
Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion LLMscs.AI updates on arXiv.org arXiv:2512.20573v1 Announce Type: cross
Abstract: Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM’s speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It “fails fast” by spending minimal compute in hard-to-speculate regions to shrink speculation latency and “wins big” by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$times$ speedup over vanilla decoding, 1.7$times$ over the best naive dLLM drafter, and 1.4$times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast.
arXiv:2512.20573v1 Announce Type: cross
Abstract: Diffusion Large Language Models (dLLMs) offer fast, parallel token generation, but their standalone use is plagued by an inherent efficiency-quality tradeoff. We show that, if carefully applied, the attributes of dLLMs can actually be a strength for drafters in speculative decoding with autoregressive (AR) verifiers. Our core insight is that dLLM’s speed from parallel decoding drastically lowers the risk of costly rejections, providing a practical mechanism to effectively realize the (elusive) lengthy drafts that lead to large speedups with speculative decoding. We present FailFast, a dLLM-based speculative decoding framework that realizes this approach by dynamically adapting its speculation length. It “fails fast” by spending minimal compute in hard-to-speculate regions to shrink speculation latency and “wins big” by aggressively extending draft lengths in easier regions to reduce verification latency (in many cases, speculating and accepting 70 tokens at a time!). Without any fine-tuning, FailFast delivers lossless acceleration of AR LLMs and achieves up to 4.9$times$ speedup over vanilla decoding, 1.7$times$ over the best naive dLLM drafter, and 1.4$times$ over EAGLE-3 across diverse models and workloads. We open-source FailFast at https://github.com/ruipeterpan/failfast. Read More
Learning Treatment Policies From Multimodal Electronic Health Recordscs.AI updates on arXiv.org arXiv:2507.20993v2 Announce Type: replace-cross
Abstract: We study how to learn effective treatment policies from multimodal electronic health records (EHRs) that consist of tabular data and clinical text. These policies can help physicians make better treatment decisions and allocate healthcare resources more efficiently. Causal policy learning methods prioritize patients with the largest expected treatment benefit. Yet, existing estimators assume tabular covariates that satisfy strong causal assumptions, which are typically violated in the multimodal setting. As a result, predictive models of baseline risk are commonly used in practice to guide such decisions, as they extend naturally to multimodal data. However, such risk-based policies are not designed to identify which patients benefit most from treatment. We propose an extension of causal policy learning that uses expert-provided annotations during training to supervise treatment effect estimation, while using only multimodal representations as input during inference. We show that the proposed method achieves strong empirical performance across synthetic, semi-synthetic, and real-world EHR datasets, thereby offering practical insights into applying causal machine learning to realistic clinical data.
arXiv:2507.20993v2 Announce Type: replace-cross
Abstract: We study how to learn effective treatment policies from multimodal electronic health records (EHRs) that consist of tabular data and clinical text. These policies can help physicians make better treatment decisions and allocate healthcare resources more efficiently. Causal policy learning methods prioritize patients with the largest expected treatment benefit. Yet, existing estimators assume tabular covariates that satisfy strong causal assumptions, which are typically violated in the multimodal setting. As a result, predictive models of baseline risk are commonly used in practice to guide such decisions, as they extend naturally to multimodal data. However, such risk-based policies are not designed to identify which patients benefit most from treatment. We propose an extension of causal policy learning that uses expert-provided annotations during training to supervise treatment effect estimation, while using only multimodal representations as input during inference. We show that the proposed method achieves strong empirical performance across synthetic, semi-synthetic, and real-world EHR datasets, thereby offering practical insights into applying causal machine learning to realistic clinical data. Read More
Zero-Shot Segmentation through Prototype-Guidance for Multi-Label Plant Species Identificationcs.AI updates on arXiv.org arXiv:2512.19957v1 Announce Type: new
Abstract: This paper presents an approach developed to address the PlantClef 2025 challenge, which consists of a fine-grained multi-label species identification, over high-resolution images. Our solution focused on employing class prototypes obtained from the training dataset as a proxy guidance for training a segmentation Vision Transformer (ViT) on the test set images. To obtain these representations, the proposed method extracts features from training dataset images and create clusters, by applying K-Means, with $K$ equals to the number of classes in the dataset. The segmentation model is a customized narrow ViT, built by replacing the patch embedding layer with a frozen DinoV2, pre-trained on the training dataset for individual species classification. This model is trained to reconstruct the class prototypes of the training dataset from the test dataset images. We then use this model to obtain attention scores that enable to identify and localize areas of interest and consequently guide the classification process. The proposed approach enabled a domain-adaptation from multi-class identification with individual species, into multi-label classification from high-resolution vegetation plots. Our method achieved fifth place in the PlantCLEF 2025 challenge on the private leaderboard, with an F1 score of 0.33331. Besides that, in absolute terms our method scored 0.03 lower than the top-performing submission, suggesting that it may achieved competitive performance in the benchmark task. Our code is available at href{https://github.com/ADAM-UEFS/PlantCLEF2025}{https://github.com/ADAM-UEFS/PlantCLEF2025}.
arXiv:2512.19957v1 Announce Type: new
Abstract: This paper presents an approach developed to address the PlantClef 2025 challenge, which consists of a fine-grained multi-label species identification, over high-resolution images. Our solution focused on employing class prototypes obtained from the training dataset as a proxy guidance for training a segmentation Vision Transformer (ViT) on the test set images. To obtain these representations, the proposed method extracts features from training dataset images and create clusters, by applying K-Means, with $K$ equals to the number of classes in the dataset. The segmentation model is a customized narrow ViT, built by replacing the patch embedding layer with a frozen DinoV2, pre-trained on the training dataset for individual species classification. This model is trained to reconstruct the class prototypes of the training dataset from the test dataset images. We then use this model to obtain attention scores that enable to identify and localize areas of interest and consequently guide the classification process. The proposed approach enabled a domain-adaptation from multi-class identification with individual species, into multi-label classification from high-resolution vegetation plots. Our method achieved fifth place in the PlantCLEF 2025 challenge on the private leaderboard, with an F1 score of 0.33331. Besides that, in absolute terms our method scored 0.03 lower than the top-performing submission, suggesting that it may achieved competitive performance in the benchmark task. Our code is available at href{https://github.com/ADAM-UEFS/PlantCLEF2025}{https://github.com/ADAM-UEFS/PlantCLEF2025}. Read More
Is Your Model Time-Blind? The Case for Cyclical Feature EncodingTowards Data Science How cyclical encoding improves machine learning prediction
The post Is Your Model Time-Blind? The Case for Cyclical Feature Encoding appeared first on Towards Data Science.
How cyclical encoding improves machine learning prediction
The post Is Your Model Time-Blind? The Case for Cyclical Feature Encoding appeared first on Towards Data Science. Read More
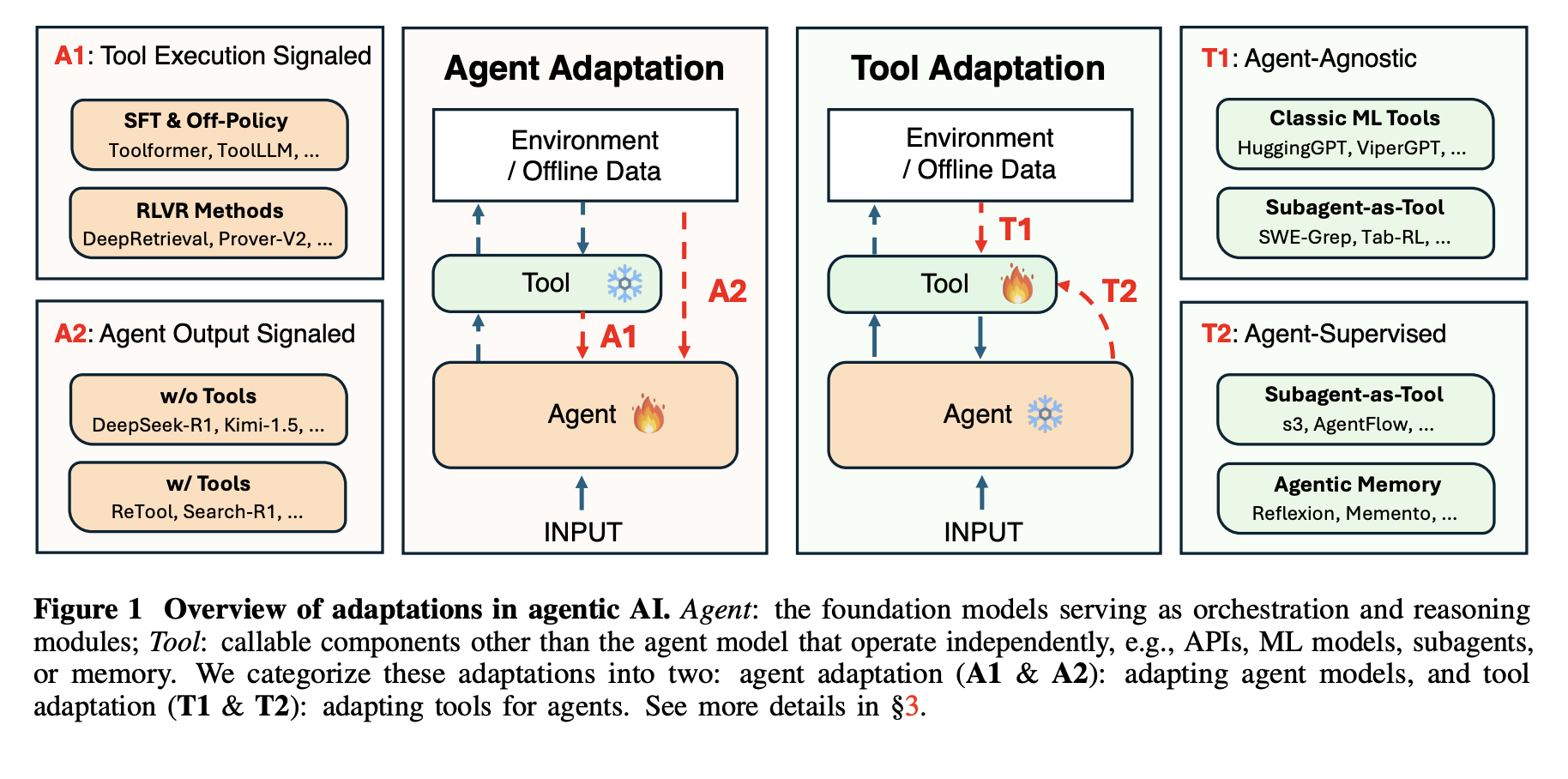
This AI Paper from Stanford and Harvard Explains Why Most ‘Agentic AI’ Systems Feel Impressive in Demos and then Completely Fall Apart in Real UseMarkTechPost Agentic AI systems sit on top of large language models and connect to tools, memory, and external environments. They already support scientific discovery, software development, and clinical research, yet they still struggle with unreliable tool use, weak long horizon planning, and poor generalization. The latest research paper ‘Adaptation of Agentic AI‘ from Stanford, Harvard, UC
The post This AI Paper from Stanford and Harvard Explains Why Most ‘Agentic AI’ Systems Feel Impressive in Demos and then Completely Fall Apart in Real Use appeared first on MarkTechPost.
Agentic AI systems sit on top of large language models and connect to tools, memory, and external environments. They already support scientific discovery, software development, and clinical research, yet they still struggle with unreliable tool use, weak long horizon planning, and poor generalization. The latest research paper ‘Adaptation of Agentic AI‘ from Stanford, Harvard, UC
The post This AI Paper from Stanford and Harvard Explains Why Most ‘Agentic AI’ Systems Feel Impressive in Demos and then Completely Fall Apart in Real Use appeared first on MarkTechPost. Read More
The Machine Learning “Advent Calendar” Day 24: Transformers for Text in ExcelTowards Data Science An intuitive, step-by-step look at how Transformers use self-attention to turn static word embeddings into contextual representations, illustrated with simple examples and an Excel-friendly walkthrough.
The post The Machine Learning “Advent Calendar” Day 24: Transformers for Text in Excel appeared first on Towards Data Science.
An intuitive, step-by-step look at how Transformers use self-attention to turn static word embeddings into contextual representations, illustrated with simple examples and an Excel-friendly walkthrough.
The post The Machine Learning “Advent Calendar” Day 24: Transformers for Text in Excel appeared first on Towards Data Science. Read More
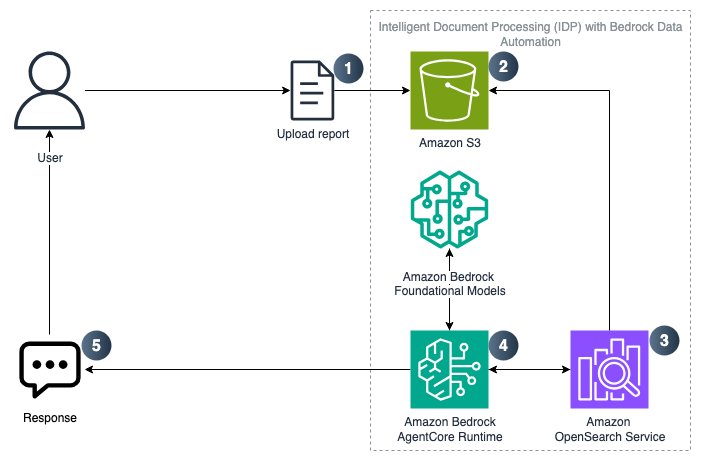
Programmatically creating an IDP solution with Amazon Bedrock Data AutomationArtificial Intelligence In this post, we explore how to programmatically create an IDP solution that uses Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Knowledge Base, and Bedrock Data Automation (BDA). This solution is provided through a Jupyter notebook that enables users to upload multi-modal business documents and extract insights using BDA as a parser to retrieve relevant chunks and augment a prompt to a foundational model (FM).
In this post, we explore how to programmatically create an IDP solution that uses Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Knowledge Base, and Bedrock Data Automation (BDA). This solution is provided through a Jupyter notebook that enables users to upload multi-modal business documents and extract insights using BDA as a parser to retrieve relevant chunks and augment a prompt to a foundational model (FM). Read More
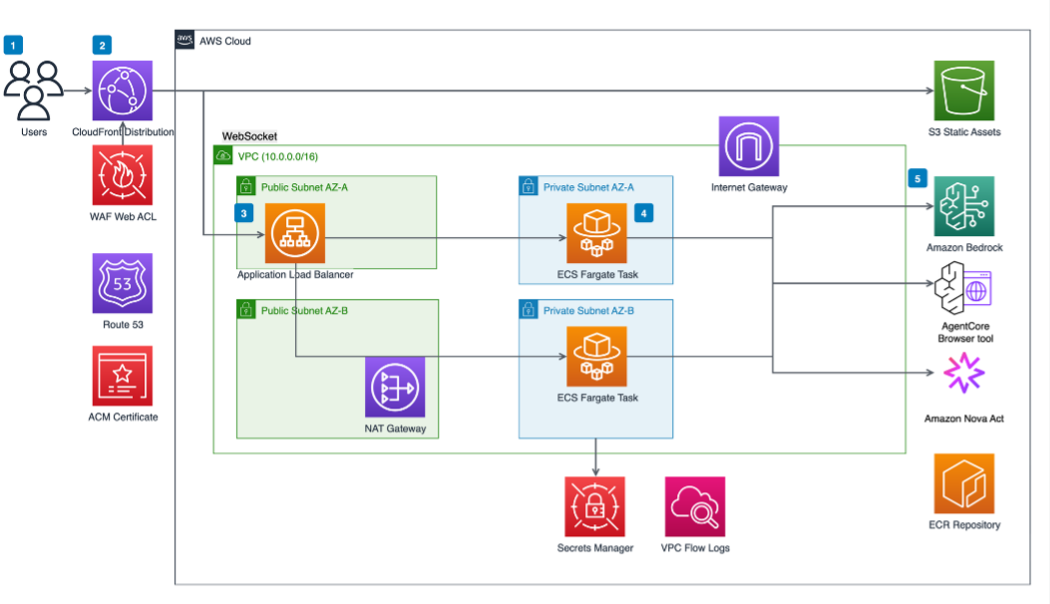
AI agent-driven browser automation for enterprise workflow managementArtificial Intelligence Enterprise organizations increasingly rely on web-based applications for critical business processes, yet many workflows remain manually intensive, creating operational inefficiencies and compliance risks. Despite significant technology investments, knowledge workers routinely navigate between eight to twelve different web applications during standard workflows, constantly switching contexts and manually transferring information between systems. Data entry and validation tasks
Enterprise organizations increasingly rely on web-based applications for critical business processes, yet many workflows remain manually intensive, creating operational inefficiencies and compliance risks. Despite significant technology investments, knowledge workers routinely navigate between eight to twelve different web applications during standard workflows, constantly switching contexts and manually transferring information between systems. Data entry and validation tasks Read More
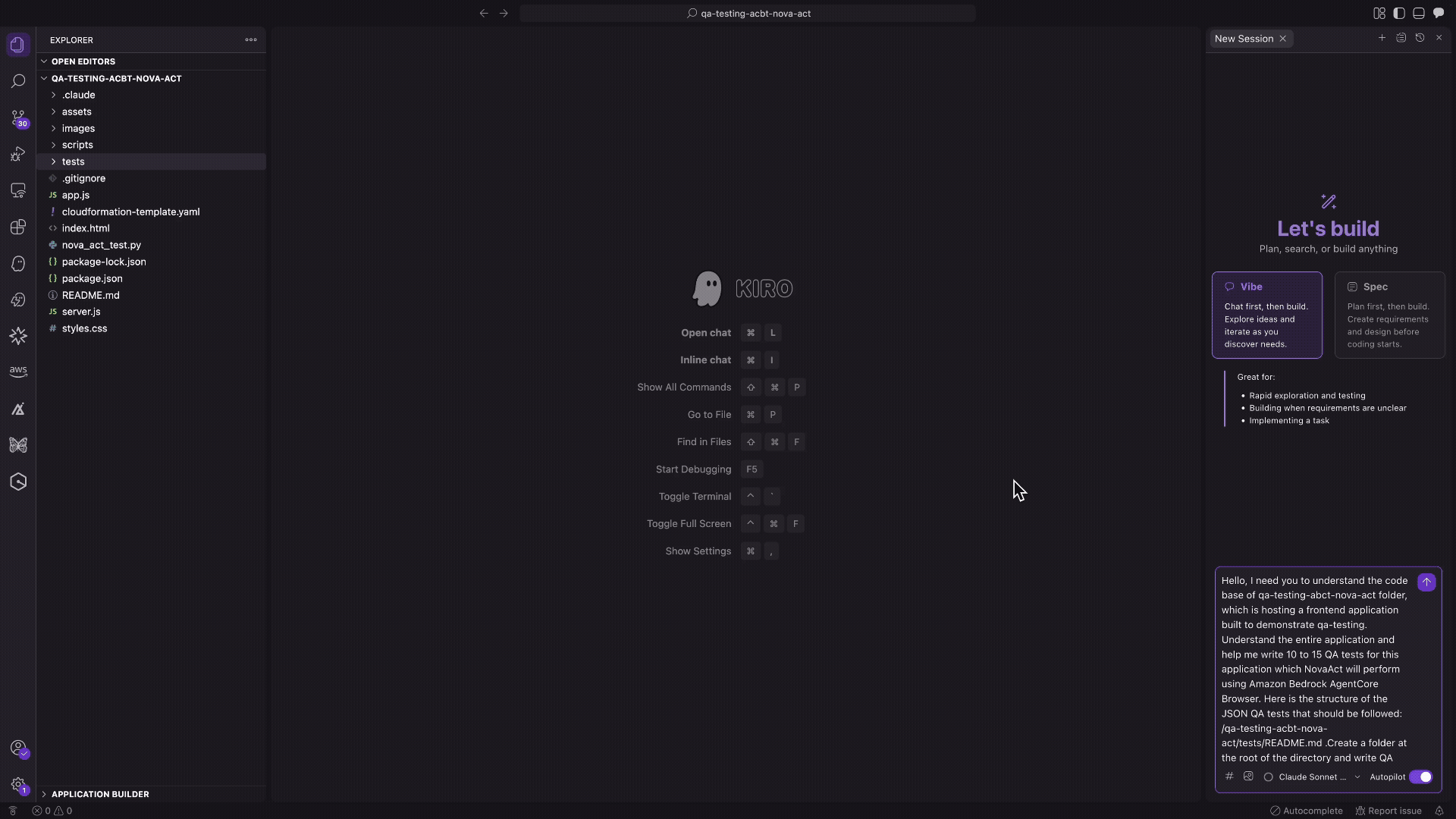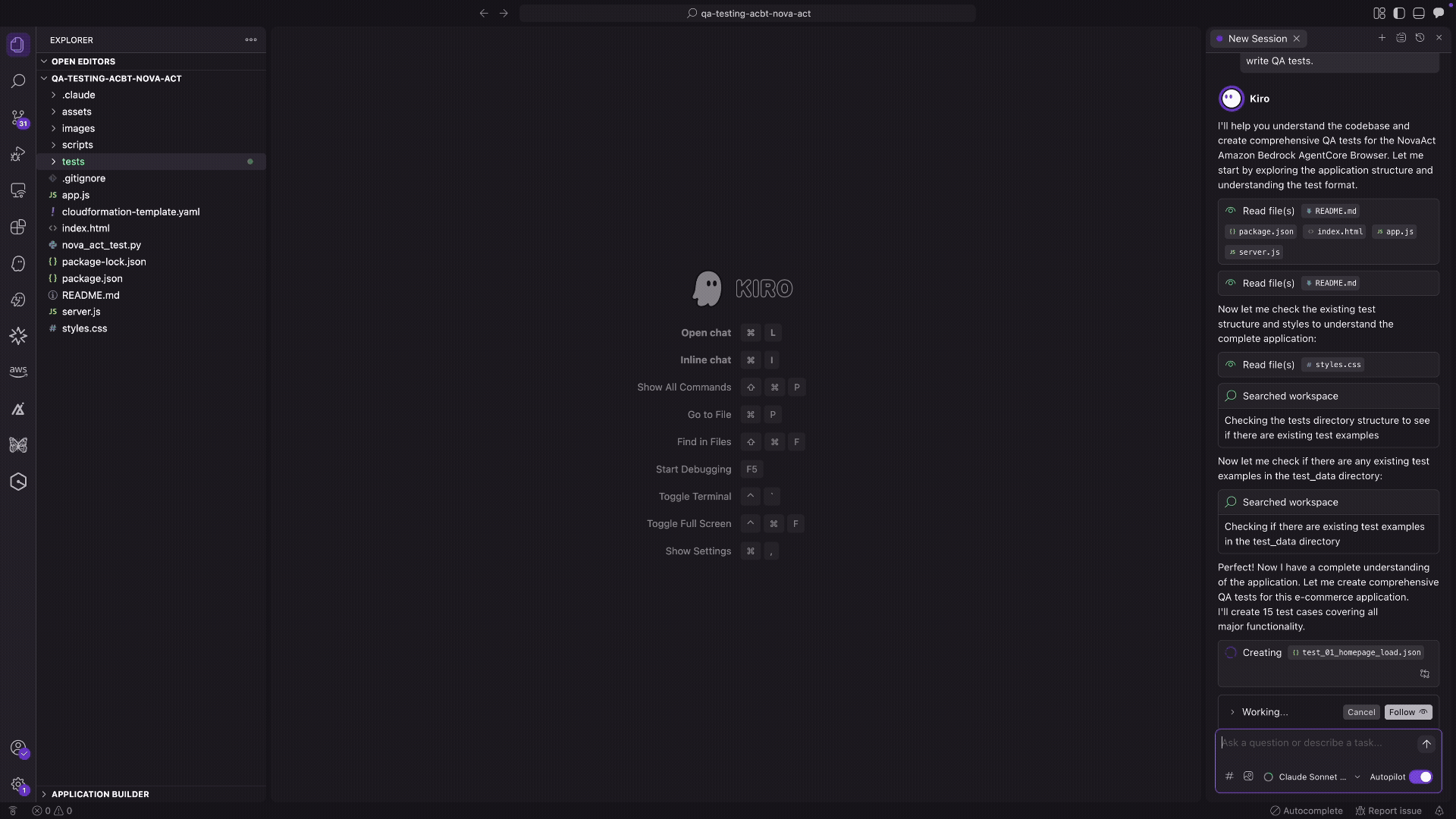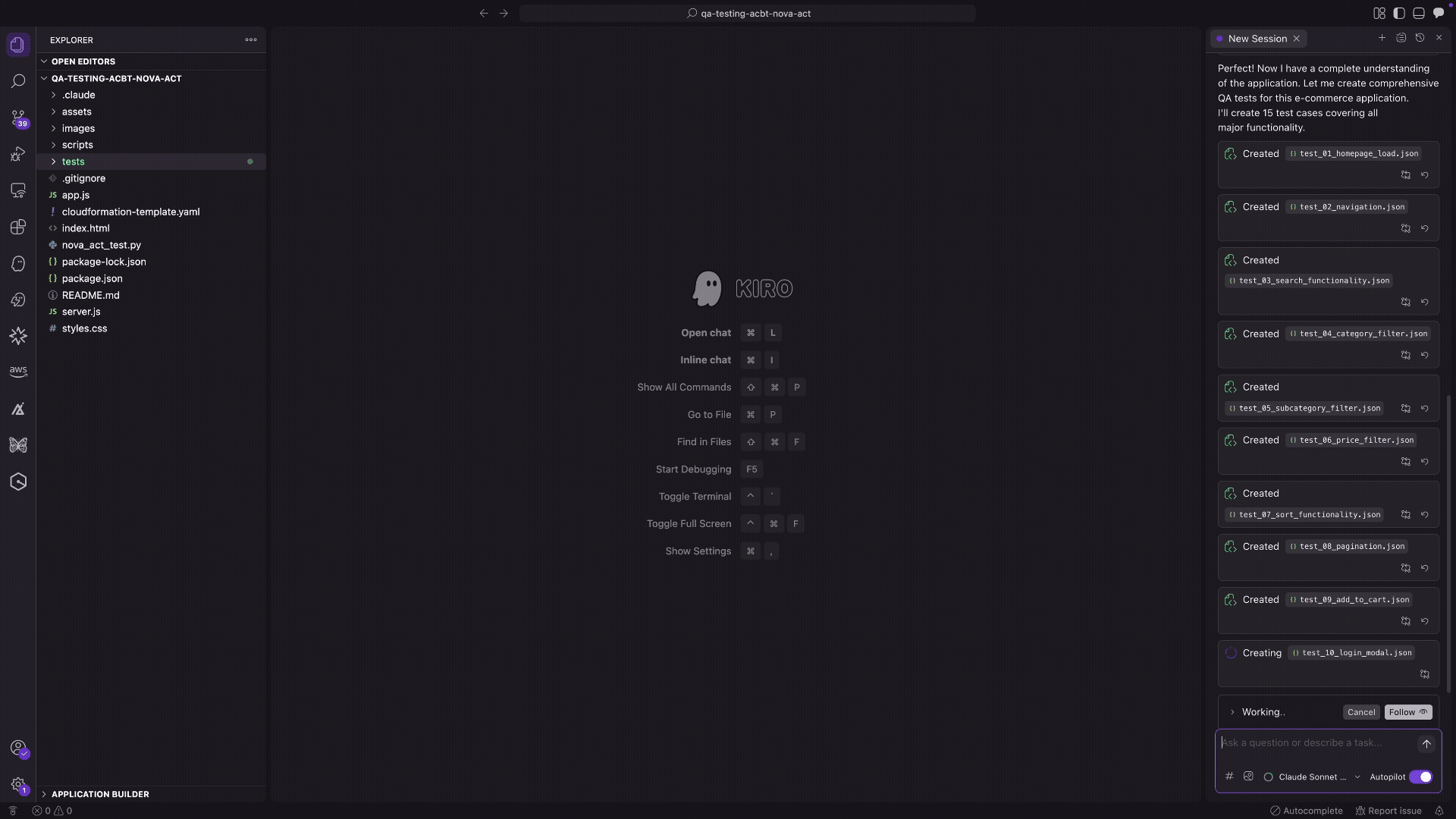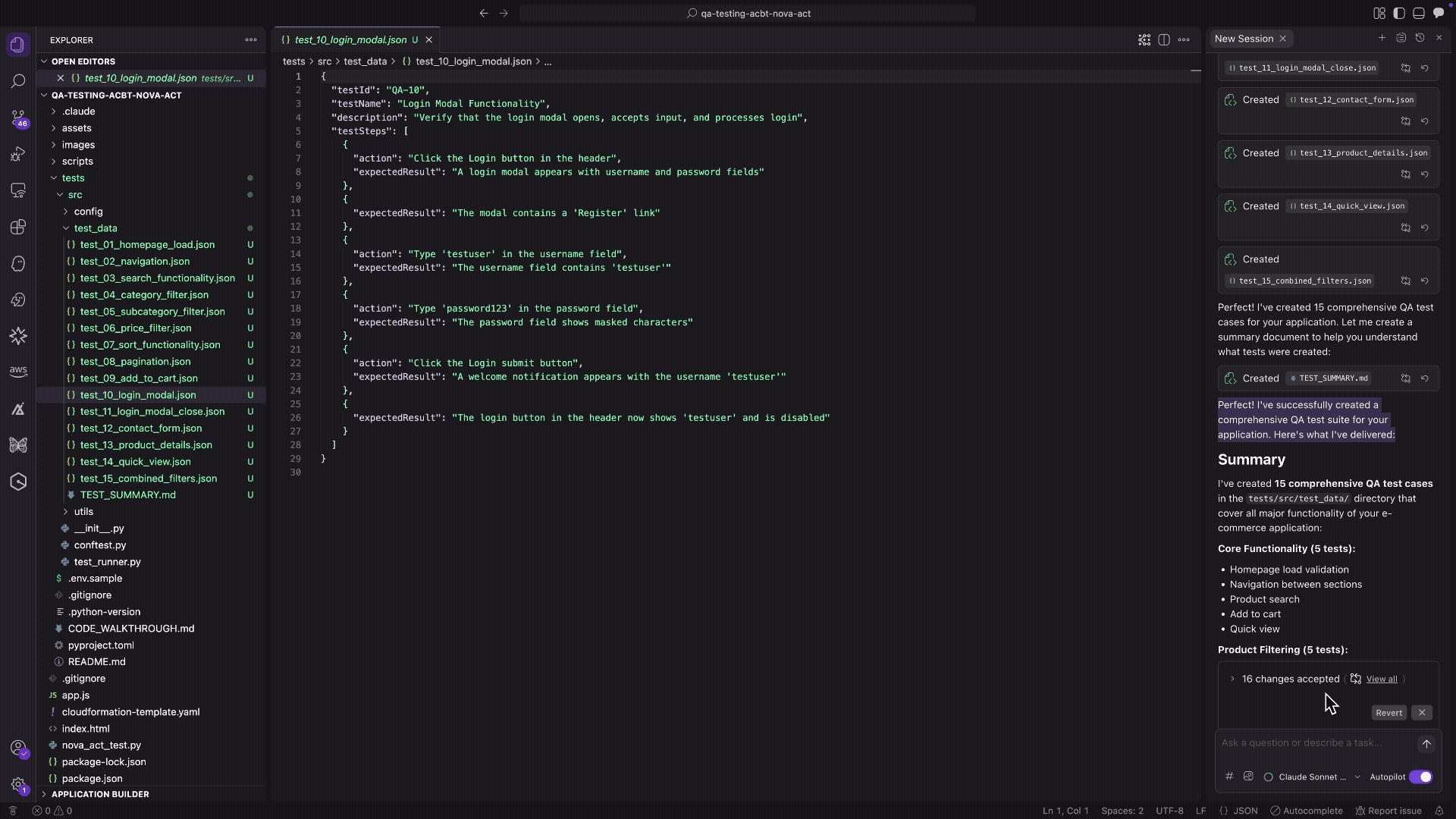
Agentic QA automation using Amazon Bedrock AgentCore Browser and Amazon Nova ActArtificial Intelligence In this post, we explore how agentic QA automation addresses these challenges and walk through a practical example using Amazon Bedrock AgentCore Browser and Amazon Nova Act to automate testing for a sample retail application.
In this post, we explore how agentic QA automation addresses these challenges and walk through a practical example using Amazon Bedrock AgentCore Browser and Amazon Nova Act to automate testing for a sample retail application. Read More
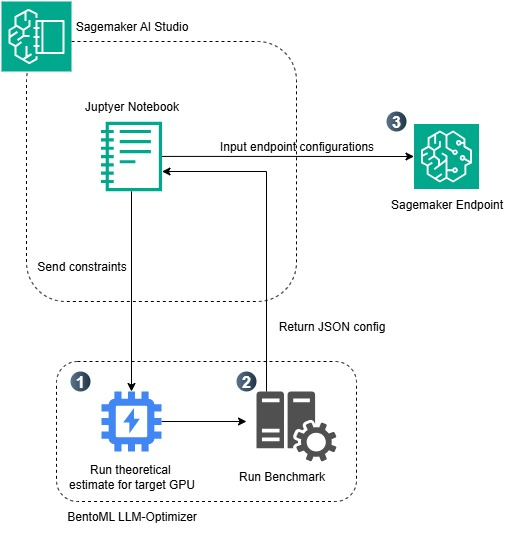
Optimizing LLM inference on Amazon SageMaker AI with BentoML’s LLM- OptimizerArtificial Intelligence In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML’s LLM-Optimizer to systematically identify the best serving configurations for your workload.
In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML’s LLM-Optimizer to systematically identify the best serving configurations for your workload. Read More