
MOSS: Efficient and Accurate FP8 LLM Training with Microscaling and Automatic Scalingcs.AI updates on arXiv.org arXiv:2511.05811v2 Announce Type: replace-cross
Abstract: Training large language models with FP8 formats offers significant efficiency gains. However, the reduced numerical precision of FP8 poses challenges for stable and accurate training. Current frameworks preserve training performance using mixed-granularity quantization, i.e., applying per-group quantization for activations and per-tensor/block quantization for weights. While effective, per-group quantization requires scaling along the inner dimension of matrix multiplication, introducing additional dequantization overhead. Moreover, these frameworks often rely on just-in-time scaling to dynamically adjust scaling factors based on the current data distribution. However, this online quantization is inefficient for FP8 training, as it involves multiple memory reads and writes that negate the performance benefits of FP8. To overcome these limitations, we propose MOSS, a novel FP8 training framework that ensures both efficiency and numerical stability. MOSS introduces two key innovations: (1) a two-level microscaling strategy for quantizing sensitive activations, which balances precision and dequantization cost by combining a high-precision global scale with compact, power-of-two local scales; and (2) automatic scaling for weights in linear layers, which eliminates the need for costly max-reduction operations by predicting and adjusting scaling factors during training. Leveraging these techniques, MOSS enables efficient FP8 training of a 7B parameter model, achieving performance comparable to the BF16 baseline while achieving up to 34% higher training throughput.
arXiv:2511.05811v2 Announce Type: replace-cross
Abstract: Training large language models with FP8 formats offers significant efficiency gains. However, the reduced numerical precision of FP8 poses challenges for stable and accurate training. Current frameworks preserve training performance using mixed-granularity quantization, i.e., applying per-group quantization for activations and per-tensor/block quantization for weights. While effective, per-group quantization requires scaling along the inner dimension of matrix multiplication, introducing additional dequantization overhead. Moreover, these frameworks often rely on just-in-time scaling to dynamically adjust scaling factors based on the current data distribution. However, this online quantization is inefficient for FP8 training, as it involves multiple memory reads and writes that negate the performance benefits of FP8. To overcome these limitations, we propose MOSS, a novel FP8 training framework that ensures both efficiency and numerical stability. MOSS introduces two key innovations: (1) a two-level microscaling strategy for quantizing sensitive activations, which balances precision and dequantization cost by combining a high-precision global scale with compact, power-of-two local scales; and (2) automatic scaling for weights in linear layers, which eliminates the need for costly max-reduction operations by predicting and adjusting scaling factors during training. Leveraging these techniques, MOSS enables efficient FP8 training of a 7B parameter model, achieving performance comparable to the BF16 baseline while achieving up to 34% higher training throughput. Read More
IPA: An Information-Reconstructive Input Projection Framework for Efficient Foundation Model Adaptationcs.AI updates on arXiv.org arXiv:2509.04398v2 Announce Type: replace-cross
Abstract: Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA’s down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly aims to reconstruct the original input within a reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen. Code available at https://github.com/valeoai/peft-ipa .
arXiv:2509.04398v2 Announce Type: replace-cross
Abstract: Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA’s down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly aims to reconstruct the original input within a reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen. Code available at https://github.com/valeoai/peft-ipa . Read More
SAT: Dynamic Spatial Aptitude Training for Multimodal Language Modelscs.AI updates on arXiv.org arXiv:2412.07755v3 Announce Type: replace-cross
Abstract: Reasoning about motion and space is a fundamental cognitive capability that is required by multiple real-world applications. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only focus on static spatial relationships, and not dynamic awareness of motion and space, i.e., reasoning about the effect of egocentric and object motions on spatial relationships. Manually annotating such object and camera movements is expensive. Hence, we introduce SAT, a simulated spatial aptitude training dataset utilizing 3D simulators, comprising both static and dynamic spatial reasoning across 175K question-answer (QA) pairs and 20K scenes. Complementing this, we also construct a small (150 image-QAs) yet challenging dynamic spatial test set using real-world images. Leveraging our SAT datasets and 6 existing static spatial benchmarks, we systematically investigate what improves both static and dynamic spatial awareness. Our results reveal that simulations are surprisingly effective at imparting spatial aptitude to MLMs that translate to real images. We show that perfect annotations in simulation are more effective than existing approaches of pseudo-annotating real images. For instance, SAT training improves a LLaVA-13B model by an average 11% and a LLaVA-Video-7B model by an average 8% on multiple spatial benchmarks, including our real-image dynamic test set and spatial reasoning on long videos — even outperforming some large proprietary models. While reasoning over static relationships improves with synthetic training data, there is still considerable room for improvement for dynamic reasoning questions.
arXiv:2412.07755v3 Announce Type: replace-cross
Abstract: Reasoning about motion and space is a fundamental cognitive capability that is required by multiple real-world applications. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only focus on static spatial relationships, and not dynamic awareness of motion and space, i.e., reasoning about the effect of egocentric and object motions on spatial relationships. Manually annotating such object and camera movements is expensive. Hence, we introduce SAT, a simulated spatial aptitude training dataset utilizing 3D simulators, comprising both static and dynamic spatial reasoning across 175K question-answer (QA) pairs and 20K scenes. Complementing this, we also construct a small (150 image-QAs) yet challenging dynamic spatial test set using real-world images. Leveraging our SAT datasets and 6 existing static spatial benchmarks, we systematically investigate what improves both static and dynamic spatial awareness. Our results reveal that simulations are surprisingly effective at imparting spatial aptitude to MLMs that translate to real images. We show that perfect annotations in simulation are more effective than existing approaches of pseudo-annotating real images. For instance, SAT training improves a LLaVA-13B model by an average 11% and a LLaVA-Video-7B model by an average 8% on multiple spatial benchmarks, including our real-image dynamic test set and spatial reasoning on long videos — even outperforming some large proprietary models. While reasoning over static relationships improves with synthetic training data, there is still considerable room for improvement for dynamic reasoning questions. Read More
Approximation of Box Decomposition Algorithm for Fast Hypervolume-Based Multi-Objective Optimizationcs.AI updates on arXiv.org arXiv:2512.05825v1 Announce Type: cross
Abstract: Hypervolume (HV)-based Bayesian optimization (BO) is one of the standard approaches for multi-objective decision-making. However, the computational cost of optimizing the acquisition function remains a significant bottleneck, primarily due to the expense of HV improvement calculations. While HV box-decomposition offers an efficient way to cope with the frequent exact improvement calculations, it suffers from super-polynomial memory complexity $O(MN^{lfloor frac{M + 1}{2} rfloor})$ in the worst case as proposed by Lacour et al. (2017). To tackle this problem, Couckuyt et al. (2012) employed an approximation algorithm. However, a rigorous algorithmic description is currently absent from the literature. This paper bridges this gap by providing comprehensive mathematical and algorithmic details of this approximation algorithm.
arXiv:2512.05825v1 Announce Type: cross
Abstract: Hypervolume (HV)-based Bayesian optimization (BO) is one of the standard approaches for multi-objective decision-making. However, the computational cost of optimizing the acquisition function remains a significant bottleneck, primarily due to the expense of HV improvement calculations. While HV box-decomposition offers an efficient way to cope with the frequent exact improvement calculations, it suffers from super-polynomial memory complexity $O(MN^{lfloor frac{M + 1}{2} rfloor})$ in the worst case as proposed by Lacour et al. (2017). To tackle this problem, Couckuyt et al. (2012) employed an approximation algorithm. However, a rigorous algorithmic description is currently absent from the literature. This paper bridges this gap by providing comprehensive mathematical and algorithmic details of this approximation algorithm. Read More
Faithfulness metric fusion: Improving the evaluation of LLM trustworthiness across domainscs.AI updates on arXiv.org arXiv:2512.05700v1 Announce Type: cross
Abstract: We present a methodology for improving the accuracy of faithfulness evaluation in Large Language Models (LLMs). The proposed methodology is based on the combination of elementary faithfulness metrics into a combined (fused) metric, for the purpose of improving the faithfulness of LLM outputs. The proposed strategy for metric fusion deploys a tree-based model to identify the importance of each metric, which is driven by the integration of human judgements evaluating the faithfulness of LLM responses. This fused metric is demonstrated to correlate more strongly with human judgements across all tested domains for faithfulness. Improving the ability to evaluate the faithfulness of LLMs, allows for greater confidence to be placed within models, allowing for their implementation in a greater diversity of scenarios. Additionally, we homogenise a collection of datasets across question answering and dialogue-based domains and implement human judgements and LLM responses within this dataset, allowing for the reproduction and trialling of faithfulness evaluation across domains.
arXiv:2512.05700v1 Announce Type: cross
Abstract: We present a methodology for improving the accuracy of faithfulness evaluation in Large Language Models (LLMs). The proposed methodology is based on the combination of elementary faithfulness metrics into a combined (fused) metric, for the purpose of improving the faithfulness of LLM outputs. The proposed strategy for metric fusion deploys a tree-based model to identify the importance of each metric, which is driven by the integration of human judgements evaluating the faithfulness of LLM responses. This fused metric is demonstrated to correlate more strongly with human judgements across all tested domains for faithfulness. Improving the ability to evaluate the faithfulness of LLMs, allows for greater confidence to be placed within models, allowing for their implementation in a greater diversity of scenarios. Additionally, we homogenise a collection of datasets across question answering and dialogue-based domains and implement human judgements and LLM responses within this dataset, allowing for the reproduction and trialling of faithfulness evaluation across domains. Read More
Counterfactual Reasoning for Steerable Pluralistic Value Alignment of Large Language Modelscs.AI updates on arXiv.org arXiv:2510.18526v2 Announce Type: replace
Abstract: As large language models (LLMs) become increasingly integrated into applications serving users across diverse cultures, communities and demographics, it is critical to align LLMs with pluralistic human values beyond average principles (e.g., HHH). In psychological and social value theories such as Schwartz’s Value Theory, pluralistic values are represented by multiple value dimensions paired with various priorities. However, existing methods encounter two challenges when aligning with such fine-grained value objectives: 1) they often treat multiple values as independent and equally important, ignoring their interdependence and relative priorities (value complexity); 2) they struggle to precisely control nuanced value priorities, especially those underrepresented ones (value steerability). To handle these challenges, we propose COUPLE, a COUnterfactual reasoning framework for PLuralistic valuE alignment. It introduces a structural causal model (SCM) to feature complex interdependency and prioritization among features, as well as the causal relationship between high-level value dimensions and behaviors. Moreover, it applies counterfactual reasoning to generate outputs aligned with any desired value objectives. Benefitting from explicit causal modeling, COUPLE also provides better interpretability. We evaluate COUPLE on two datasets with different value systems and demonstrate that COUPLE advances other baselines across diverse types of value objectives.
arXiv:2510.18526v2 Announce Type: replace
Abstract: As large language models (LLMs) become increasingly integrated into applications serving users across diverse cultures, communities and demographics, it is critical to align LLMs with pluralistic human values beyond average principles (e.g., HHH). In psychological and social value theories such as Schwartz’s Value Theory, pluralistic values are represented by multiple value dimensions paired with various priorities. However, existing methods encounter two challenges when aligning with such fine-grained value objectives: 1) they often treat multiple values as independent and equally important, ignoring their interdependence and relative priorities (value complexity); 2) they struggle to precisely control nuanced value priorities, especially those underrepresented ones (value steerability). To handle these challenges, we propose COUPLE, a COUnterfactual reasoning framework for PLuralistic valuE alignment. It introduces a structural causal model (SCM) to feature complex interdependency and prioritization among features, as well as the causal relationship between high-level value dimensions and behaviors. Moreover, it applies counterfactual reasoning to generate outputs aligned with any desired value objectives. Benefitting from explicit causal modeling, COUPLE also provides better interpretability. We evaluate COUPLE on two datasets with different value systems and demonstrate that COUPLE advances other baselines across diverse types of value objectives. Read More
Optimizing PyTorch Model Inference on CPUTowards Data Science Flyin’ Like a Lion on Intel Xeon
The post Optimizing PyTorch Model Inference on CPU appeared first on Towards Data Science.
Flyin’ Like a Lion on Intel Xeon
The post Optimizing PyTorch Model Inference on CPU appeared first on Towards Data Science. Read More

Agentic AI smartphones: ByteDance signals opportunity beyond consumer hypeAI News ByteDance’s December 2 launch of an agentic AI smartphone prototype with ZTE sparked immediate consumer enthusiasm – and just as quickly triggered privacy concerns that forced the company to dial back capabilities. But beneath the headline-grabbing sell-out and subsequent controversy lies a more significant story: the enterprise implications of operating-system-level AI agents that can autonomously
The post Agentic AI smartphones: ByteDance signals opportunity beyond consumer hype appeared first on AI News.
ByteDance’s December 2 launch of an agentic AI smartphone prototype with ZTE sparked immediate consumer enthusiasm – and just as quickly triggered privacy concerns that forced the company to dial back capabilities. But beneath the headline-grabbing sell-out and subsequent controversy lies a more significant story: the enterprise implications of operating-system-level AI agents that can autonomously
The post Agentic AI smartphones: ByteDance signals opportunity beyond consumer hype appeared first on AI News. Read More
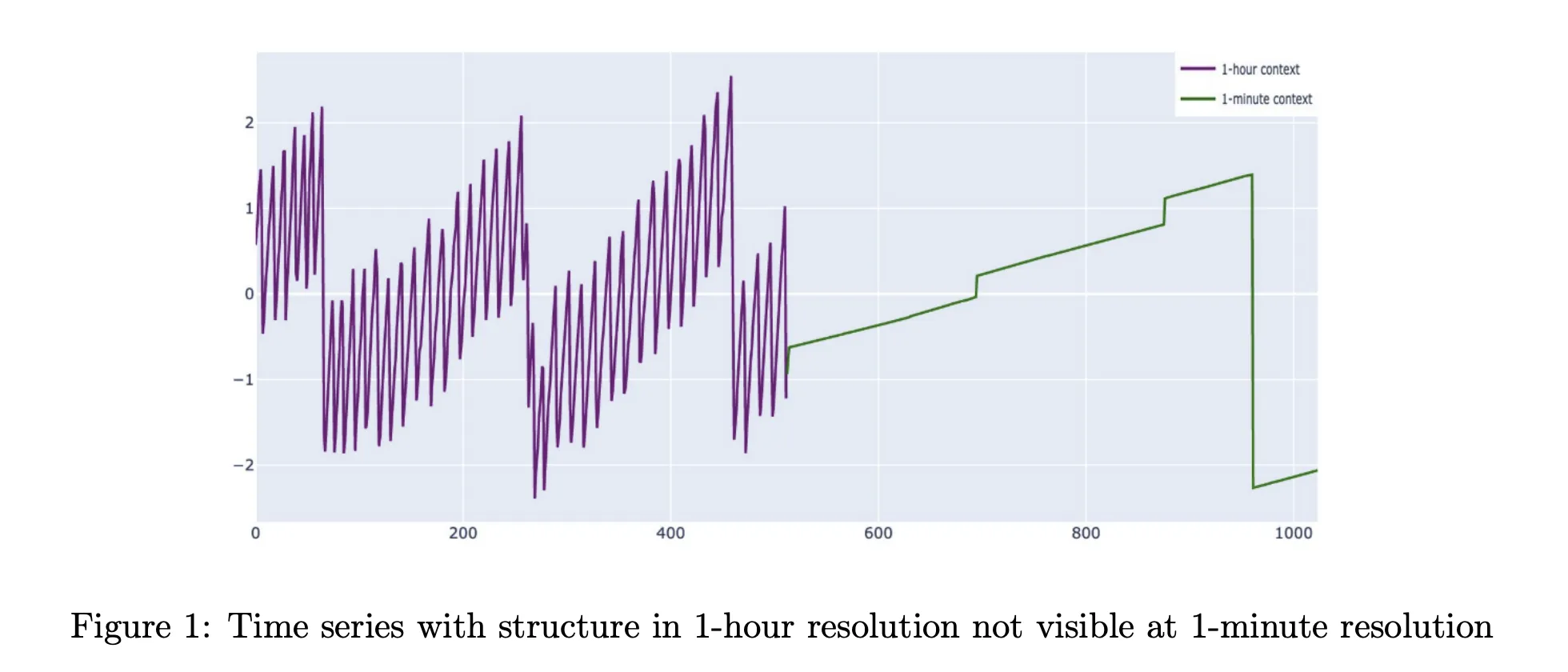
Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer ArchitectureMarkTechPost Cisco and Splunk have introduced the Cisco Time Series Model, a univariate zero shot time series foundation model designed for observability and security metrics. It is released as an open weight checkpoint on Hugging Face under an Apache 2.0 license, and it targets forecasting workloads without task specific fine tuning. The model extends TimesFM 2.0
The post Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer Architecture appeared first on MarkTechPost.
Cisco and Splunk have introduced the Cisco Time Series Model, a univariate zero shot time series foundation model designed for observability and security metrics. It is released as an open weight checkpoint on Hugging Face under an Apache 2.0 license, and it targets forecasting workloads without task specific fine tuning. The model extends TimesFM 2.0
The post Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer Architecture appeared first on MarkTechPost. Read More
Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and CompetitionsMarkTechPost Google is closing an old gap between Kaggle and Colab. Colab now has a built in Data Explorer that lets you search Kaggle datasets, models and competitions directly inside a notebook, then pull them in through KaggleHub without leaving the editor. What Colab Data Explorer actually ships? Kaggle announced the feature recently where they describe
The post Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and Competitions appeared first on MarkTechPost.
Google is closing an old gap between Kaggle and Colab. Colab now has a built in Data Explorer that lets you search Kaggle datasets, models and competitions directly inside a notebook, then pull them in through KaggleHub without leaving the editor. What Colab Data Explorer actually ships? Kaggle announced the feature recently where they describe
The post Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and Competitions appeared first on MarkTechPost. Read More