
Safety Not Found (404): Hidden Risks of LLM-Based Robotics Decision Makingcs.AI updates on arXiv.org arXiv:2601.05529v2 Announce Type: replace
Abstract: One mistake by an AI system in a safety-critical setting can cost lives. As Large Language Models (LLMs) become integral to robotics decision-making, the physical dimension of risk grows; a single wrong instruction can directly endanger human safety. This paper addresses the urgent need to systematically evaluate LLM performance in scenarios where even minor errors are catastrophic. Through a qualitative evaluation of a fire evacuation scenario, we identified critical failure cases in LLM-based decision-making. Based on these, we designed seven tasks for quantitative assessment, categorized into: Complete Information, Incomplete Information, and Safety-Oriented Spatial Reasoning (SOSR). Complete information tasks utilize ASCII maps to minimize interpretation ambiguity and isolate spatial reasoning from visual processing. Incomplete information tasks require models to infer missing context, testing for spatial continuity versus hallucinations. SOSR tasks use natural language to evaluate safe decision-making in life-threatening contexts. We benchmark various LLMs and Vision-Language Models (VLMs) across these tasks. Beyond aggregate performance, we analyze the implications of a 1% failure rate, highlighting how “rare” errors escalate into catastrophic outcomes. Results reveal serious vulnerabilities: several models achieved a 0% success rate in ASCII navigation, while in a simulated fire drill, models instructed robots to move toward hazardous areas instead of emergency exits. Our findings lead to a sobering conclusion: current LLMs are not ready for direct deployment in safety-critical systems. A 99% accuracy rate is dangerously misleading in robotics, as it implies one out of every hundred executions could result in catastrophic harm. We demonstrate that even state-of-the-art models cannot guarantee safety, and absolute reliance on them creates unacceptable risks.
arXiv:2601.05529v2 Announce Type: replace
Abstract: One mistake by an AI system in a safety-critical setting can cost lives. As Large Language Models (LLMs) become integral to robotics decision-making, the physical dimension of risk grows; a single wrong instruction can directly endanger human safety. This paper addresses the urgent need to systematically evaluate LLM performance in scenarios where even minor errors are catastrophic. Through a qualitative evaluation of a fire evacuation scenario, we identified critical failure cases in LLM-based decision-making. Based on these, we designed seven tasks for quantitative assessment, categorized into: Complete Information, Incomplete Information, and Safety-Oriented Spatial Reasoning (SOSR). Complete information tasks utilize ASCII maps to minimize interpretation ambiguity and isolate spatial reasoning from visual processing. Incomplete information tasks require models to infer missing context, testing for spatial continuity versus hallucinations. SOSR tasks use natural language to evaluate safe decision-making in life-threatening contexts. We benchmark various LLMs and Vision-Language Models (VLMs) across these tasks. Beyond aggregate performance, we analyze the implications of a 1% failure rate, highlighting how “rare” errors escalate into catastrophic outcomes. Results reveal serious vulnerabilities: several models achieved a 0% success rate in ASCII navigation, while in a simulated fire drill, models instructed robots to move toward hazardous areas instead of emergency exits. Our findings lead to a sobering conclusion: current LLMs are not ready for direct deployment in safety-critical systems. A 99% accuracy rate is dangerously misleading in robotics, as it implies one out of every hundred executions could result in catastrophic harm. We demonstrate that even state-of-the-art models cannot guarantee safety, and absolute reliance on them creates unacceptable risks. Read More

Retailers bring conversational AI and analytics closer to the userAI News After years of experimentation with artificial intelligence, retailers are striving to embed consumer insight directly into everyday commercial decisions. First Insight, a US-based analytics company specialising in predictive consumer feedback, argues that the next phase of retail AI should be epitomised by dialogue, not dashboards. Following a three-month beta programme, First Insight has made its
The post Retailers bring conversational AI and analytics closer to the user appeared first on AI News.
After years of experimentation with artificial intelligence, retailers are striving to embed consumer insight directly into everyday commercial decisions. First Insight, a US-based analytics company specialising in predictive consumer feedback, argues that the next phase of retail AI should be epitomised by dialogue, not dashboards. Following a three-month beta programme, First Insight has made its
The post Retailers bring conversational AI and analytics closer to the user appeared first on AI News. Read More

Top 5 Open-Source AI Model API ProvidersKDnuggets Large open-source language models are now widely accessible, and this article compares leading AI API providers on performance, pricing, latency, and real-world reliability to help you choose the right option.
Large open-source language models are now widely accessible, and this article compares leading AI API providers on performance, pricing, latency, and real-world reliability to help you choose the right option. Read More
Banks operationalise as Plumery AI launches standardised integrationAI News A new technology from digital banking platform Plumery AI aims to address a dilemma for financial institutions: how to move beyond proofs of concept and embed artificial intelligence into everyday banking operations without compromising governance, security, or regulatory compliance. Plumery’s “AI Fabric” has been positioned by the company as a standardised framework for connecting generative
The post Banks operationalise as Plumery AI launches standardised integration appeared first on AI News.
A new technology from digital banking platform Plumery AI aims to address a dilemma for financial institutions: how to move beyond proofs of concept and embed artificial intelligence into everyday banking operations without compromising governance, security, or regulatory compliance. Plumery’s “AI Fabric” has been positioned by the company as a standardised framework for connecting generative
The post Banks operationalise as Plumery AI launches standardised integration appeared first on AI News. Read More
Parallel Test-Time Scaling for Latent Reasoning Modelscs.AI updates on arXiv.org arXiv:2510.07745v3 Announce Type: replace-cross
Abstract: Parallel test-time scaling (TTS) is a pivotal approach for enhancing large language models (LLMs), typically by sampling multiple token-based chains-of-thought in parallel and aggregating outcomes through voting or search. Recent advances in latent reasoning, where intermediate reasoning unfolds in continuous vector spaces, offer a more efficient alternative to explicit Chain-of-Thought, yet whether such latent models can similarly benefit from parallel TTS remains open, mainly due to the absence of sampling mechanisms in continuous space, and the lack of probabilistic signals for advanced trajectory aggregation. This work enables parallel TTS for latent reasoning models by addressing the above issues. For sampling, we introduce two uncertainty-inspired stochastic strategies: Monte Carlo Dropout and Additive Gaussian Noise. For aggregation, we design a Latent Reward Model (LatentRM) trained with step-wise contrastive objective to score and guide latent reasoning. Extensive experiments and visualization analyses show that both sampling strategies scale effectively with compute and exhibit distinct exploration dynamics, while LatentRM enables effective trajectory selection. Together, our explorations open a new direction for scalable inference in continuous spaces. Code and checkpoints released at https://github.com/ModalityDance/LatentTTS
arXiv:2510.07745v3 Announce Type: replace-cross
Abstract: Parallel test-time scaling (TTS) is a pivotal approach for enhancing large language models (LLMs), typically by sampling multiple token-based chains-of-thought in parallel and aggregating outcomes through voting or search. Recent advances in latent reasoning, where intermediate reasoning unfolds in continuous vector spaces, offer a more efficient alternative to explicit Chain-of-Thought, yet whether such latent models can similarly benefit from parallel TTS remains open, mainly due to the absence of sampling mechanisms in continuous space, and the lack of probabilistic signals for advanced trajectory aggregation. This work enables parallel TTS for latent reasoning models by addressing the above issues. For sampling, we introduce two uncertainty-inspired stochastic strategies: Monte Carlo Dropout and Additive Gaussian Noise. For aggregation, we design a Latent Reward Model (LatentRM) trained with step-wise contrastive objective to score and guide latent reasoning. Extensive experiments and visualization analyses show that both sampling strategies scale effectively with compute and exhibit distinct exploration dynamics, while LatentRM enables effective trajectory selection. Together, our explorations open a new direction for scalable inference in continuous spaces. Code and checkpoints released at https://github.com/ModalityDance/LatentTTS Read More
From RGB to Lab: Addressing Color Artifacts in AI Image CompositingTowards Data Science A multi-tier approach to segmentation, color correction, and domain-specific enhancement
The post From RGB to Lab: Addressing Color Artifacts in AI Image Compositing appeared first on Towards Data Science.
A multi-tier approach to segmentation, color correction, and domain-specific enhancement
The post From RGB to Lab: Addressing Color Artifacts in AI Image Compositing appeared first on Towards Data Science. Read More
The Great Data Closure: Why Databricks and Snowflake Are Hitting Their CeilingTowards Data Science Acquisitions, venture, and an increasingly competitive landscape all point to a market ceiling
The post The Great Data Closure: Why Databricks and Snowflake Are Hitting Their Ceiling appeared first on Towards Data Science.
Acquisitions, venture, and an increasingly competitive landscape all point to a market ceiling
The post The Great Data Closure: Why Databricks and Snowflake Are Hitting Their Ceiling appeared first on Towards Data Science. Read More
How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop ControlsMarkTechPost In this tutorial, we demonstrate how an autonomous, agentic AI system can simulate the end-to-end prior authorization workflow within healthcare Revenue Cycle Management (RCM). We show how an agent continuously monitors incoming surgery orders, gathers the required clinical documentation, submits prior authorization requests to payer systems, tracks their status, and intelligently responds to denials through
The post How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop Controls appeared first on MarkTechPost.
In this tutorial, we demonstrate how an autonomous, agentic AI system can simulate the end-to-end prior authorization workflow within healthcare Revenue Cycle Management (RCM). We show how an agent continuously monitors incoming surgery orders, gathers the required clinical documentation, submits prior authorization requests to payer systems, tracks their status, and intelligently responds to denials through
The post How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop Controls appeared first on MarkTechPost. Read More
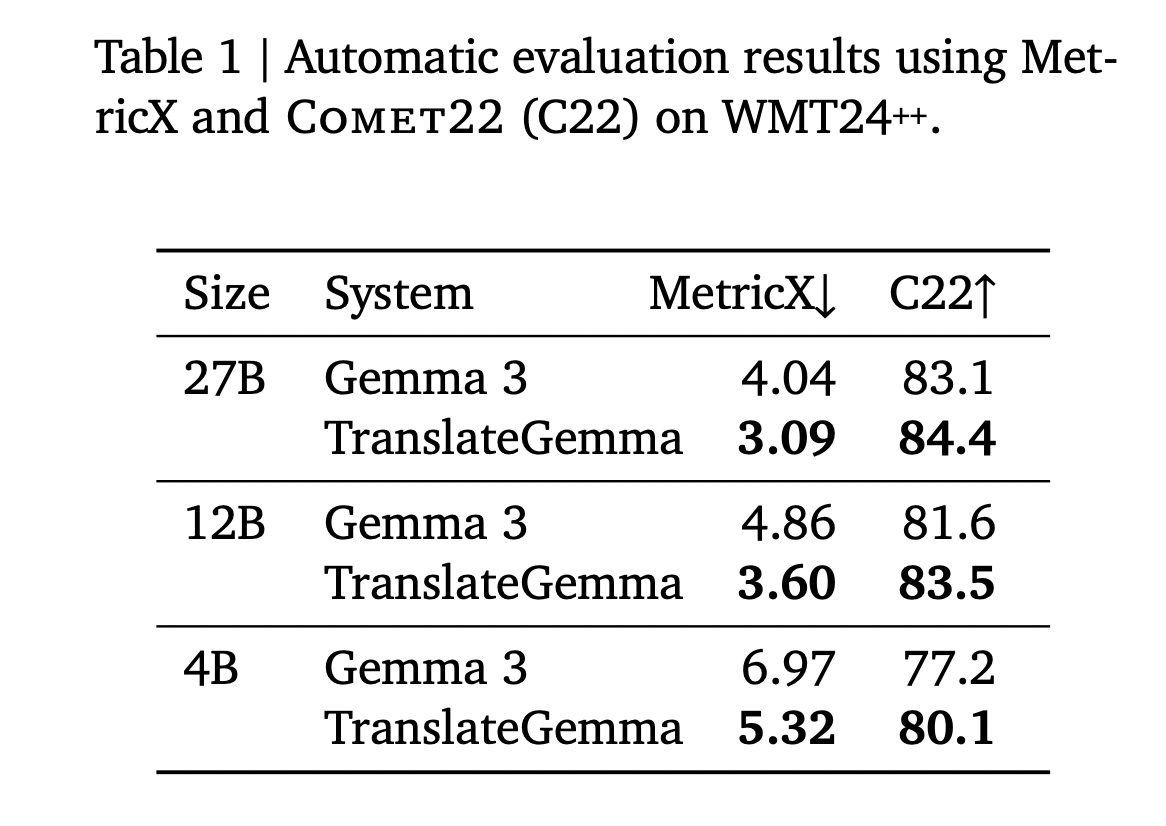
Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 LanguagesMarkTechPost Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 languages. The family comes in 4B, 12B and 27B parameter sizes. It is designed to run across devices from mobile and edge hardware to laptops and a single H100 GPU or TPU instance in the
The post Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages appeared first on MarkTechPost.
Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 languages. The family comes in 4B, 12B and 27B parameter sizes. It is designed to run across devices from mobile and edge hardware to laptops and a single H100 GPU or TPU instance in the
The post Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages appeared first on MarkTechPost. Read More

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated January 15th, 2026 Hello Everyone, Help us grow our community by sharing and/or supporting us on other platforms. This allow us to show verification that what we are doing is valued. It also allows us to plan and […]