
The breakthrough that makes robot faces feel less creepy Artificial Intelligence News — ScienceDaily
The breakthrough that makes robot faces feel less creepyArtificial Intelligence News — ScienceDaily Humans pay enormous attention to lips during conversation, and robots have struggled badly to keep up. A new robot developed at Columbia Engineering learned realistic lip movements by watching its own reflection and studying human videos online. This allowed it to speak and sing with synchronized facial motion, without being explicitly programmed. Researchers believe this breakthrough could help robots finally cross the uncanny valley.
Humans pay enormous attention to lips during conversation, and robots have struggled badly to keep up. A new robot developed at Columbia Engineering learned realistic lip movements by watching its own reflection and studying human videos online. This allowed it to speak and sing with synchronized facial motion, without being explicitly programmed. Researchers believe this breakthrough could help robots finally cross the uncanny valley. Read More
Data Poisoning in Machine Learning: Why and How People Manipulate Training Data Towards Data Science
Data Poisoning in Machine Learning: Why and How People Manipulate Training DataTowards Data Science Do you know where your data has been?
The post Data Poisoning in Machine Learning: Why and How People Manipulate Training Data appeared first on Towards Data Science.
Do you know where your data has been?
The post Data Poisoning in Machine Learning: Why and How People Manipulate Training Data appeared first on Towards Data Science. Read More

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated January 16th, 2026 Hello Everyone, Help us grow our community by sharing and/or supporting us on other platforms. This allow us to show verification that what we are doing is valued. It also allows us to plan and […]
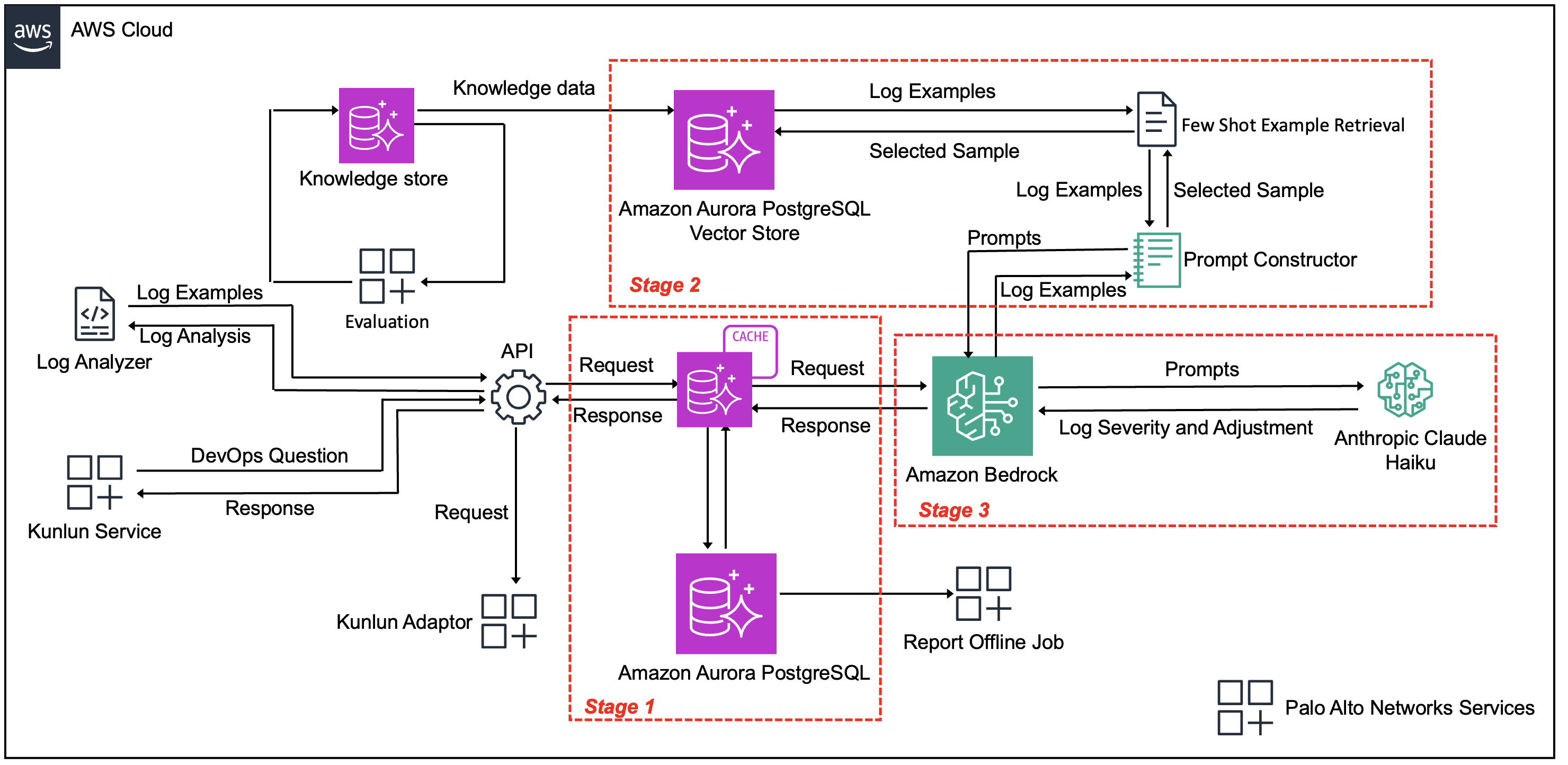
How Palo Alto Networks enhanced device security infra log analysis with Amazon BedrockArtificial Intelligence Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements. Read More

From beginner to champion: A student’s journey through the AWS AI League ASEAN finalsArtificial Intelligence The AWS AI League, launched by Amazon Web Services (AWS), expanded its reach to the Association of Southeast Asian Nations (ASEAN) last year, welcoming student participants from Singapore, Indonesia, Malaysia, Thailand, Vietnam, and the Philippines. In this blog post, you’ll hear directly from the AWS AI League champion, Blix D. Foryasen, as he shares his reflection on the challenges, breakthroughs, and key lessons discovered throughout the competition.
The AWS AI League, launched by Amazon Web Services (AWS), expanded its reach to the Association of Southeast Asian Nations (ASEAN) last year, welcoming student participants from Singapore, Indonesia, Malaysia, Thailand, Vietnam, and the Philippines. In this blog post, you’ll hear directly from the AWS AI League champion, Blix D. Foryasen, as he shares his reflection on the challenges, breakthroughs, and key lessons discovered throughout the competition. Read More
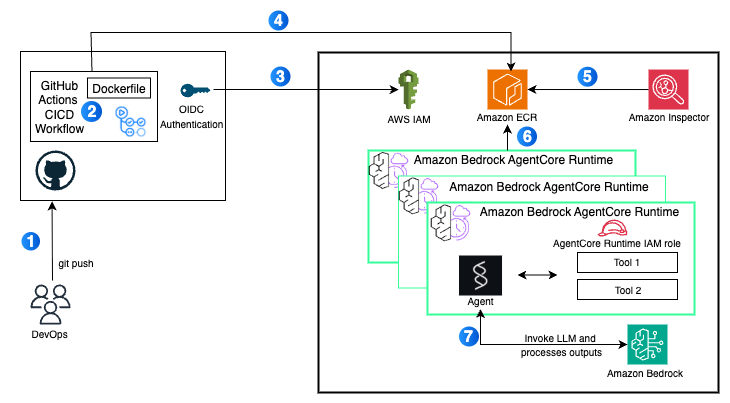
Deploy AI agents on Amazon Bedrock AgentCore using GitHub ActionsArtificial Intelligence In this post, we demonstrate how to use a GitHub Actions workflow to automate the deployment of AI agents on AgentCore Runtime. This approach delivers a scalable solution with enterprise-level security controls, providing complete continuous integration and delivery (CI/CD) automation.
In this post, we demonstrate how to use a GitHub Actions workflow to automate the deployment of AI agents on AgentCore Runtime. This approach delivers a scalable solution with enterprise-level security controls, providing complete continuous integration and delivery (CI/CD) automation. Read More
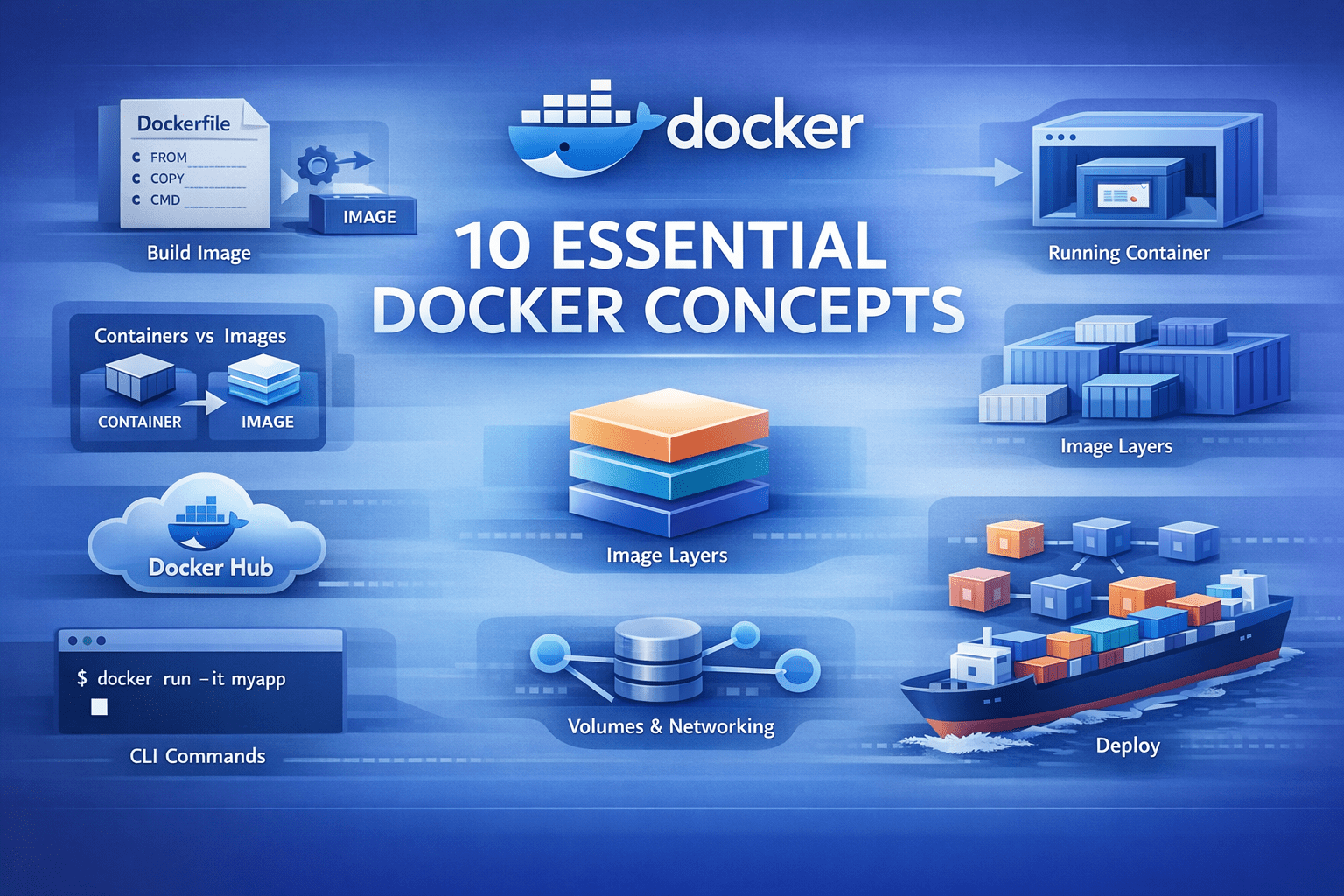
10 Essential Docker Concepts Explained in Under 10 MinutesKDnuggets Images, containers, volumes, and networks… Docker terms often sound complex to beginners. This quick guide explains Docker essentials to get started.
Images, containers, volumes, and networks… Docker terms often sound complex to beginners. This quick guide explains Docker essentials to get started. Read More
Cutting LLM Memory by 84%: A Deep Dive into Fused KernelsTowards Data Science Why your final LLM layer is OOMing and how to fix it with a custom Triton kernel.
The post Cutting LLM Memory by 84%: A Deep Dive into Fused Kernels appeared first on Towards Data Science.
Why your final LLM layer is OOMing and how to fix it with a custom Triton kernel.
The post Cutting LLM Memory by 84%: A Deep Dive into Fused Kernels appeared first on Towards Data Science. Read More
The truth left out from Elon Musk’s recent court filingOpenAI News The truth left out from Elon Musk’s recent court filing.
The truth left out from Elon Musk’s recent court filing. Read More

Banks operationalise as Plumery AI launches standardised integrationAI News A new technology from digital banking platform Plumery AI aims to address a dilemma for financial institutions: how to move beyond proofs of concept and embed artificial intelligence into everyday banking operations without compromising governance, security, or regulatory compliance. Plumery’s “AI Fabric” has been positioned by the company as a standardised framework for connecting generative
The post Banks operationalise as Plumery AI launches standardised integration appeared first on AI News.
A new technology from digital banking platform Plumery AI aims to address a dilemma for financial institutions: how to move beyond proofs of concept and embed artificial intelligence into everyday banking operations without compromising governance, security, or regulatory compliance. Plumery’s “AI Fabric” has been positioned by the company as a standardised framework for connecting generative
The post Banks operationalise as Plumery AI launches standardised integration appeared first on AI News. Read More