
Prism: Towards Lowering User Cognitive Load in LLMs via Complex Intent Understandingcs.AI updates on arXiv.org arXiv:2601.08653v1 Announce Type: new
Abstract: Large Language Models are rapidly emerging as web-native interfaces to social platforms. On the social web, users frequently have ambiguous and dynamic goals, making complex intent understanding-rather than single-turn execution-the cornerstone of effective human-LLM collaboration. Existing approaches attempt to clarify user intents through sequential or parallel questioning, yet they fall short of addressing the core challenge: modeling the logical dependencies among clarification questions. Inspired by the Cognitive Load Theory, we propose Prism, a novel framework for complex intent understanding that enables logically coherent and efficient intent clarification. Prism comprises four tailored modules: a complex intent decomposition module, which decomposes user intents into smaller, well-structured elements and identifies logical dependencies among them; a logical clarification generation module, which organizes clarification questions based on these dependencies to ensure coherent, low-friction interactions; an intent-aware reward module, which evaluates the quality of clarification trajectories via an intent-aware reward function and leverages Monte Carlo Sample to simulate user-LLM interactions for large-scale,high-quality training data generation; and a self-evolved intent tuning module, which iteratively refines the LLM’s logical clarification capability through data-driven feedback and optimization. Prism consistently outperforms existing approaches across clarification interactions, intent execution, and cognitive load benchmarks. It achieves stateof-the-art logical consistency, reduces logical conflicts to 11.5%, increases user satisfaction by 14.4%, and decreases task completion time by 34.8%. All data and code are released.
arXiv:2601.08653v1 Announce Type: new
Abstract: Large Language Models are rapidly emerging as web-native interfaces to social platforms. On the social web, users frequently have ambiguous and dynamic goals, making complex intent understanding-rather than single-turn execution-the cornerstone of effective human-LLM collaboration. Existing approaches attempt to clarify user intents through sequential or parallel questioning, yet they fall short of addressing the core challenge: modeling the logical dependencies among clarification questions. Inspired by the Cognitive Load Theory, we propose Prism, a novel framework for complex intent understanding that enables logically coherent and efficient intent clarification. Prism comprises four tailored modules: a complex intent decomposition module, which decomposes user intents into smaller, well-structured elements and identifies logical dependencies among them; a logical clarification generation module, which organizes clarification questions based on these dependencies to ensure coherent, low-friction interactions; an intent-aware reward module, which evaluates the quality of clarification trajectories via an intent-aware reward function and leverages Monte Carlo Sample to simulate user-LLM interactions for large-scale,high-quality training data generation; and a self-evolved intent tuning module, which iteratively refines the LLM’s logical clarification capability through data-driven feedback and optimization. Prism consistently outperforms existing approaches across clarification interactions, intent execution, and cognitive load benchmarks. It achieves stateof-the-art logical consistency, reduces logical conflicts to 11.5%, increases user satisfaction by 14.4%, and decreases task completion time by 34.8%. All data and code are released. Read More
NOVAK: Unified adaptive optimizer for deep neural networkscs.AI updates on arXiv.org arXiv:2601.07876v1 Announce Type: cross
Abstract: This work introduces NOVAK, a modular gradient-based optimization algorithm that integrates adaptive moment estimation, rectified learning-rate scheduling, decoupled weight regularization, multiple variants of Nesterov momentum, and lookahead synchronization into a unified, performance-oriented framework. NOVAK adopts a dual-mode architecture consisting of a streamlined fast path designed for production. The optimizer employs custom CUDA kernels that deliver substantial speedups (3-5 for critical operations) while preserving numerical stability under standard stochastic-optimization assumptions. We provide fully developed mathematical formulations for rectified adaptive learning rates, a memory-efficient lookahead mechanism that reduces overhead from O(2p) to O(p + p/k), and the synergistic coupling of complementary optimization components. Theoretical analysis establishes convergence guarantees and elucidates the stability and variance-reduction properties of the method. Extensive empirical evaluation on CIFAR-10, CIFAR-100, ImageNet, and ImageNette demonstrates NOVAK superiority over 14 contemporary optimizers, including Adam, AdamW, RAdam, Lion, and Adan. Across architectures such as ResNet-50, VGG-16, and ViT, NOVAK consistently achieves state-of-the-art accuracy, and exceptional robustness, attaining very high accuracy on VGG-16/ImageNette demonstrating superior architectural robustness compared to contemporary optimizers. The results highlight that NOVAKs architectural contributions (particularly rectification, decoupled decay, and hybrid momentum) are crucial for reliable training of deep plain networks lacking skip connections, addressing a long-standing limitation of existing adaptive optimization methods.
arXiv:2601.07876v1 Announce Type: cross
Abstract: This work introduces NOVAK, a modular gradient-based optimization algorithm that integrates adaptive moment estimation, rectified learning-rate scheduling, decoupled weight regularization, multiple variants of Nesterov momentum, and lookahead synchronization into a unified, performance-oriented framework. NOVAK adopts a dual-mode architecture consisting of a streamlined fast path designed for production. The optimizer employs custom CUDA kernels that deliver substantial speedups (3-5 for critical operations) while preserving numerical stability under standard stochastic-optimization assumptions. We provide fully developed mathematical formulations for rectified adaptive learning rates, a memory-efficient lookahead mechanism that reduces overhead from O(2p) to O(p + p/k), and the synergistic coupling of complementary optimization components. Theoretical analysis establishes convergence guarantees and elucidates the stability and variance-reduction properties of the method. Extensive empirical evaluation on CIFAR-10, CIFAR-100, ImageNet, and ImageNette demonstrates NOVAK superiority over 14 contemporary optimizers, including Adam, AdamW, RAdam, Lion, and Adan. Across architectures such as ResNet-50, VGG-16, and ViT, NOVAK consistently achieves state-of-the-art accuracy, and exceptional robustness, attaining very high accuracy on VGG-16/ImageNette demonstrating superior architectural robustness compared to contemporary optimizers. The results highlight that NOVAKs architectural contributions (particularly rectification, decoupled decay, and hybrid momentum) are crucial for reliable training of deep plain networks lacking skip connections, addressing a long-standing limitation of existing adaptive optimization methods. Read More
Sherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsificationcs.AI updates on arXiv.org arXiv:2601.07892v1 Announce Type: cross
Abstract: The deployment of Large Language Models (LLMs) on resource-constrained edge devices is increasingly hindered by prohibitive memory and computational requirements. While ternary quantization offers a compelling solution by reducing weights to {-1, 0, +1}, current implementations suffer from a fundamental misalignment with commodity hardware. Most existing methods must choose between 2-bit aligned packing, which incurs significant bit wastage, or 1.67-bit irregular packing, which degrades inference speed. To resolve this tension, we propose Sherry, a hardware-efficient ternary quantization framework. Sherry introduces a 3:4 fine-grained sparsity that achieves a regularized 1.25-bit width by packing blocks of four weights into five bits, restoring power-of-two alignment. Furthermore, we identify weight trapping issue in sparse ternary training, which leads to representational collapse. To address this, Sherry introduces Arenas, an annealing residual synapse mechanism that maintains representational diversity during training. Empirical evaluations on LLaMA-3.2 across five benchmarks demonstrate that Sherry matches state-of-the-art ternary performance while significantly reducing model size. Notably, on an Intel i7-14700HX CPU, our 1B model achieves zero accuracy loss compared to SOTA baselines while providing 25% bit savings and 10% speed up. The code is available at https://github.com/Tencent/AngelSlim .
arXiv:2601.07892v1 Announce Type: cross
Abstract: The deployment of Large Language Models (LLMs) on resource-constrained edge devices is increasingly hindered by prohibitive memory and computational requirements. While ternary quantization offers a compelling solution by reducing weights to {-1, 0, +1}, current implementations suffer from a fundamental misalignment with commodity hardware. Most existing methods must choose between 2-bit aligned packing, which incurs significant bit wastage, or 1.67-bit irregular packing, which degrades inference speed. To resolve this tension, we propose Sherry, a hardware-efficient ternary quantization framework. Sherry introduces a 3:4 fine-grained sparsity that achieves a regularized 1.25-bit width by packing blocks of four weights into five bits, restoring power-of-two alignment. Furthermore, we identify weight trapping issue in sparse ternary training, which leads to representational collapse. To address this, Sherry introduces Arenas, an annealing residual synapse mechanism that maintains representational diversity during training. Empirical evaluations on LLaMA-3.2 across five benchmarks demonstrate that Sherry matches state-of-the-art ternary performance while significantly reducing model size. Notably, on an Intel i7-14700HX CPU, our 1B model achieves zero accuracy loss compared to SOTA baselines while providing 25% bit savings and 10% speed up. The code is available at https://github.com/Tencent/AngelSlim . Read More
FinVault: Benchmarking Financial Agent Safety in Execution-Grounded Environmentscs.AI updates on arXiv.org arXiv:2601.07853v1 Announce Type: cross
Abstract: Financial agents powered by large language models (LLMs) are increasingly deployed for investment analysis, risk assessment, and automated decision-making, where their abilities to plan, invoke tools, and manipulate mutable state introduce new security risks in high-stakes and highly regulated financial environments. However, existing safety evaluations largely focus on language-model-level content compliance or abstract agent settings, failing to capture execution-grounded risks arising from real operational workflows and state-changing actions. To bridge this gap, we propose FinVault, the first execution-grounded security benchmark for financial agents, comprising 31 regulatory case-driven sandbox scenarios with state-writable databases and explicit compliance constraints, together with 107 real-world vulnerabilities and 963 test cases that systematically cover prompt injection, jailbreaking, financially adapted attacks, as well as benign inputs for false-positive evaluation. Experimental results reveal that existing defense mechanisms remain ineffective in realistic financial agent settings, with average attack success rates (ASR) still reaching up to 50.0% on state-of-the-art models and remaining non-negligible even for the most robust systems (ASR 6.7%), highlighting the limited transferability of current safety designs and the need for stronger financial-specific defenses. Our code can be found at https://github.com/aifinlab/FinVault.
arXiv:2601.07853v1 Announce Type: cross
Abstract: Financial agents powered by large language models (LLMs) are increasingly deployed for investment analysis, risk assessment, and automated decision-making, where their abilities to plan, invoke tools, and manipulate mutable state introduce new security risks in high-stakes and highly regulated financial environments. However, existing safety evaluations largely focus on language-model-level content compliance or abstract agent settings, failing to capture execution-grounded risks arising from real operational workflows and state-changing actions. To bridge this gap, we propose FinVault, the first execution-grounded security benchmark for financial agents, comprising 31 regulatory case-driven sandbox scenarios with state-writable databases and explicit compliance constraints, together with 107 real-world vulnerabilities and 963 test cases that systematically cover prompt injection, jailbreaking, financially adapted attacks, as well as benign inputs for false-positive evaluation. Experimental results reveal that existing defense mechanisms remain ineffective in realistic financial agent settings, with average attack success rates (ASR) still reaching up to 50.0% on state-of-the-art models and remaining non-negligible even for the most robust systems (ASR 6.7%), highlighting the limited transferability of current safety designs and the need for stronger financial-specific defenses. Our code can be found at https://github.com/aifinlab/FinVault. Read More
Uncovering Political Bias in Large Language Models using Parliamentary Voting Recordscs.AI updates on arXiv.org arXiv:2601.08785v1 Announce Type: new
Abstract: As large language models (LLMs) become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs.
arXiv:2601.08785v1 Announce Type: new
Abstract: As large language models (LLMs) become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs. Read More
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thoughtcs.AI updates on arXiv.org arXiv:2601.08108v1 Announce Type: cross
Abstract: Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
arXiv:2601.08108v1 Announce Type: cross
Abstract: Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency. Read More
Enhancing Large Language Models for Time-Series Forecasting via Vector-Injected In-Context Learningcs.AI updates on arXiv.org arXiv:2601.07903v2 Announce Type: cross
Abstract: The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach.
arXiv:2601.07903v2 Announce Type: cross
Abstract: The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach. Read More
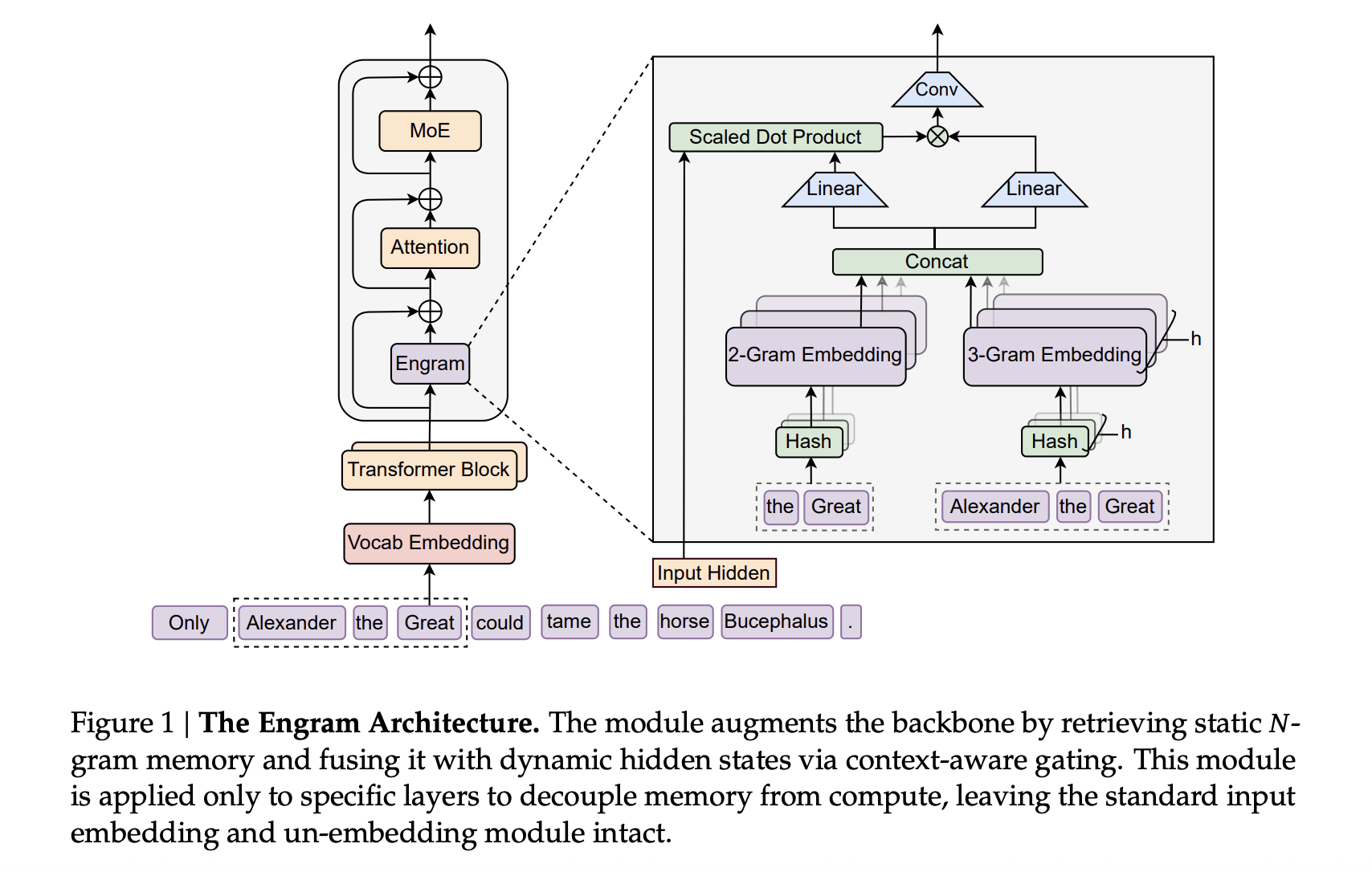
DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMsMarkTechPost Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost.
Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost. Read More

Transform AI development with new Amazon SageMaker AI model customization and large-scale training capabilitiesArtificial Intelligence This post explores how new serverless model customization capabilities, elastic training, checkpointless training, and serverless MLflow work together to accelerate your AI development from months to days.
This post explores how new serverless model customization capabilities, elastic training, checkpointless training, and serverless MLflow work together to accelerate your AI development from months to days. Read More
How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent WorkflowsMarkTechPost In this tutorial, we build a clean, advanced demonstration of modern MCP design by focusing on three core ideas: stateless communication, strict SDK-level validation, and asynchronous, long-running operations. We implement a minimal MCP-like protocol using structured envelopes, signed requests, and Pydantic-validated tools to show how agents and services can interact safely without relying on persistent
The post How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent Workflows appeared first on MarkTechPost.
In this tutorial, we build a clean, advanced demonstration of modern MCP design by focusing on three core ideas: stateless communication, strict SDK-level validation, and asynchronous, long-running operations. We implement a minimal MCP-like protocol using structured envelopes, signed requests, and Pydantic-validated tools to show how agents and services can interact safely without relying on persistent
The post How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent Workflows appeared first on MarkTechPost. Read More