
Efficient Perplexity Bound and Ratio Matching in Discrete Diffusion Language Modelscs.AI updates on arXiv.org arXiv:2507.04341v2 Announce Type: replace-cross
Abstract: While continuous diffusion models excel in modeling continuous distributions, their application to categorical data has been less effective. Recent work has shown that ratio-matching through score-entropy within a continuous-time discrete Markov chain (CTMC) framework serves as a competitive alternative to autoregressive models in language modeling. To enhance this framework, we first introduce three new theorems concerning the KL divergence between the data and learned distribution. Our results serve as the discrete counterpart to those established for continuous diffusion models and allow us to derive an improved upper bound of the perplexity. Second, we empirically show that ratio-matching performed by minimizing the denoising cross-entropy between the clean and corrupted data enables models to outperform those utilizing score-entropy with up to 10% lower perplexity/generative-perplexity, and 15% faster training steps. To further support our findings, we introduce and evaluate a novel CTMC transition-rate matrix that allows prediction refinement, and derive the analytic expression for its matrix exponential which facilitates the computation of conditional ratios thus enabling efficient training and generation.
arXiv:2507.04341v2 Announce Type: replace-cross
Abstract: While continuous diffusion models excel in modeling continuous distributions, their application to categorical data has been less effective. Recent work has shown that ratio-matching through score-entropy within a continuous-time discrete Markov chain (CTMC) framework serves as a competitive alternative to autoregressive models in language modeling. To enhance this framework, we first introduce three new theorems concerning the KL divergence between the data and learned distribution. Our results serve as the discrete counterpart to those established for continuous diffusion models and allow us to derive an improved upper bound of the perplexity. Second, we empirically show that ratio-matching performed by minimizing the denoising cross-entropy between the clean and corrupted data enables models to outperform those utilizing score-entropy with up to 10% lower perplexity/generative-perplexity, and 15% faster training steps. To further support our findings, we introduce and evaluate a novel CTMC transition-rate matrix that allows prediction refinement, and derive the analytic expression for its matrix exponential which facilitates the computation of conditional ratios thus enabling efficient training and generation. Read More
Unlocking Noisy Real-World Corpora for Foundation Model Pre-Training via Quality-Aware Tokenizationcs.AI updates on arXiv.org arXiv:2602.06394v1 Announce Type: new
Abstract: Current tokenization methods process sequential data without accounting for signal quality, limiting their effectiveness on noisy real-world corpora. We present QA-Token (Quality-Aware Tokenization), which incorporates data reliability directly into vocabulary construction. We make three key contributions: (i) a bilevel optimization formulation that jointly optimizes vocabulary construction and downstream performance, (ii) a reinforcement learning approach that learns merge policies through quality-aware rewards with convergence guarantees, and (iii) an adaptive parameter learning mechanism via Gumbel-Softmax relaxation for end-to-end optimization. Our experimental evaluation demonstrates consistent improvements: genomics (6.7 percentage point F1 gain in variant calling over BPE), finance (30% Sharpe ratio improvement). At foundation scale, we tokenize a pretraining corpus comprising 1.7 trillion base-pairs and achieve state-of-the-art pathogen detection (94.53 MCC) while reducing token count by 15%. We unlock noisy real-world corpora, spanning petabases of genomic sequences and terabytes of financial time series, for foundation model training with zero inference overhead.
arXiv:2602.06394v1 Announce Type: new
Abstract: Current tokenization methods process sequential data without accounting for signal quality, limiting their effectiveness on noisy real-world corpora. We present QA-Token (Quality-Aware Tokenization), which incorporates data reliability directly into vocabulary construction. We make three key contributions: (i) a bilevel optimization formulation that jointly optimizes vocabulary construction and downstream performance, (ii) a reinforcement learning approach that learns merge policies through quality-aware rewards with convergence guarantees, and (iii) an adaptive parameter learning mechanism via Gumbel-Softmax relaxation for end-to-end optimization. Our experimental evaluation demonstrates consistent improvements: genomics (6.7 percentage point F1 gain in variant calling over BPE), finance (30% Sharpe ratio improvement). At foundation scale, we tokenize a pretraining corpus comprising 1.7 trillion base-pairs and achieve state-of-the-art pathogen detection (94.53 MCC) while reducing token count by 15%. We unlock noisy real-world corpora, spanning petabases of genomic sequences and terabytes of financial time series, for foundation model training with zero inference overhead. Read More
Malicious Agent Skills in the Wild: A Large-Scale Security Empirical Studycs.AI updates on arXiv.org arXiv:2602.06547v1 Announce Type: cross
Abstract: Third-party agent skills extend LLM-based agents with instruction files and executable code that run on users’ machines. Skills execute with user privileges and are distributed through community registries with minimal vetting, but no ground-truth dataset exists to characterize the resulting threats. We construct the first labeled dataset of malicious agent skills by behaviorally verifying 98,380 skills from two community registries, confirming 157 malicious skills with 632 vulnerabilities. These attacks are not incidental. Malicious skills average 4.03 vulnerabilities across a median of three kill chain phases, and the ecosystem has split into two archetypes: Data Thieves that exfiltrate credentials through supply chain techniques, and Agent Hijackers that subvert agent decision-making through instruction manipulation. A single actor accounts for 54.1% of confirmed cases through templated brand impersonation. Shadow features, capabilities absent from public documentation, appear in 0% of basic attacks but 100% of advanced ones; several skills go further by exploiting the AI platform’s own hook system and permission flags. Responsible disclosure led to 93.6% removal within 30 days. We release the dataset and analysis pipeline to support future work on agent skill security.
arXiv:2602.06547v1 Announce Type: cross
Abstract: Third-party agent skills extend LLM-based agents with instruction files and executable code that run on users’ machines. Skills execute with user privileges and are distributed through community registries with minimal vetting, but no ground-truth dataset exists to characterize the resulting threats. We construct the first labeled dataset of malicious agent skills by behaviorally verifying 98,380 skills from two community registries, confirming 157 malicious skills with 632 vulnerabilities. These attacks are not incidental. Malicious skills average 4.03 vulnerabilities across a median of three kill chain phases, and the ecosystem has split into two archetypes: Data Thieves that exfiltrate credentials through supply chain techniques, and Agent Hijackers that subvert agent decision-making through instruction manipulation. A single actor accounts for 54.1% of confirmed cases through templated brand impersonation. Shadow features, capabilities absent from public documentation, appear in 0% of basic attacks but 100% of advanced ones; several skills go further by exploiting the AI platform’s own hook system and permission flags. Responsible disclosure led to 93.6% removal within 30 days. We release the dataset and analysis pipeline to support future work on agent skill security. Read More
Generating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modeling AI updates on arXiv.org
Generating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modelingcs.AI updates on arXiv.org arXiv:2602.06795v1 Announce Type: cross
Abstract: An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or “rubrics”, demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models’ task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure.
arXiv:2602.06795v1 Announce Type: cross
Abstract: An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or “rubrics”, demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models’ task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure. Read More
A Coding Implementation to Establish Rigorous Prompt Versioning and Regression Testing Workflows for Large Language Models using MLflowMarkTechPost In this tutorial, we show how we treat prompts as first-class, versioned artifacts and apply rigorous regression testing to large language model behavior using MLflow. We design an evaluation pipeline that logs prompt versions, prompt diffs, model outputs, and multiple quality metrics in a fully reproducible manner. By combining classical text metrics with semantic similarity
The post A Coding Implementation to Establish Rigorous Prompt Versioning and Regression Testing Workflows for Large Language Models using MLflow appeared first on MarkTechPost.
In this tutorial, we show how we treat prompts as first-class, versioned artifacts and apply rigorous regression testing to large language model behavior using MLflow. We design an evaluation pipeline that logs prompt versions, prompt diffs, model outputs, and multiple quality metrics in a fully reproducible manner. By combining classical text metrics with semantic similarity
The post A Coding Implementation to Establish Rigorous Prompt Versioning and Regression Testing Workflows for Large Language Models using MLflow appeared first on MarkTechPost. Read More
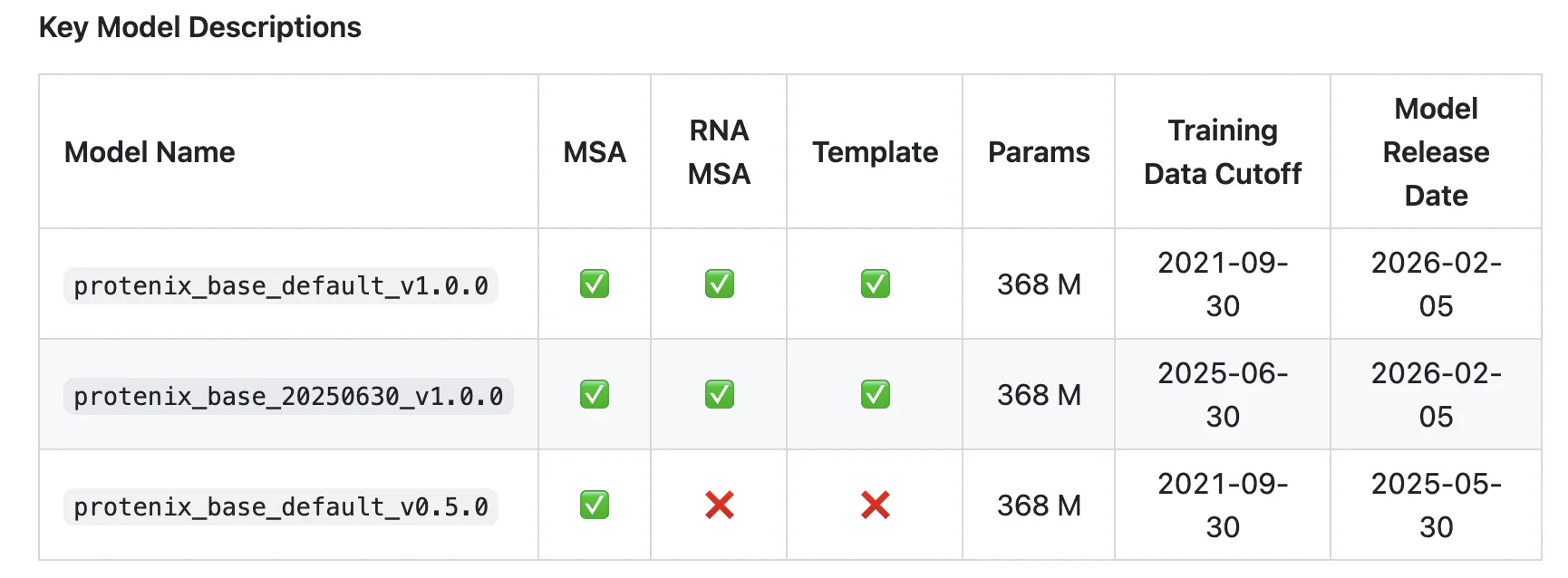
ByteDance Releases Protenix-v1: A New Open-Source Model Achieving AF3-Level Performance in Biomolecular Structure PredictionMarkTechPost How close can an open model get to AlphaFold3-level accuracy when it matches training data, model scale and inference budget? ByteDance has introduced Protenix-v1, a comprehensive AlphaFold3 (AF3) reproduction for biomolecular structure prediction, released with code and model parameters under Apache 2.0. The model targets AF3-level performance across protein, DNA, RNA and ligand structures while
The post ByteDance Releases Protenix-v1: A New Open-Source Model Achieving AF3-Level Performance in Biomolecular Structure Prediction appeared first on MarkTechPost.
How close can an open model get to AlphaFold3-level accuracy when it matches training data, model scale and inference budget? ByteDance has introduced Protenix-v1, a comprehensive AlphaFold3 (AF3) reproduction for biomolecular structure prediction, released with code and model parameters under Apache 2.0. The model targets AF3-level performance across protein, DNA, RNA and ligand structures while
The post ByteDance Releases Protenix-v1: A New Open-Source Model Achieving AF3-Level Performance in Biomolecular Structure Prediction appeared first on MarkTechPost. Read More
How to Design Production-Grade Mock Data Pipelines Using Polyfactory with Dataclasses, Pydantic, Attrs, and Nested ModelsMarkTechPost In this tutorial, we walk through an advanced, end-to-end exploration of Polyfactory, focusing on how we can generate rich, realistic mock data directly from Python type hints. We start by setting up the environment and progressively build factories for data classes, Pydantic models, and attrs-based classes, while demonstrating customization, overrides, calculated fields, and the generation
The post How to Design Production-Grade Mock Data Pipelines Using Polyfactory with Dataclasses, Pydantic, Attrs, and Nested Models appeared first on MarkTechPost.
In this tutorial, we walk through an advanced, end-to-end exploration of Polyfactory, focusing on how we can generate rich, realistic mock data directly from Python type hints. We start by setting up the environment and progressively build factories for data classes, Pydantic models, and attrs-based classes, while demonstrating customization, overrides, calculated fields, and the generation
The post How to Design Production-Grade Mock Data Pipelines Using Polyfactory with Dataclasses, Pydantic, Attrs, and Nested Models appeared first on MarkTechPost. Read More
VERA-MH: Reliability and Validity of an Open-Source AI Safety Evaluation in Mental Healthcs.AI updates on arXiv.org arXiv:2602.05088v1 Announce Type: new
Abstract: Millions now use leading generative AI chatbots for psychological support. Despite the promise related to availability and scale, the single most pressing question in AI for mental health is whether these tools are safe. The Validation of Ethical and Responsible AI in Mental Health (VERA-MH) evaluation was recently proposed to meet the urgent need for an evidence-based automated safety benchmark. This study aimed to examine the clinical validity and reliability of the VERA-MH evaluation for AI safety in suicide risk detection and response. We first simulated a large set of conversations between large language model (LLM)-based users (user-agents) and general-purpose AI chatbots. Licensed mental health clinicians used a rubric (scoring guide) to independently rate the simulated conversations for safe and unsafe chatbot behaviors, as well as user-agent realism. An LLM-based judge used the same scoring rubric to evaluate the same set of simulated conversations. We then compared rating alignment across (a) individual clinicians and (b) clinician consensus and the LLM judge, and (c) examined clinicians’ ratings of user-agent realism. Individual clinicians were generally consistent with one another in their safety ratings (chance-corrected inter-rater reliability [IRR]: 0.77), thus establishing a gold-standard clinical reference. The LLM judge was strongly aligned with this clinical consensus (IRR: 0.81) overall and within key conditions. Clinician raters generally perceived the user-agents to be realistic. For the potential mental health benefits of AI chatbots to be realized, attention to safety is paramount. Findings from this human evaluation study support the clinical validity and reliability of VERA-MH: an open-source, fully automated AI safety evaluation for mental health. Further research will address VERA-MH generalizability and robustness.
arXiv:2602.05088v1 Announce Type: new
Abstract: Millions now use leading generative AI chatbots for psychological support. Despite the promise related to availability and scale, the single most pressing question in AI for mental health is whether these tools are safe. The Validation of Ethical and Responsible AI in Mental Health (VERA-MH) evaluation was recently proposed to meet the urgent need for an evidence-based automated safety benchmark. This study aimed to examine the clinical validity and reliability of the VERA-MH evaluation for AI safety in suicide risk detection and response. We first simulated a large set of conversations between large language model (LLM)-based users (user-agents) and general-purpose AI chatbots. Licensed mental health clinicians used a rubric (scoring guide) to independently rate the simulated conversations for safe and unsafe chatbot behaviors, as well as user-agent realism. An LLM-based judge used the same scoring rubric to evaluate the same set of simulated conversations. We then compared rating alignment across (a) individual clinicians and (b) clinician consensus and the LLM judge, and (c) examined clinicians’ ratings of user-agent realism. Individual clinicians were generally consistent with one another in their safety ratings (chance-corrected inter-rater reliability [IRR]: 0.77), thus establishing a gold-standard clinical reference. The LLM judge was strongly aligned with this clinical consensus (IRR: 0.81) overall and within key conditions. Clinician raters generally perceived the user-agents to be realistic. For the potential mental health benefits of AI chatbots to be realized, attention to safety is paramount. Findings from this human evaluation study support the clinical validity and reliability of VERA-MH: an open-source, fully automated AI safety evaluation for mental health. Further research will address VERA-MH generalizability and robustness. Read More
Evaluating Large Language Models on Solved and Unsolved Problems in Graph Theory: Implications for Computing Educationcs.AI updates on arXiv.org arXiv:2602.05059v1 Announce Type: new
Abstract: Large Language Models are increasingly used by students to explore advanced material in computer science, including graph theory. As these tools become integrated into undergraduate and graduate coursework, it is important to understand how reliably they support mathematically rigorous thinking. This study examines the performance of a LLM on two related graph theoretic problems: a solved problem concerning the gracefulness of line graphs and an open problem for which no solution is currently known. We use an eight stage evaluation protocol that reflects authentic mathematical inquiry, including interpretation, exploration, strategy formation, and proof construction.
The model performed strongly on the solved problem, producing correct definitions, identifying relevant structures, recalling appropriate results without hallucination, and constructing a valid proof confirmed by a graph theory expert. For the open problem, the model generated coherent interpretations and plausible exploratory strategies but did not advance toward a solution. It did not fabricate results and instead acknowledged uncertainty, which is consistent with the explicit prompting instructions that directed the model to avoid inventing theorems or unsupported claims.
These findings indicate that LLMs can support exploration of established material but remain limited in tasks requiring novel mathematical insight or critical structural reasoning. For computing education, this distinction highlights the importance of guiding students to use LLMs for conceptual exploration while relying on independent verification and rigorous argumentation for formal problem solving.
arXiv:2602.05059v1 Announce Type: new
Abstract: Large Language Models are increasingly used by students to explore advanced material in computer science, including graph theory. As these tools become integrated into undergraduate and graduate coursework, it is important to understand how reliably they support mathematically rigorous thinking. This study examines the performance of a LLM on two related graph theoretic problems: a solved problem concerning the gracefulness of line graphs and an open problem for which no solution is currently known. We use an eight stage evaluation protocol that reflects authentic mathematical inquiry, including interpretation, exploration, strategy formation, and proof construction.
The model performed strongly on the solved problem, producing correct definitions, identifying relevant structures, recalling appropriate results without hallucination, and constructing a valid proof confirmed by a graph theory expert. For the open problem, the model generated coherent interpretations and plausible exploratory strategies but did not advance toward a solution. It did not fabricate results and instead acknowledged uncertainty, which is consistent with the explicit prompting instructions that directed the model to avoid inventing theorems or unsupported claims.
These findings indicate that LLMs can support exploration of established material but remain limited in tasks requiring novel mathematical insight or critical structural reasoning. For computing education, this distinction highlights the importance of guiding students to use LLMs for conceptual exploration while relying on independent verification and rigorous argumentation for formal problem solving. Read More
Beyond touch-based human-machine interface: Control your machines in natural language by utilizing large language models and OPC UAcs.AI updates on arXiv.org arXiv:2510.11300v2 Announce Type: replace-cross
Abstract: This paper proposes an agent-based approach toward a more natural interface between humans and machines. Large language models equipped with tools and the communication standard OPC UA are utilized to control machines in natural language. Instead of touch interaction, which is currently the state-of-the-art medium for interaction in operations, the proposed approach enables operators to talk or text with machines. This allows commands such as ‘Please decrease the temperature by 20 % in machine 1 and start the cleaning operation in machine 2.’ The large language model receives the user input and selects one of three predefined tools that connect to an OPC UA server and either change or read the value of a node. Afterwards, the result of the tool execution is passed back to the language model, which then provides a final response to the user. The approach is universally designed and can therefore be applied to any machine that supports the OPC UA standard. The large language model is neither fine-tuned nor requires training data, only the relevant machine credentials and a parameter dictionary are included within the system prompt. The tool-calling ability and their design is evaluated on a demonstrator setup with a Siemens S7-1500 programmable logic controller with four machine parameters. Fifty synthetically generated commands on five different models were tested and the results demonstrate high success rate, with proprietary GPT-5 models achieving accuracies between 96.0 % and 98.0 %, and open-weight models reaching up to 90.0 %. Afterwards the approach was transferred to a deployed spay-coating machine. The proposed concept is supposed to contribute in advancing natural interaction in industrial human-machine interfaces.
arXiv:2510.11300v2 Announce Type: replace-cross
Abstract: This paper proposes an agent-based approach toward a more natural interface between humans and machines. Large language models equipped with tools and the communication standard OPC UA are utilized to control machines in natural language. Instead of touch interaction, which is currently the state-of-the-art medium for interaction in operations, the proposed approach enables operators to talk or text with machines. This allows commands such as ‘Please decrease the temperature by 20 % in machine 1 and start the cleaning operation in machine 2.’ The large language model receives the user input and selects one of three predefined tools that connect to an OPC UA server and either change or read the value of a node. Afterwards, the result of the tool execution is passed back to the language model, which then provides a final response to the user. The approach is universally designed and can therefore be applied to any machine that supports the OPC UA standard. The large language model is neither fine-tuned nor requires training data, only the relevant machine credentials and a parameter dictionary are included within the system prompt. The tool-calling ability and their design is evaluated on a demonstrator setup with a Siemens S7-1500 programmable logic controller with four machine parameters. Fifty synthetically generated commands on five different models were tested and the results demonstrate high success rate, with proprietary GPT-5 models achieving accuracies between 96.0 % and 98.0 %, and open-weight models reaching up to 90.0 %. Afterwards the approach was transferred to a deployed spay-coating machine. The proposed concept is supposed to contribute in advancing natural interaction in industrial human-machine interfaces. Read More