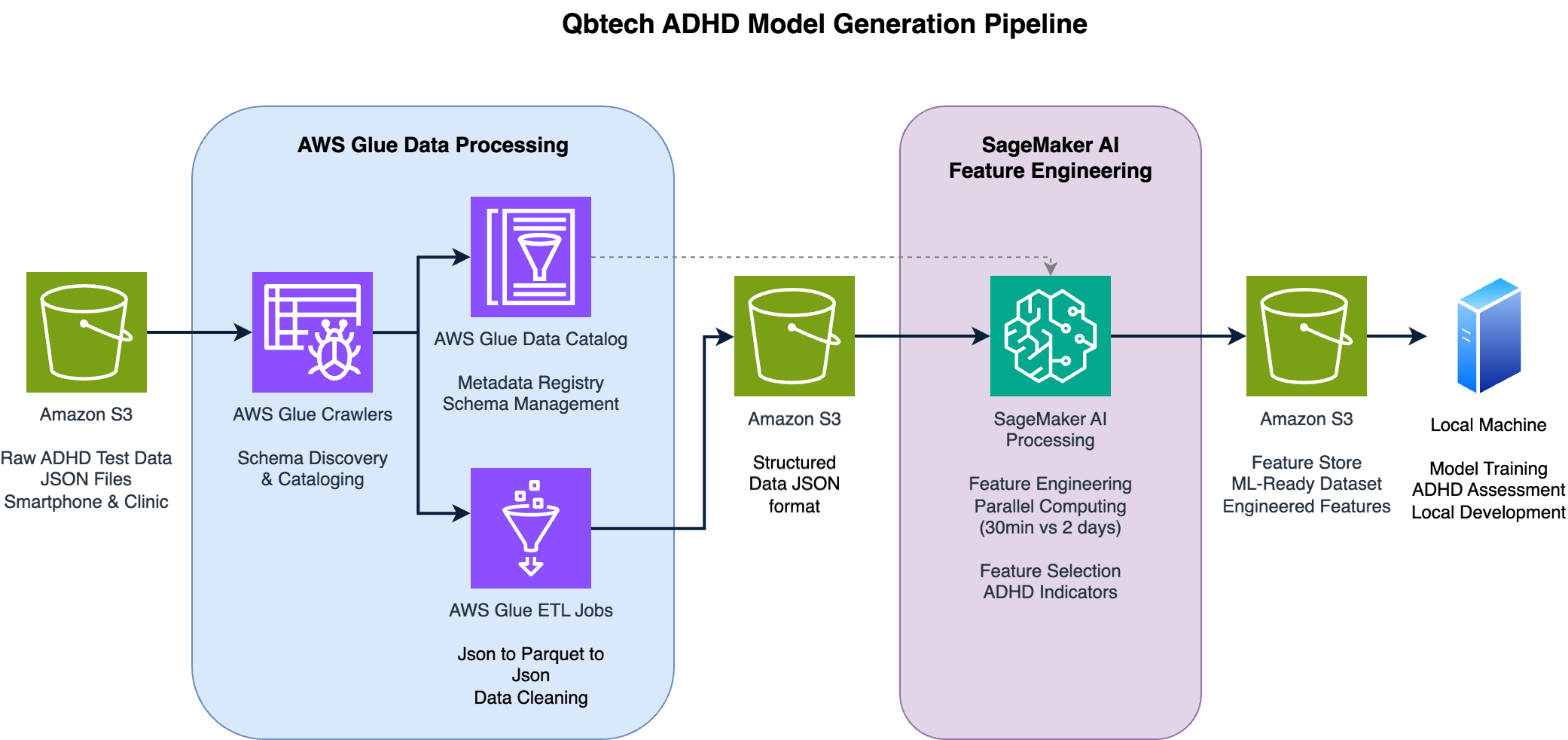
Advancing ADHD diagnosis: How Qbtech built a mobile AI assessment Model Using Amazon SageMaker AIArtificial Intelligence In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers.
In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers. Read More
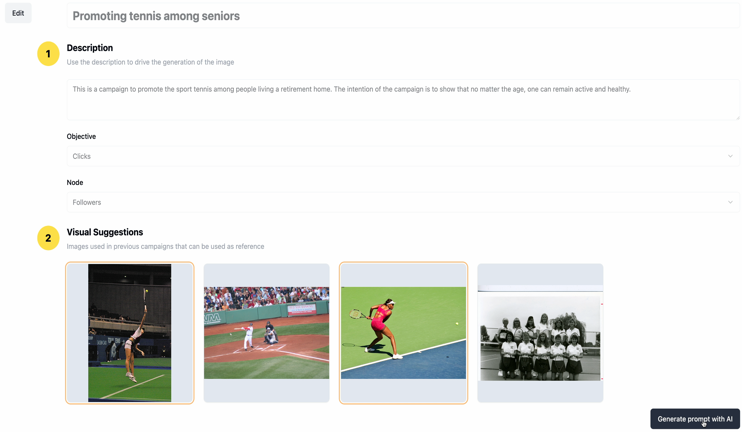
Accelerating your marketing ideation with generative AI – Part 1: From idea to generation with the Amazon Nova foundation modelsArtificial Intelligence In this post, the first of a series of three, we focus on how you can use Amazon Nova to streamline, simplify, and accelerate marketing campaign creation through generative AI. We show how Bancolombia, one of Colombia’s largest banks, is experimenting with the Amazon Nova models to generate visuals for their marketing campaigns.
In this post, the first of a series of three, we focus on how you can use Amazon Nova to streamline, simplify, and accelerate marketing campaign creation through generative AI. We show how Bancolombia, one of Colombia’s largest banks, is experimenting with the Amazon Nova models to generate visuals for their marketing campaigns. Read More
Google’s year in review: 8 areas with research breakthroughs in 2025Google DeepMind News Google 2025 recap: Research breakthroughs of the year
Google 2025 recap: Research breakthroughs of the year Read More