
Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated: 11/04/2025 Hello Everyone, Help us grow our community by sharing and/or supporting us on other platforms. This allow us to show verification that what we are doing is valued. It also allows us to plan and allocate resources to improve […]

Unlocking Reasoning Capabilities in LLMs via Reinforcement Learning Explorationcs.AI updates on arXiv.org arXiv:2510.03865v2 Announce Type: replace-cross
Abstract: Reinforcement learning with verifiable rewards (RLVR) has recently enhanced the reasoning capabilities of large language models (LLMs), particularly for mathematical problem solving. However, a fundamental limitation remains: as the sampling budget increases, the advantage of RLVR-trained models over their pretrained bases often diminishes or even vanishes, revealing a strong dependence on the base model’s restricted search space. We attribute this phenomenon to the widespread use of the reverse Kullback-Leibler (KL) divergence regularizer, whose mode-seeking behavior keeps the policy trapped inside the base model’s support region and hampers wider exploration. To address this issue, we propose RAPO (Rewards-Aware Policy Optimization), an algorithm to promote broader yet focused exploration. Our method (i) utilizes the forward KL penalty to replace the reverse KL penalty for out-of-distribution exploration, and (ii) reweights the reference policy to facilitate adaptive in-distribution exploration. We train Qwen2.5-3B and 7B models with RAPO on the 8K SimpleRL-Zero dataset, without supervised fine-tuning, and evaluate them on AIME2024 and AIME2025. Results show that RAPO consistently improves problem-solving performance. Notably, RAPO enables models to surpass the base model’s performance ceiling and solves previously intractable problems, advancing the frontier of RLVR for challenging reasoning tasks.
arXiv:2510.03865v2 Announce Type: replace-cross
Abstract: Reinforcement learning with verifiable rewards (RLVR) has recently enhanced the reasoning capabilities of large language models (LLMs), particularly for mathematical problem solving. However, a fundamental limitation remains: as the sampling budget increases, the advantage of RLVR-trained models over their pretrained bases often diminishes or even vanishes, revealing a strong dependence on the base model’s restricted search space. We attribute this phenomenon to the widespread use of the reverse Kullback-Leibler (KL) divergence regularizer, whose mode-seeking behavior keeps the policy trapped inside the base model’s support region and hampers wider exploration. To address this issue, we propose RAPO (Rewards-Aware Policy Optimization), an algorithm to promote broader yet focused exploration. Our method (i) utilizes the forward KL penalty to replace the reverse KL penalty for out-of-distribution exploration, and (ii) reweights the reference policy to facilitate adaptive in-distribution exploration. We train Qwen2.5-3B and 7B models with RAPO on the 8K SimpleRL-Zero dataset, without supervised fine-tuning, and evaluate them on AIME2024 and AIME2025. Results show that RAPO consistently improves problem-solving performance. Notably, RAPO enables models to surpass the base model’s performance ceiling and solves previously intractable problems, advancing the frontier of RLVR for challenging reasoning tasks. Read More
EBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilitiescs.AI updates on arXiv.org arXiv:2510.27545v1 Announce Type: cross
Abstract: Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy’s 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
arXiv:2510.27545v1 Announce Type: cross
Abstract: Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy’s 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts. Read More
Red Teaming AI Red Teamingcs.AI updates on arXiv.org arXiv:2507.05538v2 Announce Type: replace
Abstract: Red teaming has evolved from its origins in military applications to become a widely adopted methodology in cybersecurity and AI. In this paper, we take a critical look at the practice of AI red teaming. We argue that despite its current popularity in AI governance, there exists a significant gap between red teaming’s original intent as a critical thinking exercise and its narrow focus on discovering model-level flaws in the context of generative AI. Current AI red teaming efforts focus predominantly on individual model vulnerabilities while overlooking the broader sociotechnical systems and emergent behaviors that arise from complex interactions between models, users, and environments. To address this deficiency, we propose a comprehensive framework operationalizing red teaming in AI systems at two levels: macro-level system red teaming spanning the entire AI development lifecycle, and micro-level model red teaming. Drawing on cybersecurity experience and systems theory, we further propose a set of six recommendations. In these, we emphasize that effective AI red teaming requires multifunctional teams that examine emergent risks, systemic vulnerabilities, and the interplay between technical and social factors.
arXiv:2507.05538v2 Announce Type: replace
Abstract: Red teaming has evolved from its origins in military applications to become a widely adopted methodology in cybersecurity and AI. In this paper, we take a critical look at the practice of AI red teaming. We argue that despite its current popularity in AI governance, there exists a significant gap between red teaming’s original intent as a critical thinking exercise and its narrow focus on discovering model-level flaws in the context of generative AI. Current AI red teaming efforts focus predominantly on individual model vulnerabilities while overlooking the broader sociotechnical systems and emergent behaviors that arise from complex interactions between models, users, and environments. To address this deficiency, we propose a comprehensive framework operationalizing red teaming in AI systems at two levels: macro-level system red teaming spanning the entire AI development lifecycle, and micro-level model red teaming. Drawing on cybersecurity experience and systems theory, we further propose a set of six recommendations. In these, we emphasize that effective AI red teaming requires multifunctional teams that examine emergent risks, systemic vulnerabilities, and the interplay between technical and social factors. Read More
What Building My First Dashboard Taught Me About Data StorytellingTowards Data Science Why clarity beats complexity when turning data into stories people actually understand
The post What Building My First Dashboard Taught Me About Data Storytelling appeared first on Towards Data Science.
Why clarity beats complexity when turning data into stories people actually understand
The post What Building My First Dashboard Taught Me About Data Storytelling appeared first on Towards Data Science. Read More
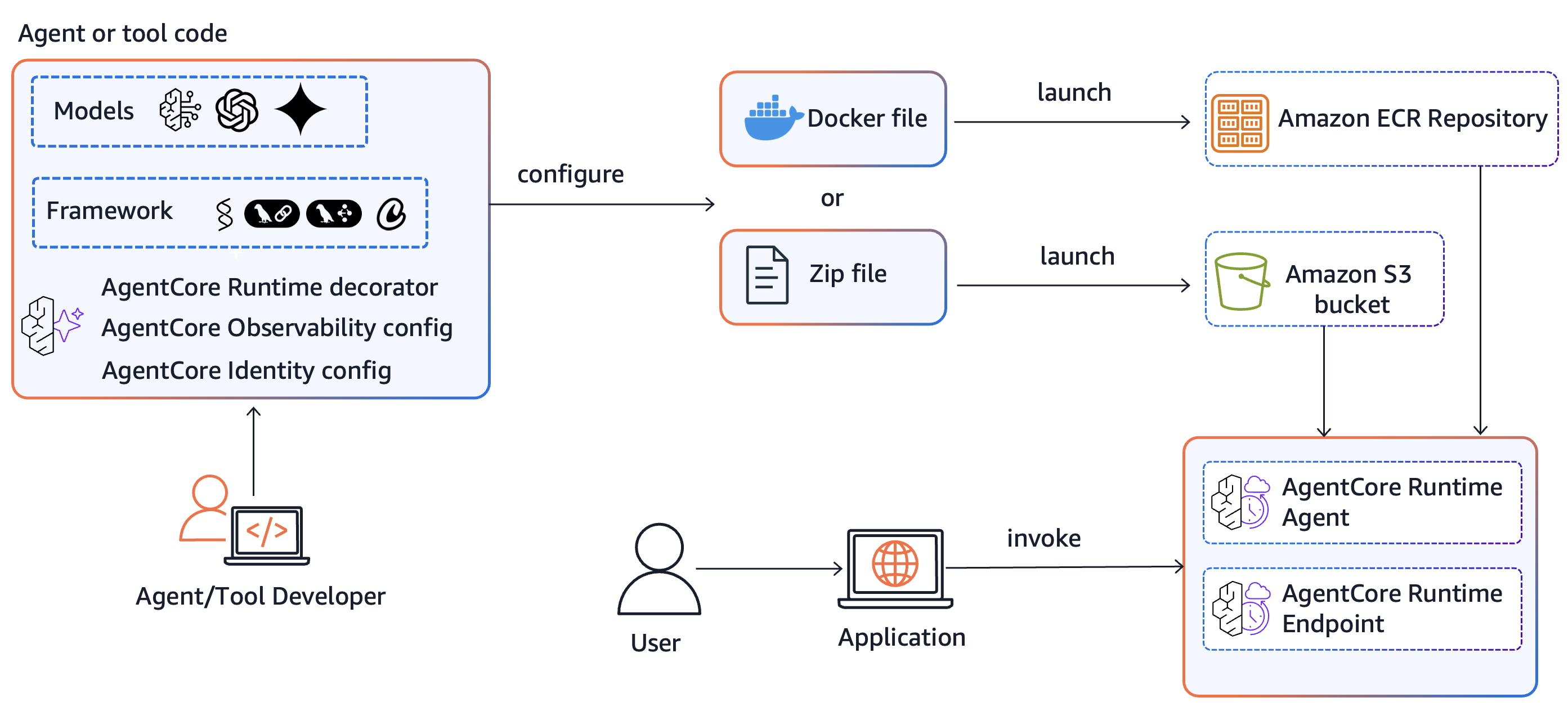
Iterate faster with Amazon Bedrock AgentCore Runtime direct code deploymentArtificial Intelligence Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. Amazon Bedrock AgentCore Runtime is a fully managed service of Bedrock AgentCore, which provides low latency serverless environments to deploy agents and tools. It provides session isolation, supports multiple agent frameworks including popular open-source frameworks, and handles multimodal
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. Amazon Bedrock AgentCore Runtime is a fully managed service of Bedrock AgentCore, which provides low latency serverless environments to deploy agents and tools. It provides session isolation, supports multiple agent frameworks including popular open-source frameworks, and handles multimodal Read More
What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later Towards Data Science
What to Do When Your Credit Risk Model Works Today, but Breaks Six Months LaterTowards Data Science Here’s why it happens — and how to fix it
The post What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later appeared first on Towards Data Science.
Here’s why it happens — and how to fix it
The post What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later appeared first on Towards Data Science. Read More
Train a Humanoid Robot with AI and PythonTowards Data Science 3D simulations and Reinforcement Learning with MuJoCo and Gym
The post Train a Humanoid Robot with AI and Python appeared first on Towards Data Science.
3D simulations and Reinforcement Learning with MuJoCo and Gym
The post Train a Humanoid Robot with AI and Python appeared first on Towards Data Science. Read More

Beginner’s Guide to Data Extraction with LangExtract and LLMsKDnuggets If you need to pull specific data from text, LangExtract offers a fast, flexible, and beginner‑friendly way to do it.
If you need to pull specific data from text, LangExtract offers a fast, flexible, and beginner‑friendly way to do it. Read More

Cloud 101 for Business Owners (Sponsored)KDnuggets If you’ve been hearing about “the cloud” for years but still aren’t sure what it means for your business, we get it. Let’s cut through the noise.
If you’ve been hearing about “the cloud” for years but still aren’t sure what it means for your business, we get it. Let’s cut through the noise. Read More