
Faithful-First Reasoning, Planning, and Acting for Multimodal LLMscs.AI updates on arXiv.org arXiv:2511.08409v3 Announce Type: replace
Abstract: Multimodal Large Language Models (MLLMs) frequently suffer from unfaithfulness, generating reasoning chains that drift from visual evidence or contradict final predictions. We propose Faithful-First Reasoning, Planning, and Acting (RPA) framework in which FaithEvi provides step-wise and chain-level supervision by evaluating the faithfulness of intermediate reasoning, and FaithAct uses these signals to plan and execute faithfulness-aware actions during inference. Experiments across multiple multimodal reasoning benchmarks show that faithful-first RPA improves perceptual faithfulness by up to 24% over prompt-based and tool-augmented reasoning frameworks, without degrading task accuracy. Our analysis shows that treating faithfulness as a guiding principle perceptually faithful reasoning trajectories and mitigates hallucination behavior. This work thereby establishes a unified framework for both evaluating and enforcing faithfulness in multimodal reasoning. Code will be released upon acceptance.
arXiv:2511.08409v3 Announce Type: replace
Abstract: Multimodal Large Language Models (MLLMs) frequently suffer from unfaithfulness, generating reasoning chains that drift from visual evidence or contradict final predictions. We propose Faithful-First Reasoning, Planning, and Acting (RPA) framework in which FaithEvi provides step-wise and chain-level supervision by evaluating the faithfulness of intermediate reasoning, and FaithAct uses these signals to plan and execute faithfulness-aware actions during inference. Experiments across multiple multimodal reasoning benchmarks show that faithful-first RPA improves perceptual faithfulness by up to 24% over prompt-based and tool-augmented reasoning frameworks, without degrading task accuracy. Our analysis shows that treating faithfulness as a guiding principle perceptually faithful reasoning trajectories and mitigates hallucination behavior. This work thereby establishes a unified framework for both evaluating and enforcing faithfulness in multimodal reasoning. Code will be released upon acceptance. Read More
Analyzing Reasoning Consistency in Large Multimodal Models under Cross-Modal Conflictscs.AI updates on arXiv.org arXiv:2601.04073v1 Announce Type: cross
Abstract: Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness.
arXiv:2601.04073v1 Announce Type: cross
Abstract: Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness. Read More
Personalization of Large Foundation Models for Health Interventionscs.AI updates on arXiv.org arXiv:2601.03482v1 Announce Type: new
Abstract: Large foundation models (LFMs) transform healthcare AI in prevention, diagnostics, and treatment. However, whether LFMs can provide truly personalized treatment recommendations remains an open question. Recent research has revealed multiple challenges for personalization, including the fundamental generalizability paradox: models achieving high accuracy in one clinical study perform at chance level in others, demonstrating that personalization and external validity exist in tension. This exemplifies broader contradictions in AI-driven healthcare: the privacy-performance paradox, scale-specificity paradox, and the automation-empathy paradox. As another challenge, the degree of causal understanding required for personalized recommendations, as opposed to mere predictive capacities of LFMs, remains an open question. N-of-1 trials — crossover self-experiments and the gold standard for individual causal inference in personalized medicine — resolve these tensions by providing within-person causal evidence while preserving privacy through local experimentation. Despite their impressive capabilities, this paper argues that LFMs cannot replace N-of-1 trials. We argue that LFMs and N-of-1 trials are complementary: LFMs excel at rapid hypothesis generation from population patterns using multimodal data, while N-of-1 trials excel at causal validation for a given individual. We propose a hybrid framework that combines the strengths of both to enable personalization and navigate the identified paradoxes: LFMs generate ranked intervention candidates with uncertainty estimates, which trigger subsequent N-of-1 trials. Clarifying the boundary between prediction and causation and explicitly addressing the paradoxical tensions are essential for responsible AI integration in personalized medicine.
arXiv:2601.03482v1 Announce Type: new
Abstract: Large foundation models (LFMs) transform healthcare AI in prevention, diagnostics, and treatment. However, whether LFMs can provide truly personalized treatment recommendations remains an open question. Recent research has revealed multiple challenges for personalization, including the fundamental generalizability paradox: models achieving high accuracy in one clinical study perform at chance level in others, demonstrating that personalization and external validity exist in tension. This exemplifies broader contradictions in AI-driven healthcare: the privacy-performance paradox, scale-specificity paradox, and the automation-empathy paradox. As another challenge, the degree of causal understanding required for personalized recommendations, as opposed to mere predictive capacities of LFMs, remains an open question. N-of-1 trials — crossover self-experiments and the gold standard for individual causal inference in personalized medicine — resolve these tensions by providing within-person causal evidence while preserving privacy through local experimentation. Despite their impressive capabilities, this paper argues that LFMs cannot replace N-of-1 trials. We argue that LFMs and N-of-1 trials are complementary: LFMs excel at rapid hypothesis generation from population patterns using multimodal data, while N-of-1 trials excel at causal validation for a given individual. We propose a hybrid framework that combines the strengths of both to enable personalization and navigate the identified paradoxes: LFMs generate ranked intervention candidates with uncertainty estimates, which trigger subsequent N-of-1 trials. Clarifying the boundary between prediction and causation and explicitly addressing the paradoxical tensions are essential for responsible AI integration in personalized medicine. Read More
CPGPrompt: Translating Clinical Guidelines into LLM-Executable Decision Supportcs.AI updates on arXiv.org arXiv:2601.03475v1 Announce Type: new
Abstract: Clinical practice guidelines (CPGs) provide evidence-based recommendations for patient care; however, integrating them into Artificial Intelligence (AI) remains challenging. Previous approaches, such as rule-based systems, face significant limitations, including poor interpretability, inconsistent adherence to guidelines, and narrow domain applicability. To address this, we develop and validate CPGPrompt, an auto-prompting system that converts narrative clinical guidelines into large language models (LLMs).
Our framework translates CPGs into structured decision trees and utilizes an LLM to dynamically navigate them for patient case evaluation. Synthetic vignettes were generated across three domains (headache, lower back pain, and prostate cancer) and distributed into four categories to test different decision scenarios. System performance was assessed on both binary specialty-referral decisions and fine-grained pathway-classification tasks.
The binary specialty referral classification achieved consistently strong performance across all domains (F1: 0.85-1.00), with high recall (1.00 $pm$ 0.00). In contrast, multi-class pathway assignment showed reduced performance, with domain-specific variations: headache (F1: 0.47), lower back pain (F1: 0.72), and prostate cancer (F1: 0.77). Domain-specific performance differences reflected the structure of each guideline. The headache guideline highlighted challenges with negation handling. The lower back pain guideline required temporal reasoning. In contrast, prostate cancer pathways benefited from quantifiable laboratory tests, resulting in more reliable decision-making.
arXiv:2601.03475v1 Announce Type: new
Abstract: Clinical practice guidelines (CPGs) provide evidence-based recommendations for patient care; however, integrating them into Artificial Intelligence (AI) remains challenging. Previous approaches, such as rule-based systems, face significant limitations, including poor interpretability, inconsistent adherence to guidelines, and narrow domain applicability. To address this, we develop and validate CPGPrompt, an auto-prompting system that converts narrative clinical guidelines into large language models (LLMs).
Our framework translates CPGs into structured decision trees and utilizes an LLM to dynamically navigate them for patient case evaluation. Synthetic vignettes were generated across three domains (headache, lower back pain, and prostate cancer) and distributed into four categories to test different decision scenarios. System performance was assessed on both binary specialty-referral decisions and fine-grained pathway-classification tasks.
The binary specialty referral classification achieved consistently strong performance across all domains (F1: 0.85-1.00), with high recall (1.00 $pm$ 0.00). In contrast, multi-class pathway assignment showed reduced performance, with domain-specific variations: headache (F1: 0.47), lower back pain (F1: 0.72), and prostate cancer (F1: 0.77). Domain-specific performance differences reflected the structure of each guideline. The headache guideline highlighted challenges with negation handling. The lower back pain guideline required temporal reasoning. In contrast, prostate cancer pathways benefited from quantifiable laboratory tests, resulting in more reliable decision-making. Read More

Agentic AI scaling requires new memory architectureAI News Agentic AI represents a distinct evolution from stateless chatbots toward complex workflows, and scaling it requires new memory architecture. As foundation models scale toward trillions of parameters and context windows reach millions of tokens, the computational cost of remembering history is rising faster than the ability to process it. Organisations deploying these systems now face
The post Agentic AI scaling requires new memory architecture appeared first on AI News.
Agentic AI represents a distinct evolution from stateless chatbots toward complex workflows, and scaling it requires new memory architecture. As foundation models scale toward trillions of parameters and context windows reach millions of tokens, the computational cost of remembering history is rising faster than the ability to process it. Organisations deploying these systems now face
The post Agentic AI scaling requires new memory architecture appeared first on AI News. Read More

Vibe Code Reality Check: What You Can Actually Build with Only AIKDnuggets This is an “expectations vs reality” approach to demystify, based on research of real success and failure stories, what are the capabilities and limits of vibe coding.
This is an “expectations vs reality” approach to demystify, based on research of real success and failure stories, what are the capabilities and limits of vibe coding. Read More
HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database GrowsTowards Data Science How approximate vector search silently degrades Recall—and what to do about It
The post HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database Grows appeared first on Towards Data Science.
How approximate vector search silently degrades Recall—and what to do about It
The post HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database Grows appeared first on Towards Data Science. Read More
Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted OptionsTowards Data Science Human-guided AI collaboration
The post Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted Options appeared first on Towards Data Science.
Human-guided AI collaboration
The post Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted Options appeared first on Towards Data Science. Read More
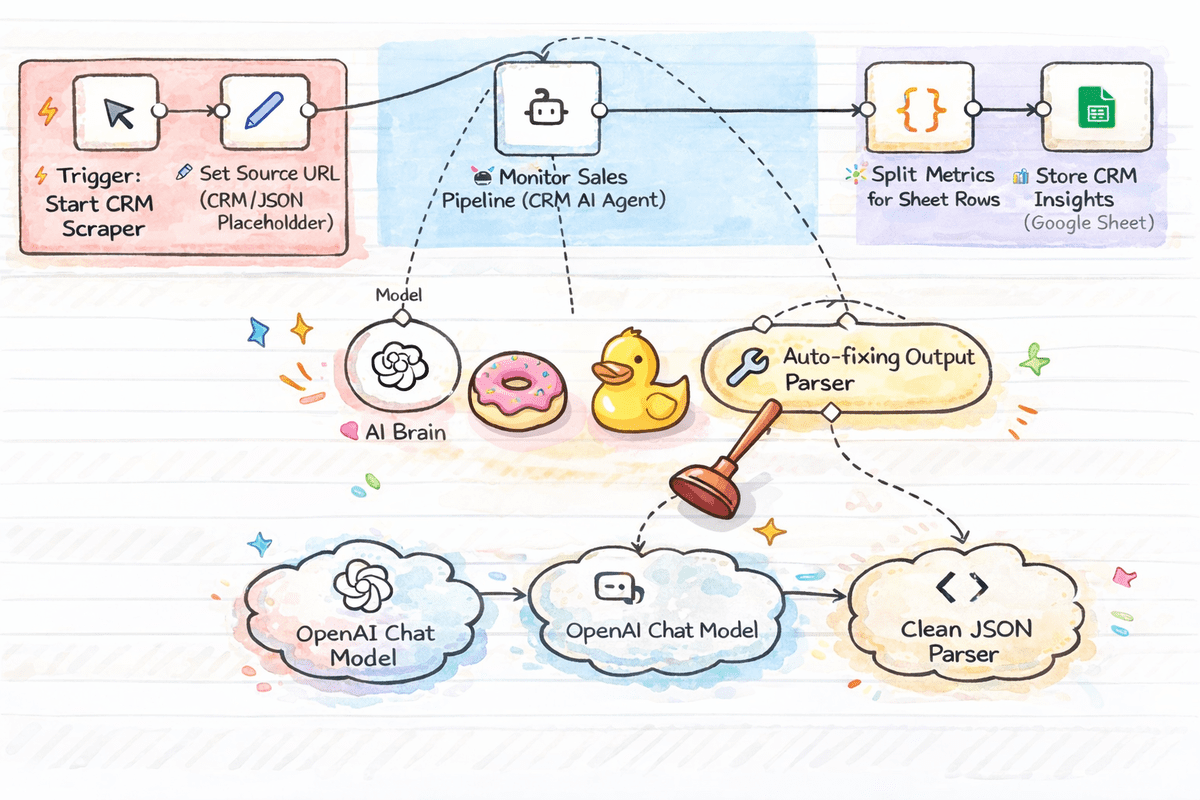
Top 7 n8n Workflow Templates for Data ScienceKDnuggets A list of ready to use n8n workflow templates that help data scientists quickly analyze data, extract and transform it, and build reliable knowledge bases.
A list of ready to use n8n workflow templates that help data scientists quickly analyze data, extract and transform it, and build reliable knowledge bases. Read More
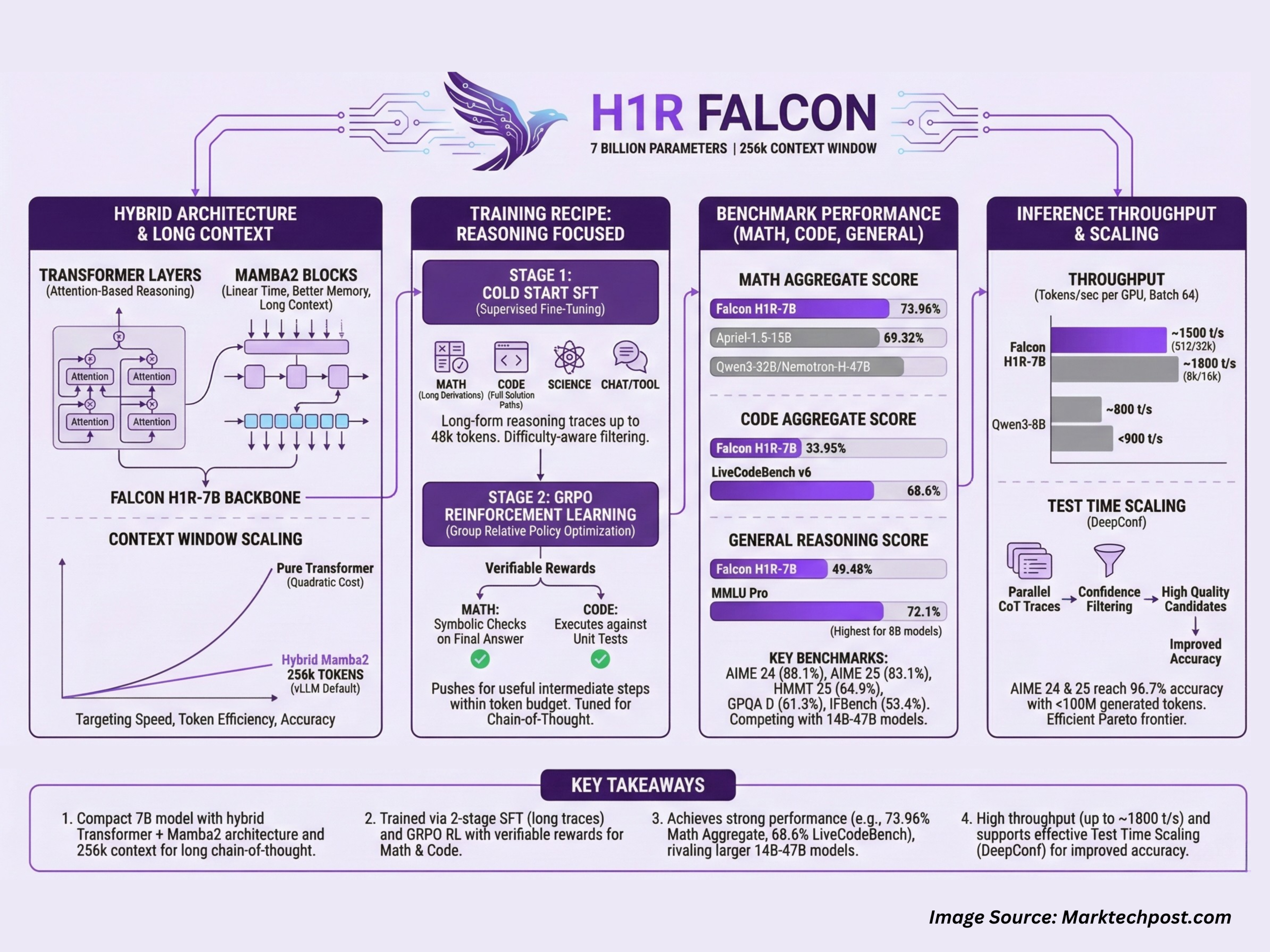
TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context WindowMarkTechPost Technology Innovation Institute (TII), Abu Dhabi, has released Falcon-H1R-7B, a 7B parameter reasoning specialized model that matches or exceeds many 14B to 47B reasoning models in math, code and general benchmarks, while staying compact and efficient. It builds on Falcon H1 7B Base and is available on Hugging Face under the Falcon-H1R collection. Falcon-H1R-7B is
The post TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window appeared first on MarkTechPost.
Technology Innovation Institute (TII), Abu Dhabi, has released Falcon-H1R-7B, a 7B parameter reasoning specialized model that matches or exceeds many 14B to 47B reasoning models in math, code and general benchmarks, while staying compact and efficient. It builds on Falcon H1 7B Base and is available on Hugging Face under the Falcon-H1R collection. Falcon-H1R-7B is
The post TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window appeared first on MarkTechPost. Read More