
SC25 showcases the next phase of Dell and NVIDIA’s AI partnershipAI News At SC25, Dell Technologies and NVIDIA introduced new updates to their joint AI platform, aiming to make it easier for organisations to run a wider range of AI workloads, from older models to newer agent-style systems. As more companies scale their AI plans, many run into the same issues. They need to manage a growing
The post SC25 showcases the next phase of Dell and NVIDIA’s AI partnership appeared first on AI News.
At SC25, Dell Technologies and NVIDIA introduced new updates to their joint AI platform, aiming to make it easier for organisations to run a wider range of AI workloads, from older models to newer agent-style systems. As more companies scale their AI plans, many run into the same issues. They need to manage a growing
The post SC25 showcases the next phase of Dell and NVIDIA’s AI partnership appeared first on AI News. Read More
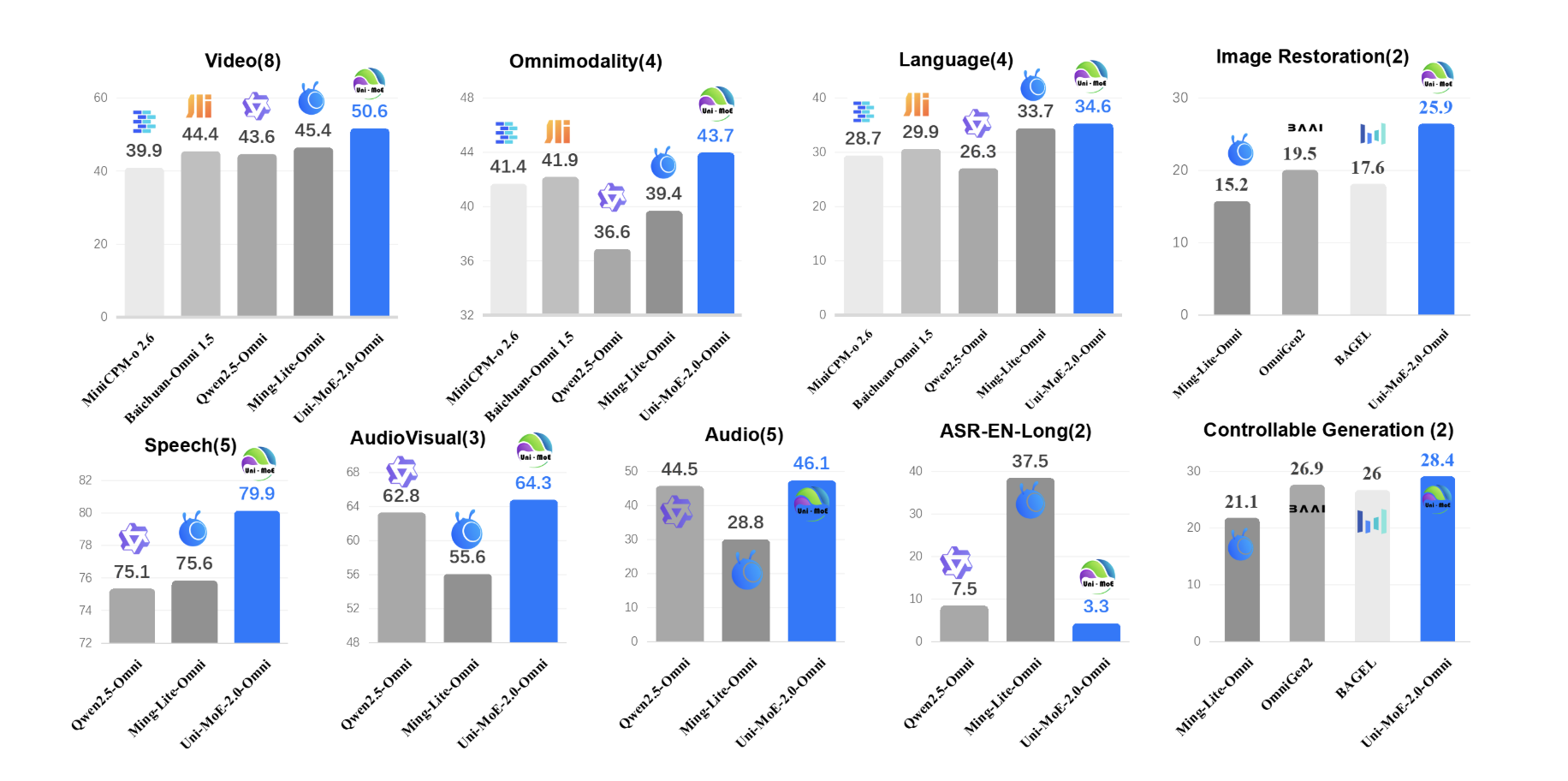
Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video UnderstandingMarkTechPost How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on
The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost.
How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on
The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost. Read More

Build or Buy Your Cybersecurity? Weighing the Pros and Cons (Sponsored)KDnuggets The new million-dollar question for cybersecurity doesn’t have anything to do with fending off the latest type of attack or adopting yet another AI-powered tool.
The new million-dollar question for cybersecurity doesn’t have anything to do with fending off the latest type of attack or adopting yet another AI-powered tool. Read More

AI web search risks: Mitigating business data accuracy threatsAI News Over half of us now use AI to search the web, yet the stubbornly low data accuracy of common tools creates new business risks. While generative AI (GenAI) offers undeniable efficiency gains, a new investigation highlights a disparity between user trust and technical accuracy that poses specific risks to corporate compliance, legal standing, and financial
The post AI web search risks: Mitigating business data accuracy threats appeared first on AI News.
Over half of us now use AI to search the web, yet the stubbornly low data accuracy of common tools creates new business risks. While generative AI (GenAI) offers undeniable efficiency gains, a new investigation highlights a disparity between user trust and technical accuracy that poses specific risks to corporate compliance, legal standing, and financial
The post AI web search risks: Mitigating business data accuracy threats appeared first on AI News. Read More

Introducing Google’s File Search ToolTowards Data Science The search giant fires its latest salvo against traditional RAG processing.
The post Introducing Google’s File Search Tool appeared first on Towards Data Science.
The search giant fires its latest salvo against traditional RAG processing.
The post Introducing Google’s File Search Tool appeared first on Towards Data Science. Read More
Refine and Align: Confidence Calibration through Multi-Agent Interaction in VQAcs.AI updates on arXiv.org arXiv:2511.11169v1 Announce Type: cross
Abstract: In the context of Visual Question Answering (VQA) and Agentic AI, calibration refers to how closely an AI system’s confidence in its answers reflects their actual correctness. This aspect becomes especially important when such systems operate autonomously and must make decisions under visual uncertainty. While modern VQA systems, powered by advanced vision-language models (VLMs), are increasingly used in high-stakes domains like medical diagnostics and autonomous navigation due to their improved accuracy, the reliability of their confidence estimates remains under-examined. Particularly, these systems often produce overconfident responses. To address this, we introduce AlignVQA, a debate-based multi-agent framework, in which diverse specialized VLM — each following distinct prompting strategies — generate candidate answers and then engage in two-stage interaction: generalist agents critique, refine and aggregate these proposals. This debate process yields confidence estimates that more accurately reflect the model’s true predictive performance. We find that more calibrated specialized agents produce better aligned confidences. Furthermore, we introduce a novel differentiable calibration-aware loss function called aligncal designed to fine-tune the specialized agents by minimizing an upper bound on the calibration error. This objective explicitly improves the fidelity of each agent’s confidence estimates. Empirical results across multiple benchmark VQA datasets substantiate the efficacy of our approach, demonstrating substantial reductions in calibration discrepancies. Furthermore, we propose a novel differentiable calibration-aware loss to fine-tune the specialized agents and improve the quality of their individual confidence estimates based on minimising upper bound calibration error.
arXiv:2511.11169v1 Announce Type: cross
Abstract: In the context of Visual Question Answering (VQA) and Agentic AI, calibration refers to how closely an AI system’s confidence in its answers reflects their actual correctness. This aspect becomes especially important when such systems operate autonomously and must make decisions under visual uncertainty. While modern VQA systems, powered by advanced vision-language models (VLMs), are increasingly used in high-stakes domains like medical diagnostics and autonomous navigation due to their improved accuracy, the reliability of their confidence estimates remains under-examined. Particularly, these systems often produce overconfident responses. To address this, we introduce AlignVQA, a debate-based multi-agent framework, in which diverse specialized VLM — each following distinct prompting strategies — generate candidate answers and then engage in two-stage interaction: generalist agents critique, refine and aggregate these proposals. This debate process yields confidence estimates that more accurately reflect the model’s true predictive performance. We find that more calibrated specialized agents produce better aligned confidences. Furthermore, we introduce a novel differentiable calibration-aware loss function called aligncal designed to fine-tune the specialized agents by minimizing an upper bound on the calibration error. This objective explicitly improves the fidelity of each agent’s confidence estimates. Empirical results across multiple benchmark VQA datasets substantiate the efficacy of our approach, demonstrating substantial reductions in calibration discrepancies. Furthermore, we propose a novel differentiable calibration-aware loss to fine-tune the specialized agents and improve the quality of their individual confidence estimates based on minimising upper bound calibration error. Read More
Automated Analysis of Learning Outcomes and Exam Questions Based on Bloom’s Taxonomycs.AI updates on arXiv.org arXiv:2511.10903v1 Announce Type: cross
Abstract: This paper explores the automatic classification of exam questions and learning outcomes according to Bloom’s Taxonomy. A small dataset of 600 sentences labeled with six cognitive categories – Knowledge, Comprehension, Application, Analysis, Synthesis, and Evaluation – was processed using traditional machine learning (ML) models (Naive Bayes, Logistic Regression, Support Vector Machines), recurrent neural network architectures (LSTM, BiLSTM, GRU, BiGRU), transformer-based models (BERT and RoBERTa), and large language models (OpenAI, Gemini, Ollama, Anthropic). Each model was evaluated under different preprocessing and augmentation strategies (for example, synonym replacement, word embeddings, etc.). Among traditional ML approaches, Support Vector Machines (SVM) with data augmentation achieved the best overall performance, reaching 94 percent accuracy, recall, and F1 scores with minimal overfitting. In contrast, the RNN models and BERT suffered from severe overfitting, while RoBERTa initially overcame it but began to show signs as training progressed. Finally, zero-shot evaluations of large language models (LLMs) indicated that OpenAI and Gemini performed best among the tested LLMs, achieving approximately 0.72-0.73 accuracy and comparable F1 scores. These findings highlight the challenges of training complex deep models on limited data and underscore the value of careful data augmentation and simpler algorithms (such as augmented SVM) for Bloom’s Taxonomy classification.
arXiv:2511.10903v1 Announce Type: cross
Abstract: This paper explores the automatic classification of exam questions and learning outcomes according to Bloom’s Taxonomy. A small dataset of 600 sentences labeled with six cognitive categories – Knowledge, Comprehension, Application, Analysis, Synthesis, and Evaluation – was processed using traditional machine learning (ML) models (Naive Bayes, Logistic Regression, Support Vector Machines), recurrent neural network architectures (LSTM, BiLSTM, GRU, BiGRU), transformer-based models (BERT and RoBERTa), and large language models (OpenAI, Gemini, Ollama, Anthropic). Each model was evaluated under different preprocessing and augmentation strategies (for example, synonym replacement, word embeddings, etc.). Among traditional ML approaches, Support Vector Machines (SVM) with data augmentation achieved the best overall performance, reaching 94 percent accuracy, recall, and F1 scores with minimal overfitting. In contrast, the RNN models and BERT suffered from severe overfitting, while RoBERTa initially overcame it but began to show signs as training progressed. Finally, zero-shot evaluations of large language models (LLMs) indicated that OpenAI and Gemini performed best among the tested LLMs, achieving approximately 0.72-0.73 accuracy and comparable F1 scores. These findings highlight the challenges of training complex deep models on limited data and underscore the value of careful data augmentation and simpler algorithms (such as augmented SVM) for Bloom’s Taxonomy classification. Read More
Enhancing Demand-Oriented Regionalization with Agentic AI and Local Heterogeneous Data for Adaptation Planningcs.AI updates on arXiv.org arXiv:2511.10857v1 Announce Type: new
Abstract: Conventional planning units or urban regions, such as census tracts, zip codes, or neighborhoods, often do not capture the specific demands of local communities and lack the flexibility to implement effective strategies for hazard prevention or response. To support the creation of dynamic planning units, we introduce a planning support system with agentic AI that enables users to generate demand-oriented regions for disaster planning, integrating the human-in-the-loop principle for transparency and adaptability. The platform is built on a representative initialized spatially constrained self-organizing map (RepSC-SOM), extending traditional SOM with adaptive geographic filtering and region-growing refinement, while AI agents can reason, plan, and act to guide the process by suggesting input features, guiding spatial constraints, and supporting interactive exploration. We demonstrate the capabilities of the platform through a case study on the flooding-related risk in Jacksonville, Florida, showing how it allows users to explore, generate, and evaluate regionalization interactively, combining computational rigor with user-driven decision making.
arXiv:2511.10857v1 Announce Type: new
Abstract: Conventional planning units or urban regions, such as census tracts, zip codes, or neighborhoods, often do not capture the specific demands of local communities and lack the flexibility to implement effective strategies for hazard prevention or response. To support the creation of dynamic planning units, we introduce a planning support system with agentic AI that enables users to generate demand-oriented regions for disaster planning, integrating the human-in-the-loop principle for transparency and adaptability. The platform is built on a representative initialized spatially constrained self-organizing map (RepSC-SOM), extending traditional SOM with adaptive geographic filtering and region-growing refinement, while AI agents can reason, plan, and act to guide the process by suggesting input features, guiding spatial constraints, and supporting interactive exploration. We demonstrate the capabilities of the platform through a case study on the flooding-related risk in Jacksonville, Florida, showing how it allows users to explore, generate, and evaluate regionalization interactively, combining computational rigor with user-driven decision making. Read More
From Retinal Pixels to Patients: Evolution of Deep Learning Research in Diabetic Retinopathy Screeningcs.AI updates on arXiv.org arXiv:2511.11065v1 Announce Type: cross
Abstract: Diabetic Retinopathy (DR) remains a leading cause of preventable blindness, with early detection critical for reducing vision loss worldwide. Over the past decade, deep learning has transformed DR screening, progressing from early convolutional neural networks trained on private datasets to advanced pipelines addressing class imbalance, label scarcity, domain shift, and interpretability. This survey provides the first systematic synthesis of DR research spanning 2016-2025, consolidating results from 50+ studies and over 20 datasets. We critically examine methodological advances, including self- and semi-supervised learning, domain generalization, federated training, and hybrid neuro-symbolic models, alongside evaluation protocols, reporting standards, and reproducibility challenges. Benchmark tables contextualize performance across datasets, while discussion highlights open gaps in multi-center validation and clinical trust. By linking technical progress with translational barriers, this work outlines a practical agenda for reproducible, privacy-preserving, and clinically deployable DR AI. Beyond DR, many of the surveyed innovations extend broadly to medical imaging at scale.
arXiv:2511.11065v1 Announce Type: cross
Abstract: Diabetic Retinopathy (DR) remains a leading cause of preventable blindness, with early detection critical for reducing vision loss worldwide. Over the past decade, deep learning has transformed DR screening, progressing from early convolutional neural networks trained on private datasets to advanced pipelines addressing class imbalance, label scarcity, domain shift, and interpretability. This survey provides the first systematic synthesis of DR research spanning 2016-2025, consolidating results from 50+ studies and over 20 datasets. We critically examine methodological advances, including self- and semi-supervised learning, domain generalization, federated training, and hybrid neuro-symbolic models, alongside evaluation protocols, reporting standards, and reproducibility challenges. Benchmark tables contextualize performance across datasets, while discussion highlights open gaps in multi-center validation and clinical trust. By linking technical progress with translational barriers, this work outlines a practical agenda for reproducible, privacy-preserving, and clinically deployable DR AI. Beyond DR, many of the surveyed innovations extend broadly to medical imaging at scale. Read More
AirCopBench: A Benchmark for Multi-drone Collaborative Embodied Perception and Reasoningcs.AI updates on arXiv.org arXiv:2511.11025v1 Announce Type: cross
Abstract: Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning.
arXiv:2511.11025v1 Announce Type: cross
Abstract: Multimodal Large Language Models (MLLMs) have shown promise in single-agent vision tasks, yet benchmarks for evaluating multi-agent collaborative perception remain scarce. This gap is critical, as multi-drone systems provide enhanced coverage, robustness, and collaboration compared to single-sensor setups. Existing multi-image benchmarks mainly target basic perception tasks using high-quality single-agent images, thus failing to evaluate MLLMs in more complex, egocentric collaborative scenarios, especially under real-world degraded perception conditions.To address these challenges, we introduce AirCopBench, the first comprehensive benchmark designed to evaluate MLLMs in embodied aerial collaborative perception under challenging perceptual conditions. AirCopBench includes 14.6k+ questions derived from both simulator and real-world data, spanning four key task dimensions: Scene Understanding, Object Understanding, Perception Assessment, and Collaborative Decision, across 14 task types. We construct the benchmark using data from challenging degraded-perception scenarios with annotated collaborative events, generating large-scale questions through model-, rule-, and human-based methods under rigorous quality control. Evaluations on 40 MLLMs show significant performance gaps in collaborative perception tasks, with the best model trailing humans by 24.38% on average and exhibiting inconsistent results across tasks. Fine-tuning experiments further confirm the feasibility of sim-to-real transfer in aerial collaborative perception and reasoning. Read More