
How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame ContractsMarkTechPost Schemas, and Composable DataFrame ContractsIn this tutorial, we demonstrate how to build robust, production-grade data validation pipelines using Pandera with typed DataFrame models. We start by simulating realistic, imperfect transactional data and progressively enforce strict schema constraints, column-level rules, and cross-column business logic using declarative checks. We show how lazy validation helps us surface multiple
The post How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame Contracts appeared first on MarkTechPost.
Schemas, and Composable DataFrame ContractsIn this tutorial, we demonstrate how to build robust, production-grade data validation pipelines using Pandera with typed DataFrame models. We start by simulating realistic, imperfect transactional data and progressively enforce strict schema constraints, column-level rules, and cross-column business logic using declarative checks. We show how lazy validation helps us surface multiple
The post How to Build Production-Grade Data Validation Pipelines Using Pandera, Typed Schemas, and Composable DataFrame Contracts appeared first on MarkTechPost. Read More
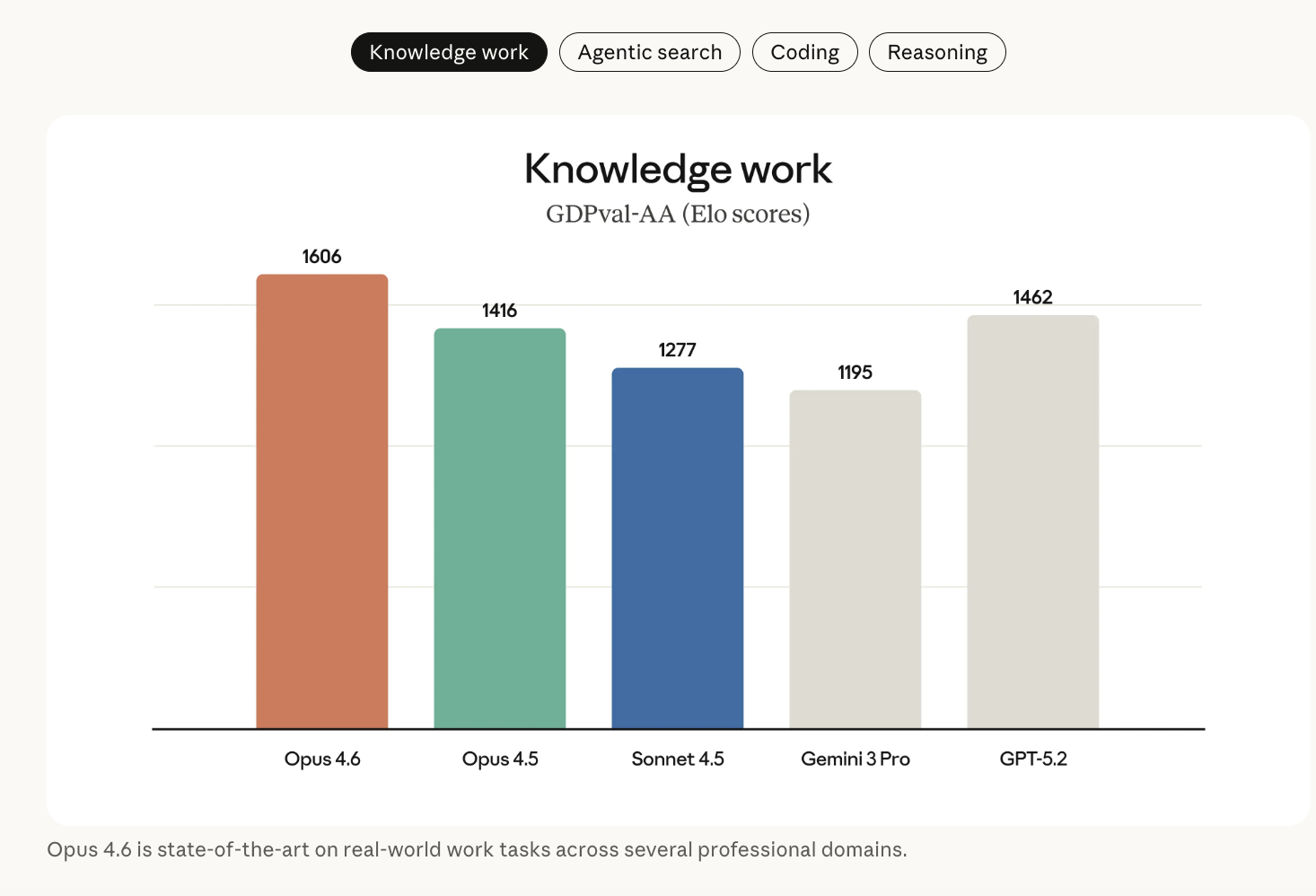
Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling CapabilitiesMarkTechPost Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value knowledge work. The model builds on Claude Opus 4.5 and is now available on claude.ai, the Claude API, and major cloud providers under the ID claude-opus-4-6. Model focus: agentic work, not single answers Opus 4.6
The post Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling Capabilities appeared first on MarkTechPost.
Anthropic has launched Claude Opus 4.6, its most capable model to date, focused on long-context reasoning, agentic coding, and high-value knowledge work. The model builds on Claude Opus 4.5 and is now available on claude.ai, the Claude API, and major cloud providers under the ID claude-opus-4-6. Model focus: agentic work, not single answers Opus 4.6
The post Anthropic Releases Claude Opus 4.6 With 1M Context, Agentic Coding, Adaptive Reasoning Controls, and Expanded Safety Tooling Capabilities appeared first on MarkTechPost. Read More
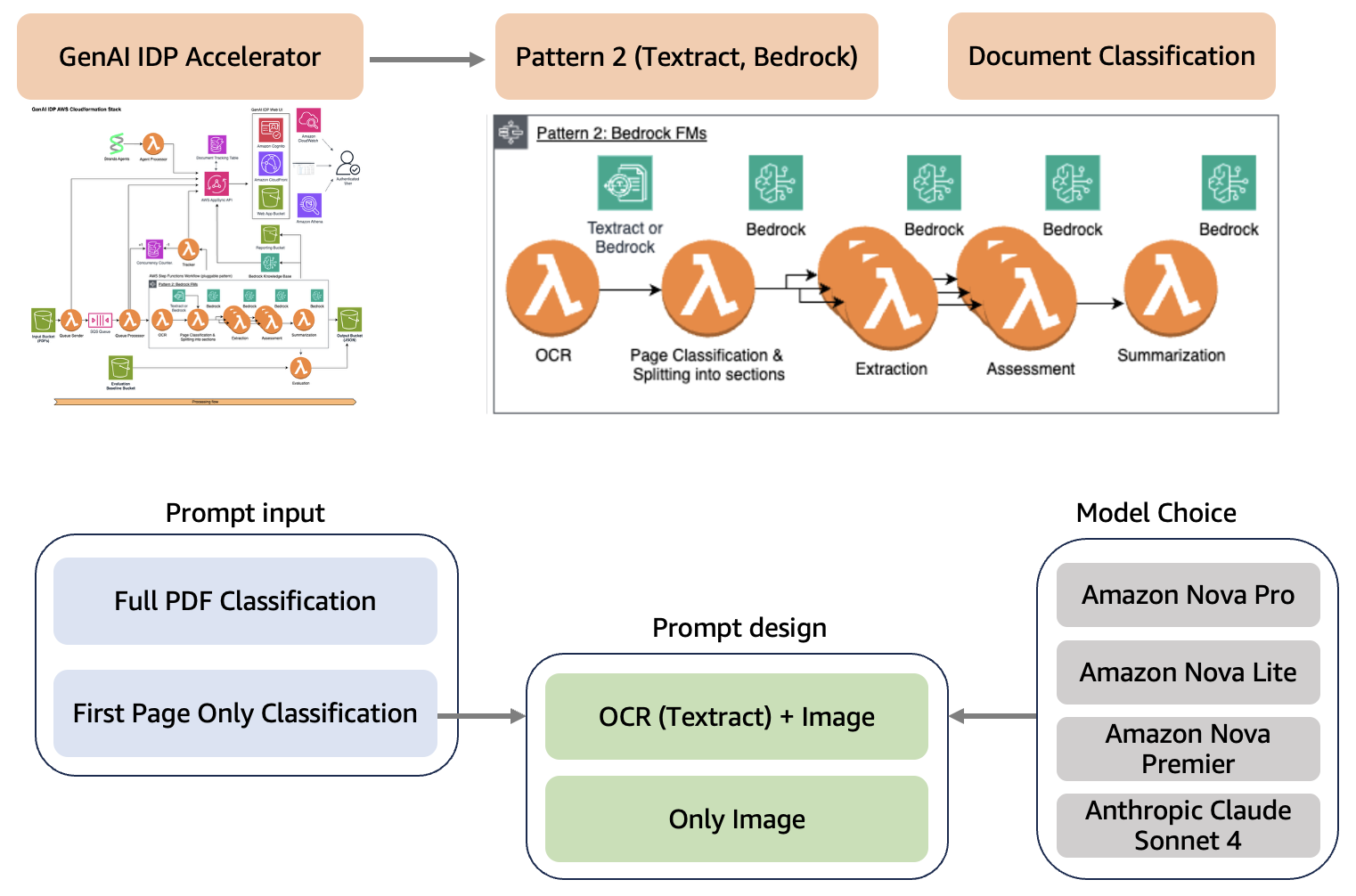
How Associa transforms document classification with the GenAI IDP Accelerator and Amazon BedrockArtificial Intelligence Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks.
Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks. Read More
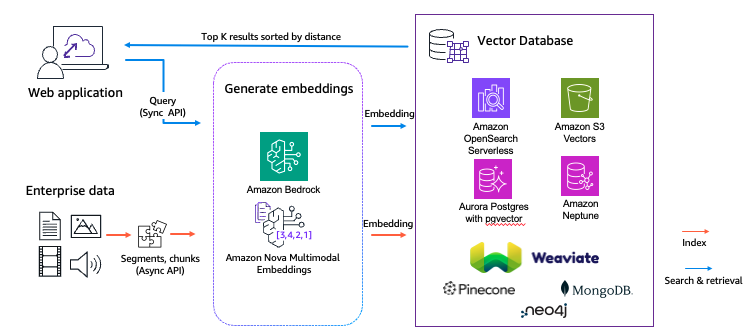
A practical guide to Amazon Nova Multimodal EmbeddingsArtificial Intelligence In this post, you will learn how to configure and use Amazon Nova Multimodal Embeddings for media asset search systems, product discovery experiences, and document retrieval applications.
In this post, you will learn how to configure and use Amazon Nova Multimodal Embeddings for media asset search systems, product discovery experiences, and document retrieval applications. Read More
Scaling In-Context Online Learning Capability of LLMs via Cross-Episode Meta-RLcs.AI updates on arXiv.org arXiv:2602.04089v1 Announce Type: new
Abstract: Large language models (LLMs) achieve strong performance when all task-relevant information is available upfront, as in static prediction and instruction-following problems. However, many real-world decision-making tasks are inherently online: crucial information must be acquired through interaction, feedback is delayed, and effective behavior requires balancing information collection and exploitation over time. While in-context learning enables adaptation without weight updates, existing LLMs often struggle to reliably leverage in-context interaction experience in such settings. In this work, we show that this limitation can be addressed through training. We introduce ORBIT, a multi-task, multi-episode meta-reinforcement learning framework that trains LLMs to learn from interaction in context. After meta-training, a relatively small open-source model (Qwen3-14B) demonstrates substantially improved in-context online learning on entirely unseen environments, matching the performance of GPT-5.2 and outperforming standard RL fine-tuning by a large margin. Scaling experiments further reveal consistent gains with model size, suggesting significant headroom for learn-at-inference-time decision-making agents. Code reproducing the results in the paper can be found at https://github.com/XiaofengLin7/ORBIT.
arXiv:2602.04089v1 Announce Type: new
Abstract: Large language models (LLMs) achieve strong performance when all task-relevant information is available upfront, as in static prediction and instruction-following problems. However, many real-world decision-making tasks are inherently online: crucial information must be acquired through interaction, feedback is delayed, and effective behavior requires balancing information collection and exploitation over time. While in-context learning enables adaptation without weight updates, existing LLMs often struggle to reliably leverage in-context interaction experience in such settings. In this work, we show that this limitation can be addressed through training. We introduce ORBIT, a multi-task, multi-episode meta-reinforcement learning framework that trains LLMs to learn from interaction in context. After meta-training, a relatively small open-source model (Qwen3-14B) demonstrates substantially improved in-context online learning on entirely unseen environments, matching the performance of GPT-5.2 and outperforming standard RL fine-tuning by a large margin. Scaling experiments further reveal consistent gains with model size, suggesting significant headroom for learn-at-inference-time decision-making agents. Code reproducing the results in the paper can be found at https://github.com/XiaofengLin7/ORBIT. Read More
A Novel Framework for Uncertainty-Driven Adaptive Explorationcs.AI updates on arXiv.org arXiv:2509.03219v5 Announce Type: replace
Abstract: Adaptive exploration methods propose ways to learn complex policies via alternating between exploration and exploitation. An important question for such methods is to determine the appropriate moment to switch between exploration and exploitation and vice versa. This is critical in domains that require the learning of long and complex sequences of actions. In this work, we present a generic adaptive exploration framework that employs uncertainty to address this important issue in a principled manner. Our framework includes previous adaptive exploration approaches as special cases. Moreover, we can incorporate in our framework any uncertainty-measuring mechanism of choice, for instance mechanisms used in intrinsic motivation or epistemic uncertainty-based exploration methods. We experimentally demonstrate that our framework gives rise to adaptive exploration strategies that outperform standard ones across several environments.
arXiv:2509.03219v5 Announce Type: replace
Abstract: Adaptive exploration methods propose ways to learn complex policies via alternating between exploration and exploitation. An important question for such methods is to determine the appropriate moment to switch between exploration and exploitation and vice versa. This is critical in domains that require the learning of long and complex sequences of actions. In this work, we present a generic adaptive exploration framework that employs uncertainty to address this important issue in a principled manner. Our framework includes previous adaptive exploration approaches as special cases. Moreover, we can incorporate in our framework any uncertainty-measuring mechanism of choice, for instance mechanisms used in intrinsic motivation or epistemic uncertainty-based exploration methods. We experimentally demonstrate that our framework gives rise to adaptive exploration strategies that outperform standard ones across several environments. Read More
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machinescs.AI updates on arXiv.org arXiv:2601.09465v2 Announce Type: replace
Abstract: While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
arXiv:2601.09465v2 Announce Type: replace
Abstract: While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization. Read More

The Absolute Insanity of MoltbookKDnuggets What the… AI agents arguing over memes? Sure, why not.
What the… AI agents arguing over memes? Sure, why not. Read More
OpenAI’s enterprise push: The hidden story behind AI’s sales raceAI News As OpenAI races toward its ambitious US$100 billion revenue target by 2027, the ChatGPT maker is reportedly building an army of AI consultants to bridge the gap between cutting-edge technology and enterprise boardrooms—a move that signals a fundamental shift in how AI companies are approaching the notoriously difficult challenge of enterprise adoption. According to industry
The post OpenAI’s enterprise push: The hidden story behind AI’s sales race appeared first on AI News.
As OpenAI races toward its ambitious US$100 billion revenue target by 2027, the ChatGPT maker is reportedly building an army of AI consultants to bridge the gap between cutting-edge technology and enterprise boardrooms—a move that signals a fundamental shift in how AI companies are approaching the notoriously difficult challenge of enterprise adoption. According to industry
The post OpenAI’s enterprise push: The hidden story behind AI’s sales race appeared first on AI News. Read More
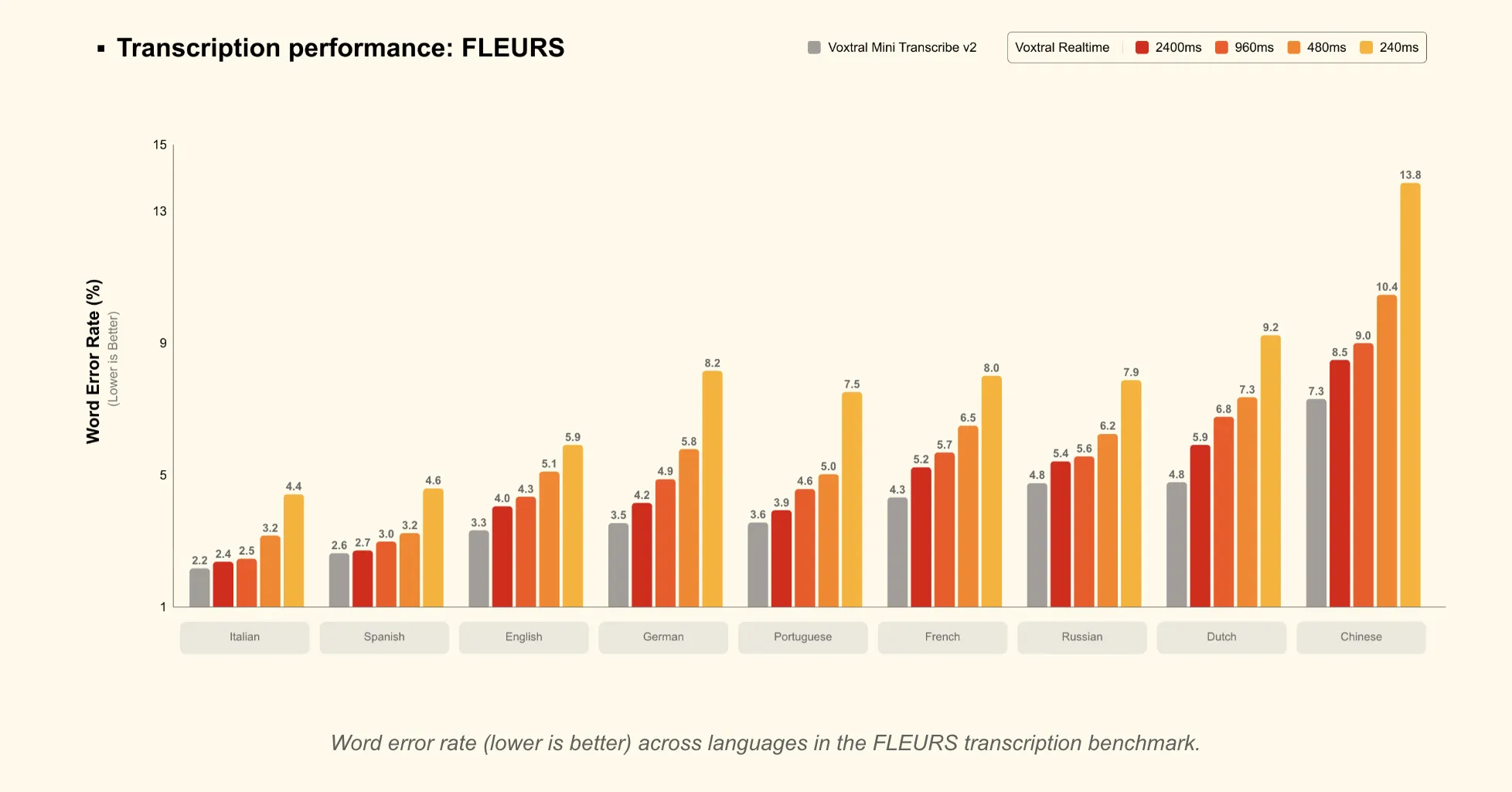
Mistral AI Launches Voxtral Transcribe 2: Pairing Batch Diarization And Open Realtime ASR For Multilingual Production Workloads At ScaleMarkTechPost Automatic speech recognition (ASR) is becoming a core building block for AI products, from meeting tools to voice agents. Mistral’s new Voxtral Transcribe 2 family targets this space with 2 models that split cleanly into batch and realtime use cases, while keeping cost, latency, and deployment constraints in focus. The release includes: Both models are
The post Mistral AI Launches Voxtral Transcribe 2: Pairing Batch Diarization And Open Realtime ASR For Multilingual Production Workloads At Scale appeared first on MarkTechPost.
Automatic speech recognition (ASR) is becoming a core building block for AI products, from meeting tools to voice agents. Mistral’s new Voxtral Transcribe 2 family targets this space with 2 models that split cleanly into batch and realtime use cases, while keeping cost, latency, and deployment constraints in focus. The release includes: Both models are
The post Mistral AI Launches Voxtral Transcribe 2: Pairing Batch Diarization And Open Realtime ASR For Multilingual Production Workloads At Scale appeared first on MarkTechPost. Read More