
Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each QueryMarkTechPost LLMRouter is an open source routing library from the U Lab at the University of Illinois Urbana Champaign that treats model selection as a first class system problem. It sits between applications and a pool of LLMs and chooses a model for each query based on task complexity, quality targets, and cost, all exposed through
The post Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each Query appeared first on MarkTechPost.
LLMRouter is an open source routing library from the U Lab at the University of Illinois Urbana Champaign that treats model selection as a first class system problem. It sits between applications and a pool of LLMs and chooses a model for each query based on task complexity, quality targets, and cost, all exposed through
The post Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each Query appeared first on MarkTechPost. Read More
DynaMix: Generalizable Person Re-identification via Dynamic Relabeling and Mixed Data Samplingcs.AI updates on arXiv.org arXiv:2511.19067v2 Announce Type: replace-cross
Abstract: Generalizable person re-identification (Re-ID) aims to recognize individuals across unseen cameras and environments. While existing methods rely heavily on limited labeled multi-camera data, we propose DynaMix, a novel method that effectively combines manually labeled multi-camera and large-scale pseudo-labeled single-camera data. Unlike prior works, DynaMix dynamically adapts to the structure and noise of the training data through three core components: (1) a Relabeling Module that refines pseudo-labels of single-camera identities on-the-fly; (2) an Efficient Centroids Module that maintains robust identity representations under a large identity space; and (3) a Data Sampling Module that carefully composes mixed data mini-batches to balance learning complexity and intra-batch diversity. All components are specifically designed to operate efficiently at scale, enabling effective training on millions of images and hundreds of thousands of identities. Extensive experiments demonstrate that DynaMix consistently outperforms state-of-the-art methods in generalizable person Re-ID.
arXiv:2511.19067v2 Announce Type: replace-cross
Abstract: Generalizable person re-identification (Re-ID) aims to recognize individuals across unseen cameras and environments. While existing methods rely heavily on limited labeled multi-camera data, we propose DynaMix, a novel method that effectively combines manually labeled multi-camera and large-scale pseudo-labeled single-camera data. Unlike prior works, DynaMix dynamically adapts to the structure and noise of the training data through three core components: (1) a Relabeling Module that refines pseudo-labels of single-camera identities on-the-fly; (2) an Efficient Centroids Module that maintains robust identity representations under a large identity space; and (3) a Data Sampling Module that carefully composes mixed data mini-batches to balance learning complexity and intra-batch diversity. All components are specifically designed to operate efficiently at scale, enabling effective training on millions of images and hundreds of thousands of identities. Extensive experiments demonstrate that DynaMix consistently outperforms state-of-the-art methods in generalizable person Re-ID. Read More
Feasible strategies in three-way conflict analysis with three-valued ratings AI updates on arXiv.org
Feasible strategies in three-way conflict analysis with three-valued ratingscs.AI updates on arXiv.org arXiv:2512.21420v2 Announce Type: new
Abstract: Most existing work on three-way conflict analysis has focused on trisecting agent pairs, agents, or issues, which contributes to understanding the nature of conflicts but falls short in addressing their resolution. Specifically, the formulation of feasible strategies, as an essential component of conflict resolution and mitigation, has received insufficient scholarly attention. Therefore, this paper aims to investigate feasible strategies from two perspectives of consistency and non-consistency. Particularly, we begin with computing the overall rating of a clique of agents based on positive and negative similarity degrees. Afterwards, considering the weights of both agents and issues, we propose weighted consistency and non-consistency measures, which are respectively used to identify the feasible strategies for a clique of agents. Algorithms are developed to identify feasible strategies, $L$-order feasible strategies, and the corresponding optimal ones. Finally, to demonstrate the practicality, effectiveness, and superiority of the proposed models, we apply them to two commonly used case studies on NBA labor negotiations and development plans for Gansu Province and conduct a sensitivity analysis on parameters and a comparative analysis with existing state-of-the-art conflict analysis approaches. The comparison results demonstrate that our conflict resolution models outperform the conventional approaches by unifying weighted agent-issue evaluation with consistency and non-consistency measures to enable the systematic identification of not only feasible strategies but also optimal solutions.
arXiv:2512.21420v2 Announce Type: new
Abstract: Most existing work on three-way conflict analysis has focused on trisecting agent pairs, agents, or issues, which contributes to understanding the nature of conflicts but falls short in addressing their resolution. Specifically, the formulation of feasible strategies, as an essential component of conflict resolution and mitigation, has received insufficient scholarly attention. Therefore, this paper aims to investigate feasible strategies from two perspectives of consistency and non-consistency. Particularly, we begin with computing the overall rating of a clique of agents based on positive and negative similarity degrees. Afterwards, considering the weights of both agents and issues, we propose weighted consistency and non-consistency measures, which are respectively used to identify the feasible strategies for a clique of agents. Algorithms are developed to identify feasible strategies, $L$-order feasible strategies, and the corresponding optimal ones. Finally, to demonstrate the practicality, effectiveness, and superiority of the proposed models, we apply them to two commonly used case studies on NBA labor negotiations and development plans for Gansu Province and conduct a sensitivity analysis on parameters and a comparative analysis with existing state-of-the-art conflict analysis approaches. The comparison results demonstrate that our conflict resolution models outperform the conventional approaches by unifying weighted agent-issue evaluation with consistency and non-consistency measures to enable the systematic identification of not only feasible strategies but also optimal solutions. Read More
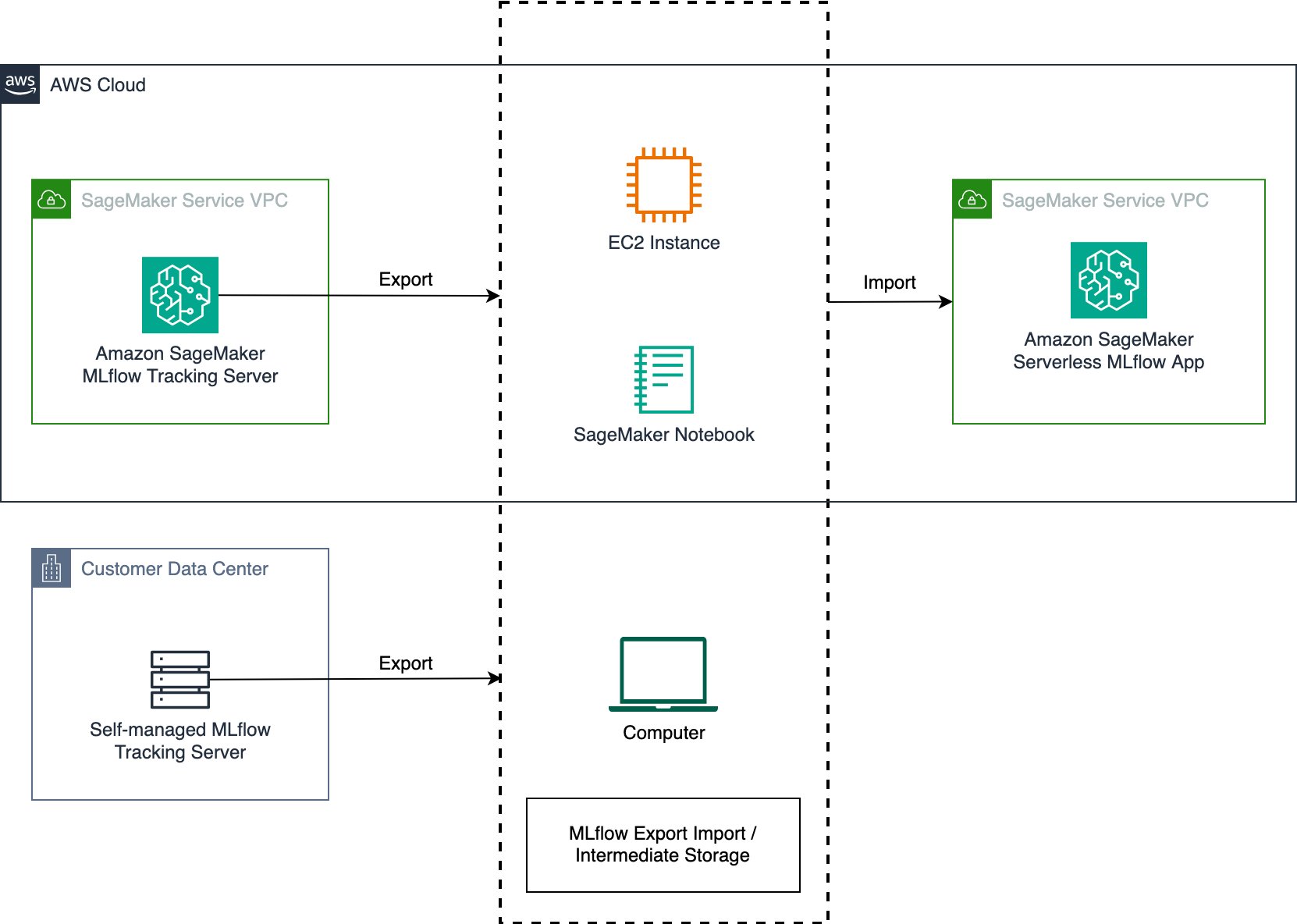
Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflowArtificial Intelligence
Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflowArtificial Intelligence This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success.
This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration’s success. Read More
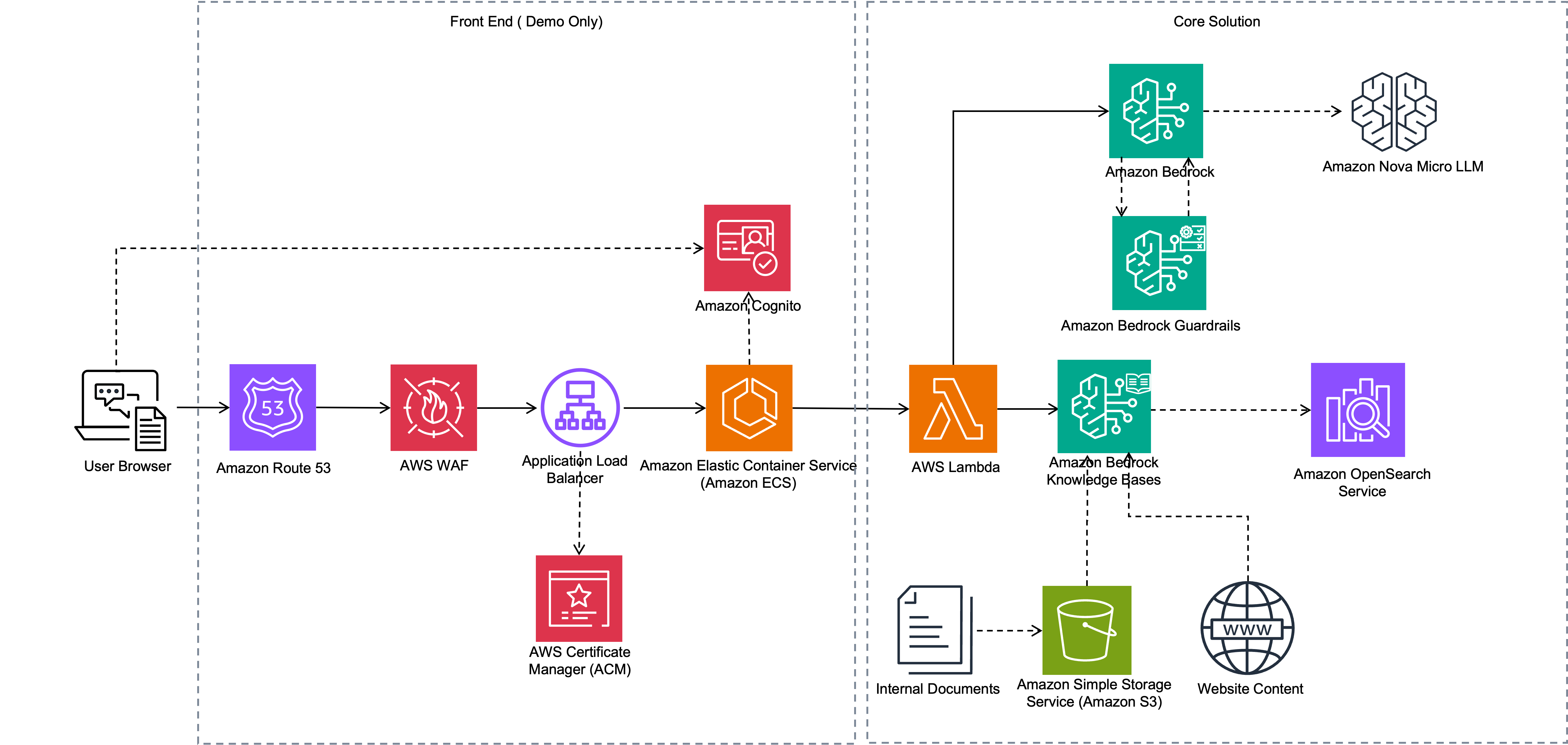
Build an AI-powered website assistant with Amazon BedrockArtificial Intelligence This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases.
This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases. Read More
Unveiling the Learning Mind of Language Models: A Cognitive Framework and Empirical Studycs.AI updates on arXiv.org arXiv:2506.13464v3 Announce Type: replace-cross
Abstract: Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs’ general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models.
arXiv:2506.13464v3 Announce Type: replace-cross
Abstract: Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs’ general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models. Read More
Generative Digital Twins: Vision-Language Simulation Models for Executable Industrial Systemscs.AI updates on arXiv.org arXiv:2512.20387v2 Announce Type: replace
Abstract: We propose a Vision-Language Simulation Model (VLSM) that unifies visual and textual understanding to synthesize executable FlexScript from layout sketches and natural-language prompts, enabling cross-modal reasoning for industrial simulation systems. To support this new paradigm, the study constructs the first large-scale dataset for generative digital twins, comprising over 120,000 prompt-sketch-code triplets that enable multimodal learning between textual descriptions, spatial structures, and simulation logic. In parallel, three novel evaluation metrics, Structural Validity Rate (SVR), Parameter Match Rate (PMR), and Execution Success Rate (ESR), are proposed specifically for this task to comprehensively evaluate structural integrity, parameter fidelity, and simulator executability. Through systematic ablation across vision encoders, connectors, and code-pretrained language backbones, the proposed models achieve near-perfect structural accuracy and high execution robustness. This work establishes a foundation for generative digital twins that integrate visual reasoning and language understanding into executable industrial simulation systems.
arXiv:2512.20387v2 Announce Type: replace
Abstract: We propose a Vision-Language Simulation Model (VLSM) that unifies visual and textual understanding to synthesize executable FlexScript from layout sketches and natural-language prompts, enabling cross-modal reasoning for industrial simulation systems. To support this new paradigm, the study constructs the first large-scale dataset for generative digital twins, comprising over 120,000 prompt-sketch-code triplets that enable multimodal learning between textual descriptions, spatial structures, and simulation logic. In parallel, three novel evaluation metrics, Structural Validity Rate (SVR), Parameter Match Rate (PMR), and Execution Success Rate (ESR), are proposed specifically for this task to comprehensively evaluate structural integrity, parameter fidelity, and simulator executability. Through systematic ablation across vision encoders, connectors, and code-pretrained language backbones, the proposed models achieve near-perfect structural accuracy and high execution robustness. This work establishes a foundation for generative digital twins that integrate visual reasoning and language understanding into executable industrial simulation systems. Read More
An Exploration of Higher Education Course Evaluation by Large Language Modelscs.AI updates on arXiv.org arXiv:2411.02455v2 Announce Type: replace-cross
Abstract: Course evaluation plays a critical role in ensuring instructional quality and guiding curriculum development in higher education. However, traditional evaluation methods, such as student surveys, classroom observations, and expert reviews, are often constrained by subjectivity, high labor costs, and limited scalability. With recent advancements in large language models (LLMs), new opportunities have emerged for generating consistent, fine-grained, and scalable course evaluations. This study investigates the use of three representative LLMs for automated course evaluation at both the micro level (classroom discussion analysis) and the macro level (holistic course review). Using classroom interaction transcripts and a dataset of 100 courses from a major institution in China, we demonstrate that LLMs can extract key pedagogical features and generate structured evaluation results aligned with expert judgement. A fine-tuned version of Llama shows superior reliability, producing score distributions with greater differentiation and stronger correlation with human evaluators than its counterparts. The results highlight three major findings: (1) LLMs can reliably perform systematic and interpretable course evaluations at both the micro and macro levels; (2) fine-tuning and prompt engineering significantly enhance evaluation accuracy and consistency; and (3) LLM-generated feedback provides actionable insights for teaching improvement. These findings illustrate the promise of LLM-based evaluation as a practical tool for supporting quality assurance and educational decision-making in large-scale higher education settings.
arXiv:2411.02455v2 Announce Type: replace-cross
Abstract: Course evaluation plays a critical role in ensuring instructional quality and guiding curriculum development in higher education. However, traditional evaluation methods, such as student surveys, classroom observations, and expert reviews, are often constrained by subjectivity, high labor costs, and limited scalability. With recent advancements in large language models (LLMs), new opportunities have emerged for generating consistent, fine-grained, and scalable course evaluations. This study investigates the use of three representative LLMs for automated course evaluation at both the micro level (classroom discussion analysis) and the macro level (holistic course review). Using classroom interaction transcripts and a dataset of 100 courses from a major institution in China, we demonstrate that LLMs can extract key pedagogical features and generate structured evaluation results aligned with expert judgement. A fine-tuned version of Llama shows superior reliability, producing score distributions with greater differentiation and stronger correlation with human evaluators than its counterparts. The results highlight three major findings: (1) LLMs can reliably perform systematic and interpretable course evaluations at both the micro and macro levels; (2) fine-tuning and prompt engineering significantly enhance evaluation accuracy and consistency; and (3) LLM-generated feedback provides actionable insights for teaching improvement. These findings illustrate the promise of LLM-based evaluation as a practical tool for supporting quality assurance and educational decision-making in large-scale higher education settings. Read More
Leash: Adaptive Length Penalty and Reward Shaping for Efficient Large Reasoning Modelcs.AI updates on arXiv.org arXiv:2512.21540v1 Announce Type: new
Abstract: Existing approaches typically rely on fixed length penalties, but such penalties are hard to tune and fail to adapt to the evolving reasoning abilities of LLMs, leading to suboptimal trade-offs between accuracy and conciseness. To address this challenge, we propose Leash (adaptive LEngth penAlty and reward SHaping), a reinforcement learning framework for efficient reasoning in LLMs. We formulate length control as a constrained optimization problem and employ a Lagrangian primal-dual method to dynamically adjust the penalty coefficient. When generations exceed the target length, the penalty is intensified; when they are shorter, it is relaxed. This adaptive mechanism guides models toward producing concise reasoning without sacrificing task performance. Experiments on Deepseek-R1-Distill-Qwen-1.5B and Qwen3-4B-Thinking-2507 show that Leash reduces the average reasoning length by 60% across diverse tasks – including in-distribution mathematical reasoning and out-of-distribution domains such as coding and instruction following – while maintaining competitive performance. Our work thus presents a practical and effective paradigm for developing controllable and efficient LLMs that balance reasoning capabilities with computational budgets.
arXiv:2512.21540v1 Announce Type: new
Abstract: Existing approaches typically rely on fixed length penalties, but such penalties are hard to tune and fail to adapt to the evolving reasoning abilities of LLMs, leading to suboptimal trade-offs between accuracy and conciseness. To address this challenge, we propose Leash (adaptive LEngth penAlty and reward SHaping), a reinforcement learning framework for efficient reasoning in LLMs. We formulate length control as a constrained optimization problem and employ a Lagrangian primal-dual method to dynamically adjust the penalty coefficient. When generations exceed the target length, the penalty is intensified; when they are shorter, it is relaxed. This adaptive mechanism guides models toward producing concise reasoning without sacrificing task performance. Experiments on Deepseek-R1-Distill-Qwen-1.5B and Qwen3-4B-Thinking-2507 show that Leash reduces the average reasoning length by 60% across diverse tasks – including in-distribution mathematical reasoning and out-of-distribution domains such as coding and instruction following – while maintaining competitive performance. Our work thus presents a practical and effective paradigm for developing controllable and efficient LLMs that balance reasoning capabilities with computational budgets. Read More
CP-Agent: Agentic Constraint Programmingcs.AI updates on arXiv.org arXiv:2508.07468v2 Announce Type: replace
Abstract: Translating natural language into formal constraint models requires expertise in the problem domain and modeling frameworks. To investigate whether constraint modeling benefits from agentic workflows, we introduce CP-Agent, a Python coding agent using the ReAct framework with a persistent IPython kernel. Domain knowledge is provided through a project prompt of under 50 lines. The agent iteratively executes code, observes the solver’s feedback, and refines models based on the execution results.
We evaluate CP-Agent on CP-Bench’s 101 constraint programming problems. We clarified the benchmark to address systematic ambiguities in problem specifications and errors in ground-truth models. On the clarified benchmark, CP-Agent solves all 101 problems. Ablation studies indicate that minimal guidance outperforms detailed procedural scaffolding, and that explicit task management tools have mixed effects on focused modeling tasks.
arXiv:2508.07468v2 Announce Type: replace
Abstract: Translating natural language into formal constraint models requires expertise in the problem domain and modeling frameworks. To investigate whether constraint modeling benefits from agentic workflows, we introduce CP-Agent, a Python coding agent using the ReAct framework with a persistent IPython kernel. Domain knowledge is provided through a project prompt of under 50 lines. The agent iteratively executes code, observes the solver’s feedback, and refines models based on the execution results.
We evaluate CP-Agent on CP-Bench’s 101 constraint programming problems. We clarified the benchmark to address systematic ambiguities in problem specifications and errors in ground-truth models. On the clarified benchmark, CP-Agent solves all 101 problems. Ablation studies indicate that minimal guidance outperforms detailed procedural scaffolding, and that explicit task management tools have mixed effects on focused modeling tasks. Read More