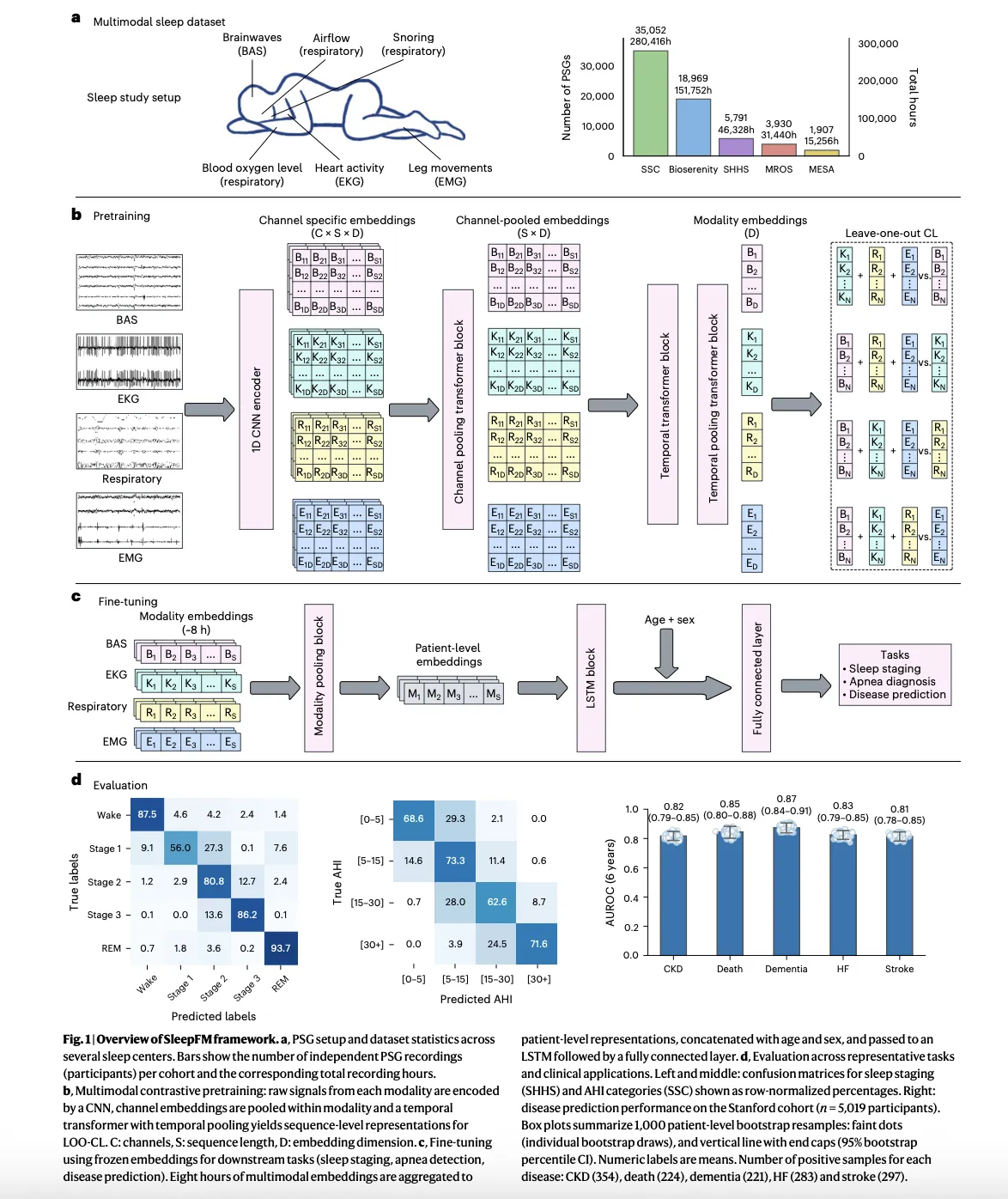
Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease PredictionMarkTechPost A team of Stanford Medicine researchers have introduced SleepFM Clinical, a multimodal sleep foundation model that learns from clinical polysomnography and predicts long term disease risk from a single night of sleep. The research work is published in Nature Medicine and the team has released the clinical code as the open source sleepfm-clinical repository on
The post Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease Prediction appeared first on MarkTechPost.
A team of Stanford Medicine researchers have introduced SleepFM Clinical, a multimodal sleep foundation model that learns from clinical polysomnography and predicts long term disease risk from a single night of sleep. The research work is published in Nature Medicine and the team has released the clinical code as the open source sleepfm-clinical repository on
The post Stanford Researchers Build SleepFM Clinical: A Multimodal Sleep Foundation AI Model for 130+ Disease Prediction appeared first on MarkTechPost. Read More
Powerful Local AI Automations with n8n, MCP and OllamaKDnuggets The ultimate goal is to run these automations on a single workstation or small server, replacing fragile scripts and expensive API-based systems.
The ultimate goal is to run these automations on a single workstation or small server, replacing fragile scripts and expensive API-based systems. Read More

Retrieval for Time-Series: How Looking Back Improves ForecastsTowards Data Science Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science.
Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science. Read More
How to Improve the Performance of Visual Anomaly Detection ModelsTowards Data Science Apply the best methods from academia to get the most out of practical applications
The post How to Improve the Performance of Visual Anomaly Detection Models appeared first on Towards Data Science.
Apply the best methods from academia to get the most out of practical applications
The post How to Improve the Performance of Visual Anomaly Detection Models appeared first on Towards Data Science. Read More

“Dr AI, am I healthy?” 59% of Brits rely on AI for self-diagnosisAI News AI advancements are changing the way we look at health and deal with health-related issues. According to a new nationwide study by Confused.com Life Insurance, three in five Brits now use AI to self-diagnose health conditions. Through various searches, like side effects of medical conditions, treatment options, and symptom checks, as much as 11% of
The post “Dr AI, am I healthy?” 59% of Brits rely on AI for self-diagnosis appeared first on AI News.
AI advancements are changing the way we look at health and deal with health-related issues. According to a new nationwide study by Confused.com Life Insurance, three in five Brits now use AI to self-diagnose health conditions. Through various searches, like side effects of medical conditions, treatment options, and symptom checks, as much as 11% of
The post “Dr AI, am I healthy?” 59% of Brits rely on AI for self-diagnosis appeared first on AI News. Read More

10 Most Popular GitHub Repositories for Learning AIKDnuggets The most popular GitHub repositories to help you learn AI, from fundamentals and math to LLMs, agents, computer vision, and real-world production systems.
The most popular GitHub repositories to help you learn AI, from fundamentals and math to LLMs, agents, computer vision, and real-world production systems. Read More
Netomi’s lessons for scaling agentic systems into the enterpriseOpenAI News How Netomi scales enterprise AI agents using GPT-4.1 and GPT-5.2—combining concurrency, governance, and multi-step reasoning for reliable production workflows.
How Netomi scales enterprise AI agents using GPT-4.1 and GPT-5.2—combining concurrency, governance, and multi-step reasoning for reliable production workflows. Read More
ALERT: Zero-shot LLM Jailbreak Detection via Internal Discrepancy Amplificationcs.AI updates on arXiv.org arXiv:2601.03600v1 Announce Type: cross
Abstract: Despite rich safety alignment strategies, large language models (LLMs) remain highly susceptible to jailbreak attacks, which compromise safety guardrails and pose serious security risks. Existing detection methods mainly detect jailbreak status relying on jailbreak templates present in the training data. However, few studies address the more realistic and challenging zero-shot jailbreak detection setting, where no jailbreak templates are available during training. This setting better reflects real-world scenarios where new attacks continually emerge and evolve. To address this challenge, we propose a layer-wise, module-wise, and token-wise amplification framework that progressively magnifies internal feature discrepancies between benign and jailbreak prompts. We uncover safety-relevant layers, identify specific modules that inherently encode zero-shot discriminative signals, and localize informative safety tokens. Building upon these insights, we introduce ALERT (Amplification-based Jailbreak Detector), an efficient and effective zero-shot jailbreak detector that introduces two independent yet complementary classifiers on amplified representations. Extensive experiments on three safety benchmarks demonstrate that ALERT achieves consistently strong zero-shot detection performance. Specifically, (i) across all datasets and attack strategies, ALERT reliably ranks among the top two methods, and (ii) it outperforms the second-best baseline by at least 10% in average Accuracy and F1-score, and sometimes by up to 40%.
arXiv:2601.03600v1 Announce Type: cross
Abstract: Despite rich safety alignment strategies, large language models (LLMs) remain highly susceptible to jailbreak attacks, which compromise safety guardrails and pose serious security risks. Existing detection methods mainly detect jailbreak status relying on jailbreak templates present in the training data. However, few studies address the more realistic and challenging zero-shot jailbreak detection setting, where no jailbreak templates are available during training. This setting better reflects real-world scenarios where new attacks continually emerge and evolve. To address this challenge, we propose a layer-wise, module-wise, and token-wise amplification framework that progressively magnifies internal feature discrepancies between benign and jailbreak prompts. We uncover safety-relevant layers, identify specific modules that inherently encode zero-shot discriminative signals, and localize informative safety tokens. Building upon these insights, we introduce ALERT (Amplification-based Jailbreak Detector), an efficient and effective zero-shot jailbreak detector that introduces two independent yet complementary classifiers on amplified representations. Extensive experiments on three safety benchmarks demonstrate that ALERT achieves consistently strong zero-shot detection performance. Specifically, (i) across all datasets and attack strategies, ALERT reliably ranks among the top two methods, and (ii) it outperforms the second-best baseline by at least 10% in average Accuracy and F1-score, and sometimes by up to 40%. Read More
Can AI Chatbots Provide Coaching in Engineering? Beyond Information Processing Toward Masterycs.AI updates on arXiv.org arXiv:2601.03693v1 Announce Type: cross
Abstract: Engineering education faces a double disruption: traditional apprenticeship models that cultivated judgment and tacit skill are eroding, just as generative AI emerges as an informal coaching partner. This convergence rekindles long-standing questions in the philosophy of AI and cognition about the limits of computation, the nature of embodied rationality, and the distinction between information processing and wisdom. Building on this rich intellectual tradition, this paper examines whether AI chatbots can provide coaching that fosters mastery rather than merely delivering information. We synthesize critical perspectives from decades of scholarship on expertise, tacit knowledge, and human-machine interaction, situating them within the context of contemporary AI-driven education. Empirically, we report findings from a mixed-methods study (N = 75 students, N = 7 faculty) exploring the use of a coaching chatbot in engineering education. Results reveal a consistent boundary: participants accept AI for technical problem solving (convergent tasks; M = 3.84 on a 1-5 Likert scale) but remain skeptical of its capacity for moral, emotional, and contextual judgment (divergent tasks). Faculty express stronger concerns over risk (M = 4.71 vs. M = 4.14, p = 0.003), and privacy emerges as a key requirement, with 64-71 percent of participants demanding strict confidentiality. Our findings suggest that while generative AI can democratize access to cognitive and procedural support, it cannot replicate the embodied, value-laden dimensions of human mentorship. We propose a multiplex coaching framework that integrates human wisdom within expert-in-the-loop models, preserving the depth of apprenticeship while leveraging AI scalability to enrich the next generation of engineering education.
arXiv:2601.03693v1 Announce Type: cross
Abstract: Engineering education faces a double disruption: traditional apprenticeship models that cultivated judgment and tacit skill are eroding, just as generative AI emerges as an informal coaching partner. This convergence rekindles long-standing questions in the philosophy of AI and cognition about the limits of computation, the nature of embodied rationality, and the distinction between information processing and wisdom. Building on this rich intellectual tradition, this paper examines whether AI chatbots can provide coaching that fosters mastery rather than merely delivering information. We synthesize critical perspectives from decades of scholarship on expertise, tacit knowledge, and human-machine interaction, situating them within the context of contemporary AI-driven education. Empirically, we report findings from a mixed-methods study (N = 75 students, N = 7 faculty) exploring the use of a coaching chatbot in engineering education. Results reveal a consistent boundary: participants accept AI for technical problem solving (convergent tasks; M = 3.84 on a 1-5 Likert scale) but remain skeptical of its capacity for moral, emotional, and contextual judgment (divergent tasks). Faculty express stronger concerns over risk (M = 4.71 vs. M = 4.14, p = 0.003), and privacy emerges as a key requirement, with 64-71 percent of participants demanding strict confidentiality. Our findings suggest that while generative AI can democratize access to cognitive and procedural support, it cannot replicate the embodied, value-laden dimensions of human mentorship. We propose a multiplex coaching framework that integrates human wisdom within expert-in-the-loop models, preserving the depth of apprenticeship while leveraging AI scalability to enrich the next generation of engineering education. Read More
Personalization of Large Foundation Models for Health Interventionscs.AI updates on arXiv.org arXiv:2601.03482v1 Announce Type: new
Abstract: Large foundation models (LFMs) transform healthcare AI in prevention, diagnostics, and treatment. However, whether LFMs can provide truly personalized treatment recommendations remains an open question. Recent research has revealed multiple challenges for personalization, including the fundamental generalizability paradox: models achieving high accuracy in one clinical study perform at chance level in others, demonstrating that personalization and external validity exist in tension. This exemplifies broader contradictions in AI-driven healthcare: the privacy-performance paradox, scale-specificity paradox, and the automation-empathy paradox. As another challenge, the degree of causal understanding required for personalized recommendations, as opposed to mere predictive capacities of LFMs, remains an open question. N-of-1 trials — crossover self-experiments and the gold standard for individual causal inference in personalized medicine — resolve these tensions by providing within-person causal evidence while preserving privacy through local experimentation. Despite their impressive capabilities, this paper argues that LFMs cannot replace N-of-1 trials. We argue that LFMs and N-of-1 trials are complementary: LFMs excel at rapid hypothesis generation from population patterns using multimodal data, while N-of-1 trials excel at causal validation for a given individual. We propose a hybrid framework that combines the strengths of both to enable personalization and navigate the identified paradoxes: LFMs generate ranked intervention candidates with uncertainty estimates, which trigger subsequent N-of-1 trials. Clarifying the boundary between prediction and causation and explicitly addressing the paradoxical tensions are essential for responsible AI integration in personalized medicine.
arXiv:2601.03482v1 Announce Type: new
Abstract: Large foundation models (LFMs) transform healthcare AI in prevention, diagnostics, and treatment. However, whether LFMs can provide truly personalized treatment recommendations remains an open question. Recent research has revealed multiple challenges for personalization, including the fundamental generalizability paradox: models achieving high accuracy in one clinical study perform at chance level in others, demonstrating that personalization and external validity exist in tension. This exemplifies broader contradictions in AI-driven healthcare: the privacy-performance paradox, scale-specificity paradox, and the automation-empathy paradox. As another challenge, the degree of causal understanding required for personalized recommendations, as opposed to mere predictive capacities of LFMs, remains an open question. N-of-1 trials — crossover self-experiments and the gold standard for individual causal inference in personalized medicine — resolve these tensions by providing within-person causal evidence while preserving privacy through local experimentation. Despite their impressive capabilities, this paper argues that LFMs cannot replace N-of-1 trials. We argue that LFMs and N-of-1 trials are complementary: LFMs excel at rapid hypothesis generation from population patterns using multimodal data, while N-of-1 trials excel at causal validation for a given individual. We propose a hybrid framework that combines the strengths of both to enable personalization and navigate the identified paradoxes: LFMs generate ranked intervention candidates with uncertainty estimates, which trigger subsequent N-of-1 trials. Clarifying the boundary between prediction and causation and explicitly addressing the paradoxical tensions are essential for responsible AI integration in personalized medicine. Read More