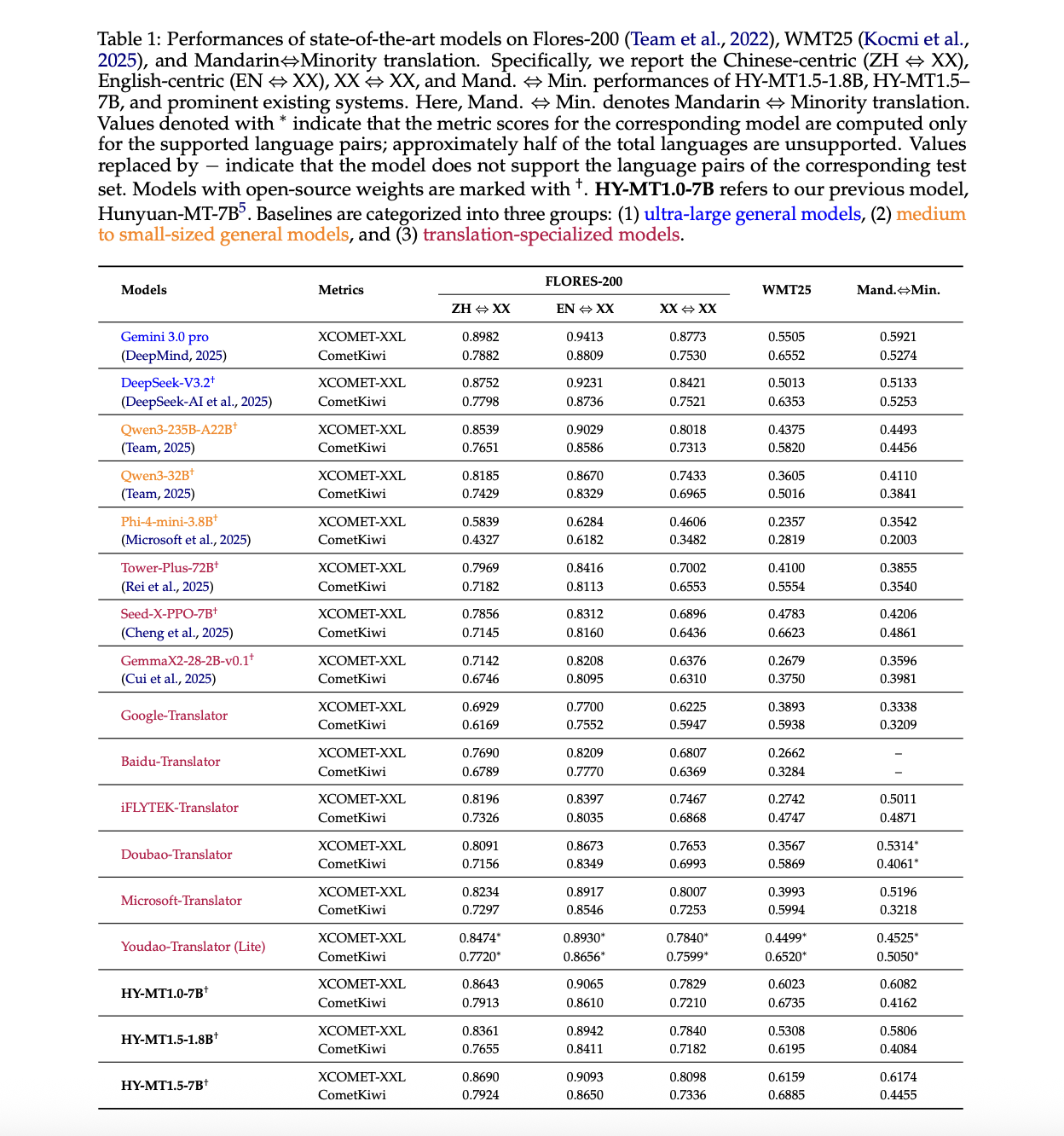
Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud DeploymentMarkTechPost Tencent Hunyuan researchers have released HY-MT1.5, a multilingual machine translation family that targets both mobile devices and cloud systems with the same training recipe and metrics. HY-MT1.5 consists of 2 translation models, HY-MT1.5-1.8B and HY-MT1.5-7B, supports mutual translation across 33 languages with 5 ethnic and dialect variations, and is available on GitHub and Hugging Face
The post Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment appeared first on MarkTechPost.
Tencent Hunyuan researchers have released HY-MT1.5, a multilingual machine translation family that targets both mobile devices and cloud systems with the same training recipe and metrics. HY-MT1.5 consists of 2 translation models, HY-MT1.5-1.8B and HY-MT1.5-7B, supports mutual translation across 33 languages with 5 ethnic and dialect variations, and is available on GitHub and Hugging Face
The post Tencent Researchers Release Tencent HY-MT1.5: A New Translation Models Featuring 1.8B and 7B Models Designed for Seamless on-Device and Cloud Deployment appeared first on MarkTechPost. Read More

AI Interview Series #5: Prompt CachingMarkTechPost Question: Imagine your company’s LLM API costs suddenly doubled last month. A deeper analysis shows that while user inputs look different at a text level, many of them are semantically similar. As an engineer, how would you identify and reduce this redundancy without impacting response quality? What is Prompt Caching? Prompt caching is an optimization
The post AI Interview Series #5: Prompt Caching appeared first on MarkTechPost.
Question: Imagine your company’s LLM API costs suddenly doubled last month. A deeper analysis shows that while user inputs look different at a text level, many of them are semantically similar. As an engineer, how would you identify and reduce this redundancy without impacting response quality? What is Prompt Caching? Prompt caching is an optimization
The post AI Interview Series #5: Prompt Caching appeared first on MarkTechPost. Read More

Reasoning in Action: MCTS-Driven Knowledge Retrieval for Large Language Modelscs.AI updates on arXiv.org arXiv:2601.00003v1 Announce Type: new
Abstract: Large language models (LLMs) typically enhance their performance through either the retrieval of semantically similar information or the improvement of their reasoning capabilities. However, a significant challenge remains in effectively integrating both retrieval and reasoning strategies to optimize LLM performance. In this paper, we introduce a reasoning-aware knowledge retrieval method that enriches LLMs with information aligned to the logical structure of conversations, moving beyond surface-level semantic similarity. We follow a coarse-to-fine approach for knowledge retrieval. First, we identify a contextually relevant sub-region of the knowledge base, ensuring that all sentences within it are relevant to the context topic. Next, we refine our search within this sub-region to extract knowledge that is specifically relevant to the reasoning process. Throughout both phases, we employ the Monte Carlo Tree Search-inspired search method to effectively navigate through knowledge sentences using common keywords. Experiments on two multi-turn dialogue datasets demonstrate that our knowledge retrieval approach not only aligns more closely with the underlying reasoning in human conversations but also significantly enhances the diversity of the retrieved knowledge, resulting in more informative and creative responses.
arXiv:2601.00003v1 Announce Type: new
Abstract: Large language models (LLMs) typically enhance their performance through either the retrieval of semantically similar information or the improvement of their reasoning capabilities. However, a significant challenge remains in effectively integrating both retrieval and reasoning strategies to optimize LLM performance. In this paper, we introduce a reasoning-aware knowledge retrieval method that enriches LLMs with information aligned to the logical structure of conversations, moving beyond surface-level semantic similarity. We follow a coarse-to-fine approach for knowledge retrieval. First, we identify a contextually relevant sub-region of the knowledge base, ensuring that all sentences within it are relevant to the context topic. Next, we refine our search within this sub-region to extract knowledge that is specifically relevant to the reasoning process. Throughout both phases, we employ the Monte Carlo Tree Search-inspired search method to effectively navigate through knowledge sentences using common keywords. Experiments on two multi-turn dialogue datasets demonstrate that our knowledge retrieval approach not only aligns more closely with the underlying reasoning in human conversations but also significantly enhances the diversity of the retrieved knowledge, resulting in more informative and creative responses. Read More
Narrative-to-Scene Generation: An LLM-Driven Pipeline for 2D Game Environmentscs.AI updates on arXiv.org arXiv:2509.04481v2 Announce Type: replace-cross
Abstract: Recent advances in large language models (LLMs) enable compelling story generation, but connecting narrative text to playable visual environments remains an open challenge in procedural content generation (PCG). We present a lightweight pipeline that transforms short narrative prompts into a sequence of 2D tile-based game scenes, reflecting the temporal structure of stories. Given an LLM-generated narrative, our system identifies three key time frames, extracts spatial predicates in the form of “Object-Relation-Object” triples, and retrieves visual assets using affordance-aware semantic embeddings from the GameTileNet dataset. A layered terrain is generated using Cellular Automata, and objects are placed using spatial rules grounded in the predicate structure. We evaluated our system in ten diverse stories, analyzing tile-object matching, affordance-layer alignment, and spatial constraint satisfaction across frames. This prototype offers a scalable approach to narrative-driven scene generation and lays the foundation for future work on multi-frame continuity, symbolic tracking, and multi-agent coordination in story-centered PCG.
arXiv:2509.04481v2 Announce Type: replace-cross
Abstract: Recent advances in large language models (LLMs) enable compelling story generation, but connecting narrative text to playable visual environments remains an open challenge in procedural content generation (PCG). We present a lightweight pipeline that transforms short narrative prompts into a sequence of 2D tile-based game scenes, reflecting the temporal structure of stories. Given an LLM-generated narrative, our system identifies three key time frames, extracts spatial predicates in the form of “Object-Relation-Object” triples, and retrieves visual assets using affordance-aware semantic embeddings from the GameTileNet dataset. A layered terrain is generated using Cellular Automata, and objects are placed using spatial rules grounded in the predicate structure. We evaluated our system in ten diverse stories, analyzing tile-object matching, affordance-layer alignment, and spatial constraint satisfaction across frames. This prototype offers a scalable approach to narrative-driven scene generation and lays the foundation for future work on multi-frame continuity, symbolic tracking, and multi-agent coordination in story-centered PCG. Read More

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated: January 28th, 2026 NIST AI RMF Function Overviews: View Articles What is NIST AI RMF Measure? What is NIST AI RMF Measure? It’s the function that answers a critical question: can you prove your AI system actually works […]
Prompt Engineering vs RAG for Editing ResumesTowards Data Science Running a code-free comparison in Azure
The post Prompt Engineering vs RAG for Editing Resumes appeared first on Towards Data Science.
Running a code-free comparison in Azure
The post Prompt Engineering vs RAG for Editing Resumes appeared first on Towards Data Science. Read More
How to Filter for Dates, Including or Excluding Future Dates, in Semantic ModelsTowards Data Science It is common to have either planning data or the previous year’s data displayed beyond today’s date. But future data can be confusing. How can I add a Slicer to show or hide future data? Let’s see how to do it.
The post How to Filter for Dates, Including or Excluding Future Dates, in Semantic Models appeared first on Towards Data Science.
It is common to have either planning data or the previous year’s data displayed beyond today’s date. But future data can be confusing. How can I add a Slicer to show or hide future data? Let’s see how to do it.
The post How to Filter for Dates, Including or Excluding Future Dates, in Semantic Models appeared first on Towards Data Science. Read More
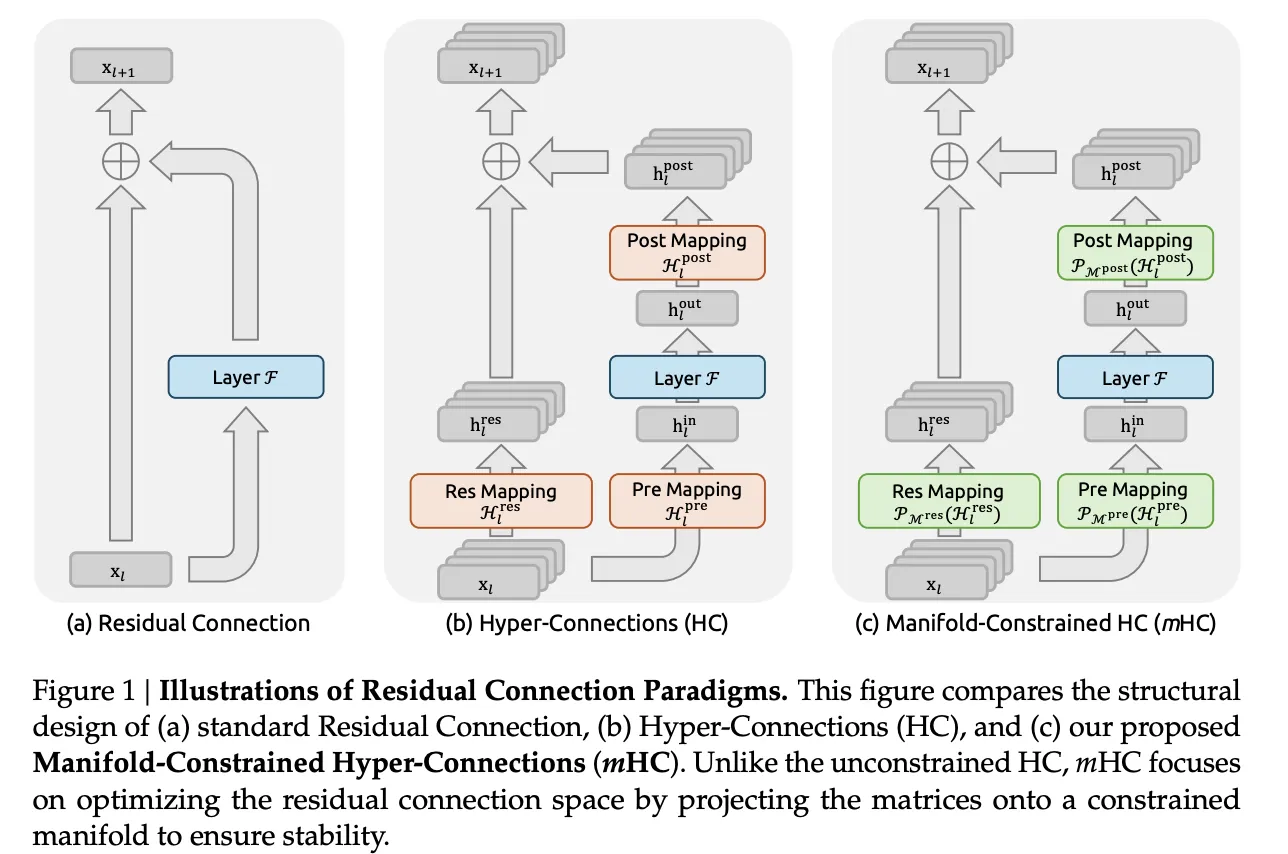
DeepSeek Researchers Apply a 1967 Matrix Normalization Algorithm to Fix Instability in Hyper ConnectionsMarkTechPost DeepSeek researchers are trying to solve a precise issue in large language model training. Residual connections made very deep networks trainable, hyper connections widened that residual stream, and training then became unstable at scale. The new method mHC, Manifold Constrained Hyper Connections, keeps the richer topology of hyper connections but locks the mixing behavior on
The post DeepSeek Researchers Apply a 1967 Matrix Normalization Algorithm to Fix Instability in Hyper Connections appeared first on MarkTechPost.
DeepSeek researchers are trying to solve a precise issue in large language model training. Residual connections made very deep networks trainable, hyper connections widened that residual stream, and training then became unstable at scale. The new method mHC, Manifold Constrained Hyper Connections, keeps the richer topology of hyper connections but locks the mixing behavior on
The post DeepSeek Researchers Apply a 1967 Matrix Normalization Algorithm to Fix Instability in Hyper Connections appeared first on MarkTechPost. Read More
How to Build a Production-Ready Multi-Agent Incident Response System Using OpenAI Swarm and Tool-Augmented AgentsMarkTechPost In this tutorial, we build an advanced yet practical multi-agent system using OpenAI Swarm that runs in Colab. We demonstrate how we can orchestrate specialized agents, such as a triage agent, an SRE agent, a communications agent, and a critic, to collaboratively handle a real-world production incident scenario. By structuring agent handoffs, integrating lightweight tools
The post How to Build a Production-Ready Multi-Agent Incident Response System Using OpenAI Swarm and Tool-Augmented Agents appeared first on MarkTechPost.
In this tutorial, we build an advanced yet practical multi-agent system using OpenAI Swarm that runs in Colab. We demonstrate how we can orchestrate specialized agents, such as a triage agent, an SRE agent, a communications agent, and a critic, to collaboratively handle a real-world production incident scenario. By structuring agent handoffs, integrating lightweight tools
The post How to Build a Production-Ready Multi-Agent Incident Response System Using OpenAI Swarm and Tool-Augmented Agents appeared first on MarkTechPost. Read More
Optimizing Data Transfer in AI/ML WorkloadsTowards Data Science A deep dive on data transfer bottlenecks, their identification, and their resolution with the help of NVIDIA Nsight™ Systems
The post Optimizing Data Transfer in AI/ML Workloads appeared first on Towards Data Science.
A deep dive on data transfer bottlenecks, their identification, and their resolution with the help of NVIDIA Nsight™ Systems
The post Optimizing Data Transfer in AI/ML Workloads appeared first on Towards Data Science. Read More