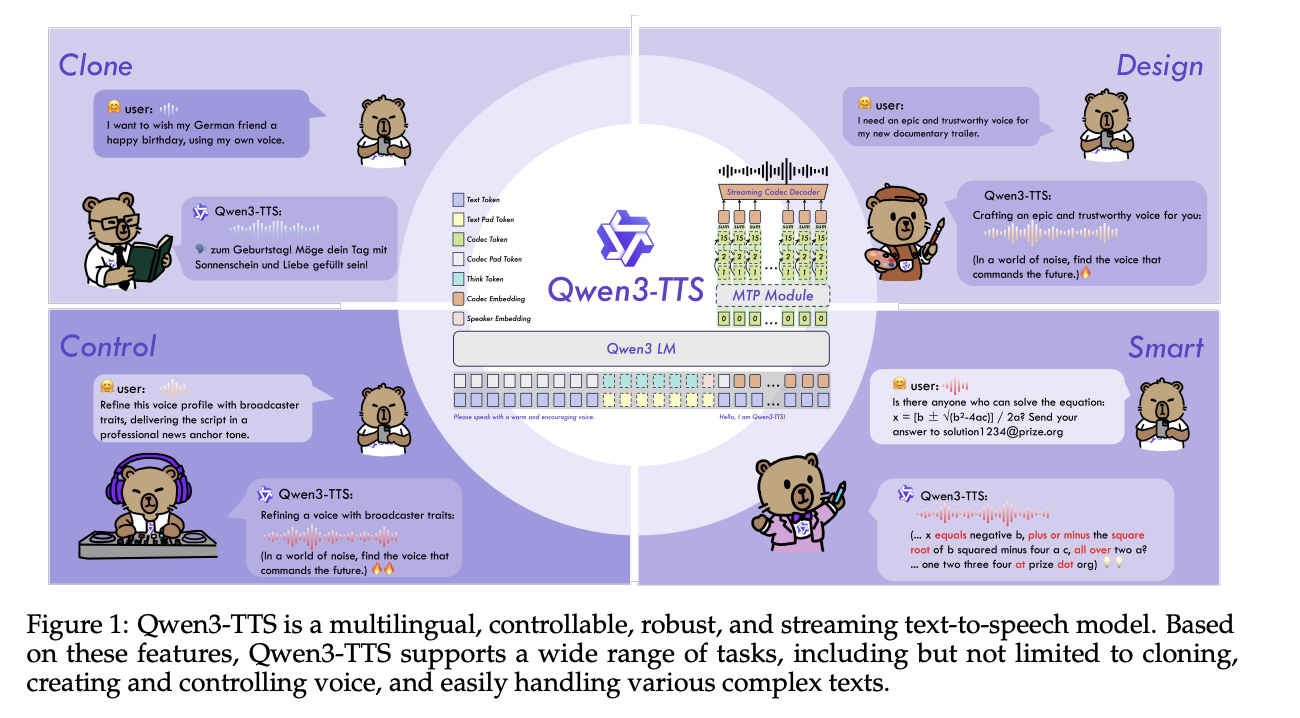
Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice ControlMarkTechPost Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost.
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost. Read More

Knowing When to Abstain: Medical LLMs Under Clinical Uncertaintycs.AI updates on arXiv.org arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications.
arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications. Read More
Scaling PostgreSQL to power 800 million ChatGPT usersOpenAI News An inside look at how OpenAI scaled PostgreSQL to millions of queries per second using replicas, caching, rate limiting, and workload isolation.
An inside look at how OpenAI scaled PostgreSQL to millions of queries per second using replicas, caching, rate limiting, and workload isolation. Read More
Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural MetricsTowards Data Science How to evaluate goal-oriented content designed to build engagement and deliver business results, and why structure matters.
The post Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural Metrics appeared first on Towards Data Science.
How to evaluate goal-oriented content designed to build engagement and deliver business results, and why structure matters.
The post Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural Metrics appeared first on Towards Data Science. Read More

Open Notebook: A True Open Source Private NotebookLM Alternative?KDnuggets Open Notebook is an open-source, AI-powered platform designed to help users take, organize, and interact with notes while keeping full control over their data.
Open Notebook is an open-source, AI-powered platform designed to help users take, organize, and interact with notes while keeping full control over their data. Read More
Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026Towards Data Science How I use analytics, automation, and AI to build better SaaS
The post Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026 appeared first on Towards Data Science.
How I use analytics, automation, and AI to build better SaaS
The post Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026 appeared first on Towards Data Science. Read More
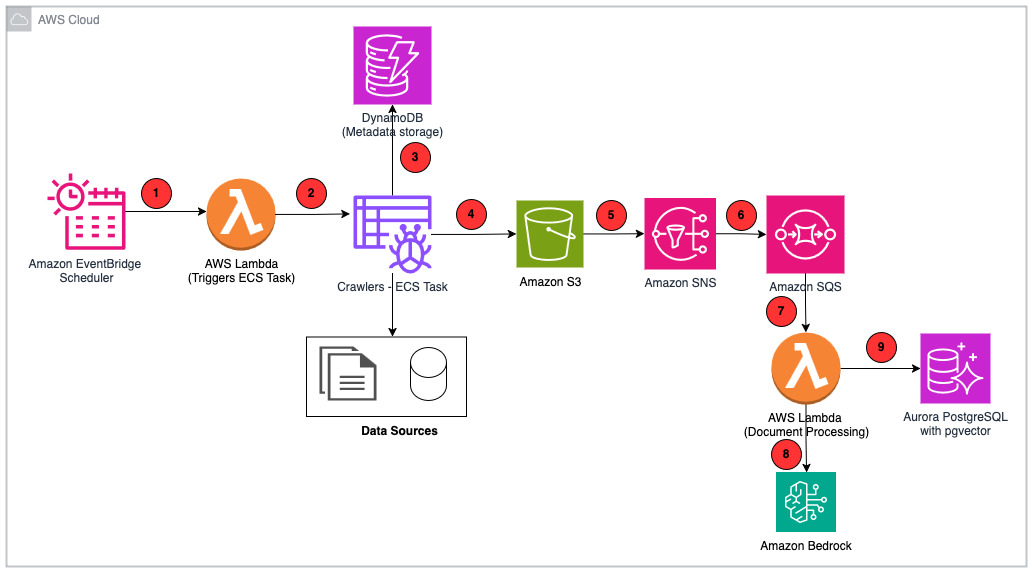
How PDI built an enterprise-grade RAG system for AI applications with AWSArtificial Intelligence PDI Technologies is a global leader in the convenience retail and petroleum wholesale industries. In this post, we walk through the PDI Intelligence Query (PDIQ) process flow and architecture, focusing on the implementation details and the business outcomes it has helped PDI achieve.
PDI Technologies is a global leader in the convenience retail and petroleum wholesale industries. In this post, we walk through the PDI Intelligence Query (PDIQ) process flow and architecture, focusing on the implementation details and the business outcomes it has helped PDI achieve. Read More
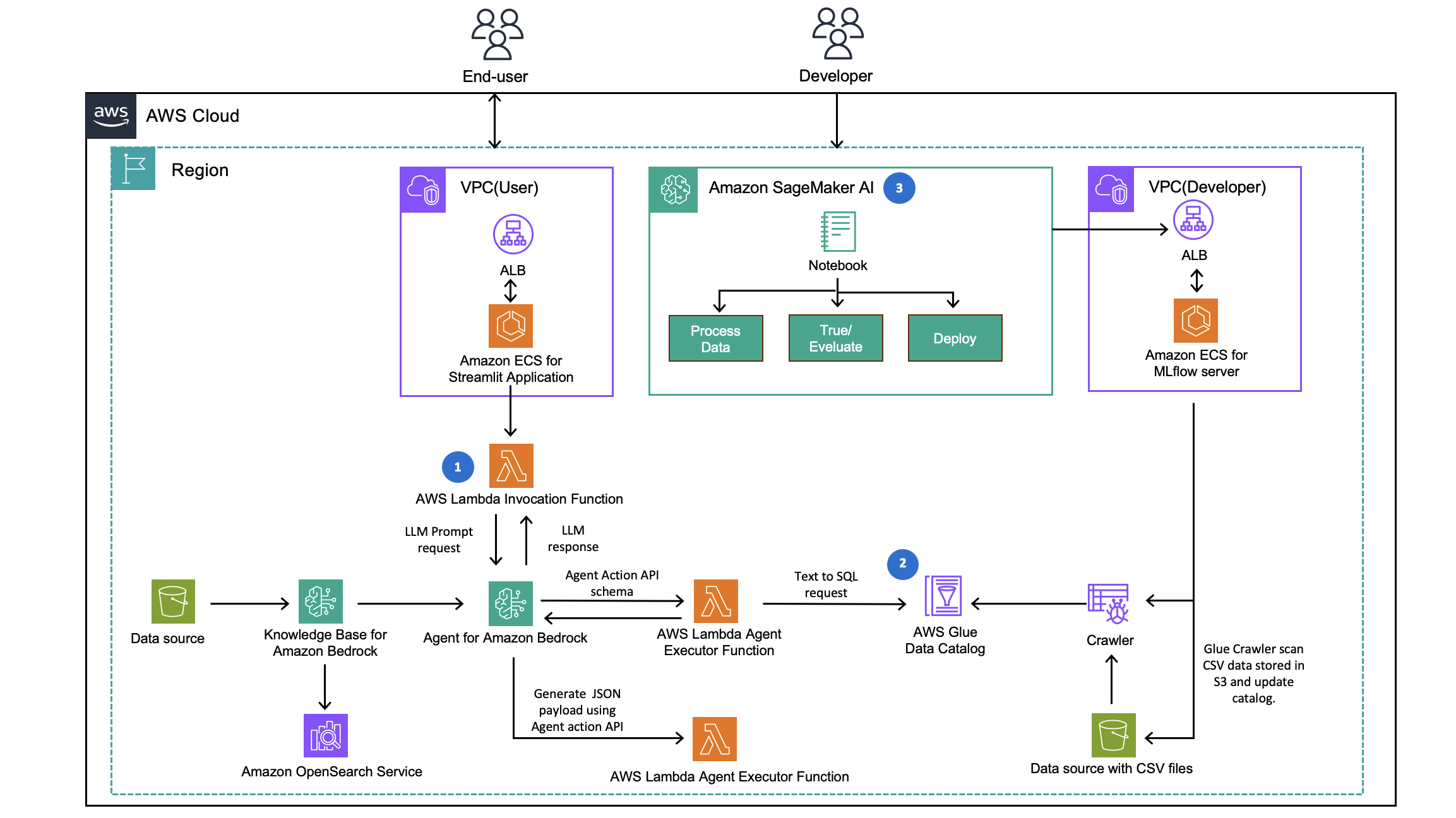
How CLICKFORCE accelerates data-driven advertising with Amazon Bedrock AgentsArtificial Intelligence In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process.
In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process. Read More

Controlling AI agent sprawl: The CIO’s guide to governanceAI News Corporate networks are filling up with AI agents, creating a governance blind spot for leaders managing multi-cloud infrastructures. As distinct business units race to adopt generative technologies, CIOs especially find their ecosystems populated by fragmented and unmonitored assets. This mirrors the shadow IT challenges of the cloud era, but involves autonomous actors capable of executing
The post Controlling AI agent sprawl: The CIO’s guide to governance appeared first on AI News.
Corporate networks are filling up with AI agents, creating a governance blind spot for leaders managing multi-cloud infrastructures. As distinct business units race to adopt generative technologies, CIOs especially find their ecosystems populated by fragmented and unmonitored assets. This mirrors the shadow IT challenges of the cloud era, but involves autonomous actors capable of executing
The post Controlling AI agent sprawl: The CIO’s guide to governance appeared first on AI News. Read More
Towards AI Transparency and Accountability: A Global Framework for Exchanging Information on AI Systemscs.AI updates on arXiv.org arXiv:2307.13658v3 Announce Type: replace-cross
Abstract: We propose that future AI transparency and accountability regulations are based on an open global standard for exchanging information about AI systems, which allows co-existence of potentially conflicting local regulations. Then, we discuss key components of a lightweight and effective AI transparency and/or accountability regulation. To prevent overregulation, the proposed approach encourages collaboration between regulators and industry to create a scalable and cost-efficient mutually beneficial solution. This includes using automated assessments and benchmarks with results transparently communicated through AI cards in an open AI register to facilitate meaningful public comparisons of competing AI systems. Such AI cards should report standardized measures tailored to the specific high-risk applications of AI systems and could be used for conformity assessments under AI transparency and accountability policies such as the European Union’s AI Act.
arXiv:2307.13658v3 Announce Type: replace-cross
Abstract: We propose that future AI transparency and accountability regulations are based on an open global standard for exchanging information about AI systems, which allows co-existence of potentially conflicting local regulations. Then, we discuss key components of a lightweight and effective AI transparency and/or accountability regulation. To prevent overregulation, the proposed approach encourages collaboration between regulators and industry to create a scalable and cost-efficient mutually beneficial solution. This includes using automated assessments and benchmarks with results transparently communicated through AI cards in an open AI register to facilitate meaningful public comparisons of competing AI systems. Such AI cards should report standardized measures tailored to the specific high-risk applications of AI systems and could be used for conformity assessments under AI transparency and accountability policies such as the European Union’s AI Act. Read More