
New Microsoft cloud updates support Indonesia’s long-term AI goalsAI News Indonesia’s push into AI-led growth is gaining momentum as more local organisations look for ways to build their own applications, update their systems, and strengthen data oversight. The country now has broader access to cloud and AI tools after Microsoft expanded the services available in the Indonesia Central cloud region, which first went live six
The post New Microsoft cloud updates support Indonesia’s long-term AI goals appeared first on AI News.
Indonesia’s push into AI-led growth is gaining momentum as more local organisations look for ways to build their own applications, update their systems, and strengthen data oversight. The country now has broader access to cloud and AI tools after Microsoft expanded the services available in the Indonesia Central cloud region, which first went live six
The post New Microsoft cloud updates support Indonesia’s long-term AI goals appeared first on AI News. Read More
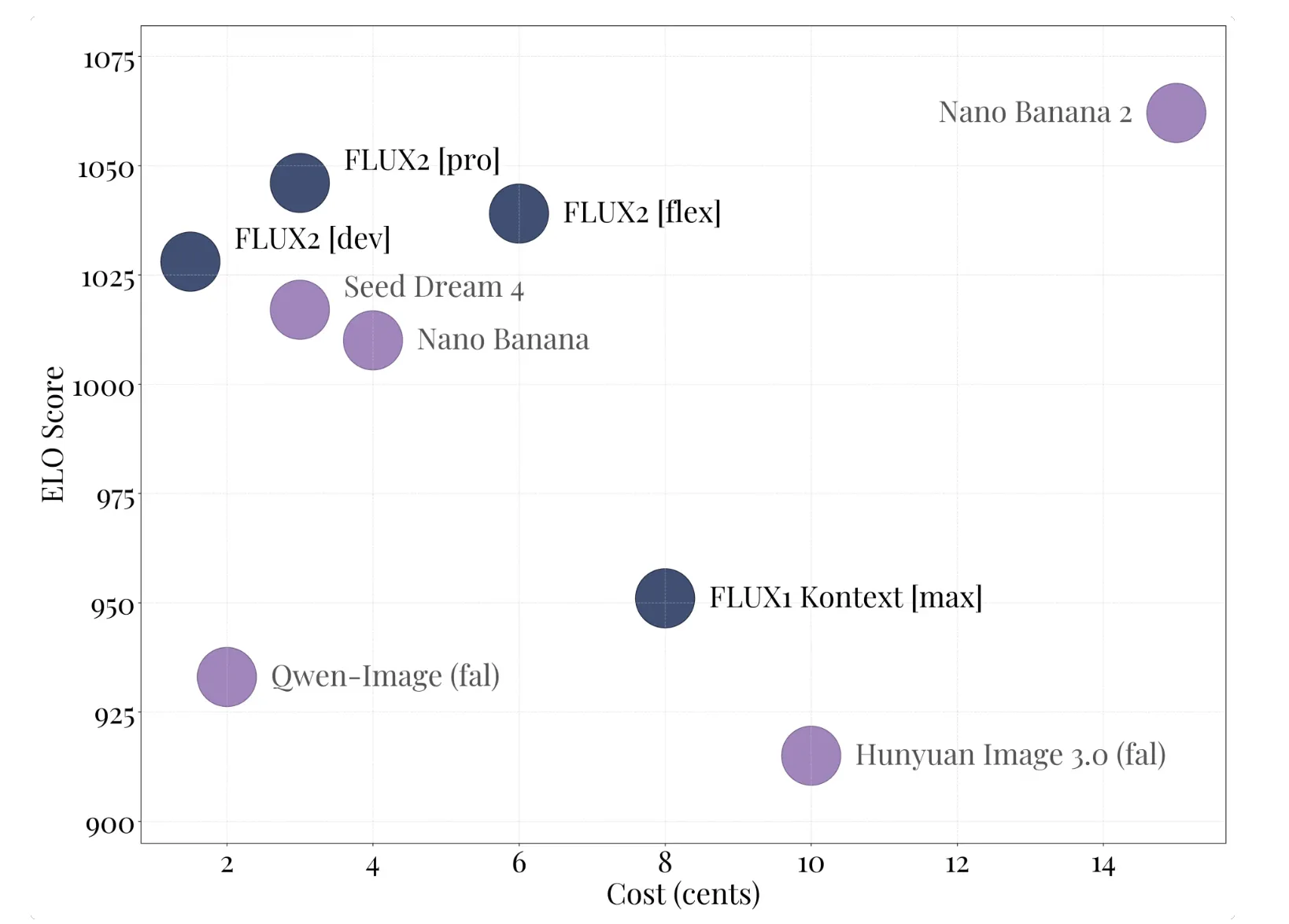
Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image PipelinesMarkTechPost Black Forest Labs has released FLUX.2, its second generation image generation and editing system. FLUX.2 targets real world creative workflows such as marketing assets, product photography, design layouts, and complex infographics, with editing support up to 4 megapixels and strong control over layout, logos, and typography. FLUX.2 product family and FLUX.2 [dev] The FLUX.2 family
The post Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image Pipelines appeared first on MarkTechPost.
Black Forest Labs has released FLUX.2, its second generation image generation and editing system. FLUX.2 targets real world creative workflows such as marketing assets, product photography, design layouts, and complex infographics, with editing support up to 4 megapixels and strong control over layout, logos, and typography. FLUX.2 product family and FLUX.2 [dev] The FLUX.2 family
The post Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image Pipelines appeared first on MarkTechPost. Read More

Estimating LLM Consistency: A User Baseline vs Surrogate Metricscs.AI updates on arXiv.org arXiv:2505.23799v4 Announce Type: replace-cross
Abstract: Large language models (LLMs) are prone to hallucinations and sensitive to prompt perturbations, often resulting in inconsistent or unreliable generated text. Different methods have been proposed to mitigate such hallucinations and fragility, one of which is to measure the consistency of LLM responses — the model’s confidence in the response or likelihood of generating a similar response when resampled. In previous work, measuring LLM response consistency often relied on calculating the probability of a response appearing within a pool of resampled responses, analyzing internal states, or evaluating logits of responses. However, it was not clear how well these approaches approximated users’ perceptions of consistency of LLM responses. To find out, we performed a user study ($n=2,976$) demonstrating that current methods for measuring LLM response consistency typically do not align well with humans’ perceptions of LLM consistency. We propose a logit-based ensemble method for estimating LLM consistency and show that our method matches the performance of the best-performing existing metric in estimating human ratings of LLM consistency. Our results suggest that methods for estimating LLM consistency without human evaluation are sufficiently imperfect to warrant broader use of evaluation with human input; this would avoid misjudging the adequacy of models because of the imperfections of automated consistency metrics.
arXiv:2505.23799v4 Announce Type: replace-cross
Abstract: Large language models (LLMs) are prone to hallucinations and sensitive to prompt perturbations, often resulting in inconsistent or unreliable generated text. Different methods have been proposed to mitigate such hallucinations and fragility, one of which is to measure the consistency of LLM responses — the model’s confidence in the response or likelihood of generating a similar response when resampled. In previous work, measuring LLM response consistency often relied on calculating the probability of a response appearing within a pool of resampled responses, analyzing internal states, or evaluating logits of responses. However, it was not clear how well these approaches approximated users’ perceptions of consistency of LLM responses. To find out, we performed a user study ($n=2,976$) demonstrating that current methods for measuring LLM response consistency typically do not align well with humans’ perceptions of LLM consistency. We propose a logit-based ensemble method for estimating LLM consistency and show that our method matches the performance of the best-performing existing metric in estimating human ratings of LLM consistency. Our results suggest that methods for estimating LLM consistency without human evaluation are sufficiently imperfect to warrant broader use of evaluation with human input; this would avoid misjudging the adequacy of models because of the imperfections of automated consistency metrics. Read More
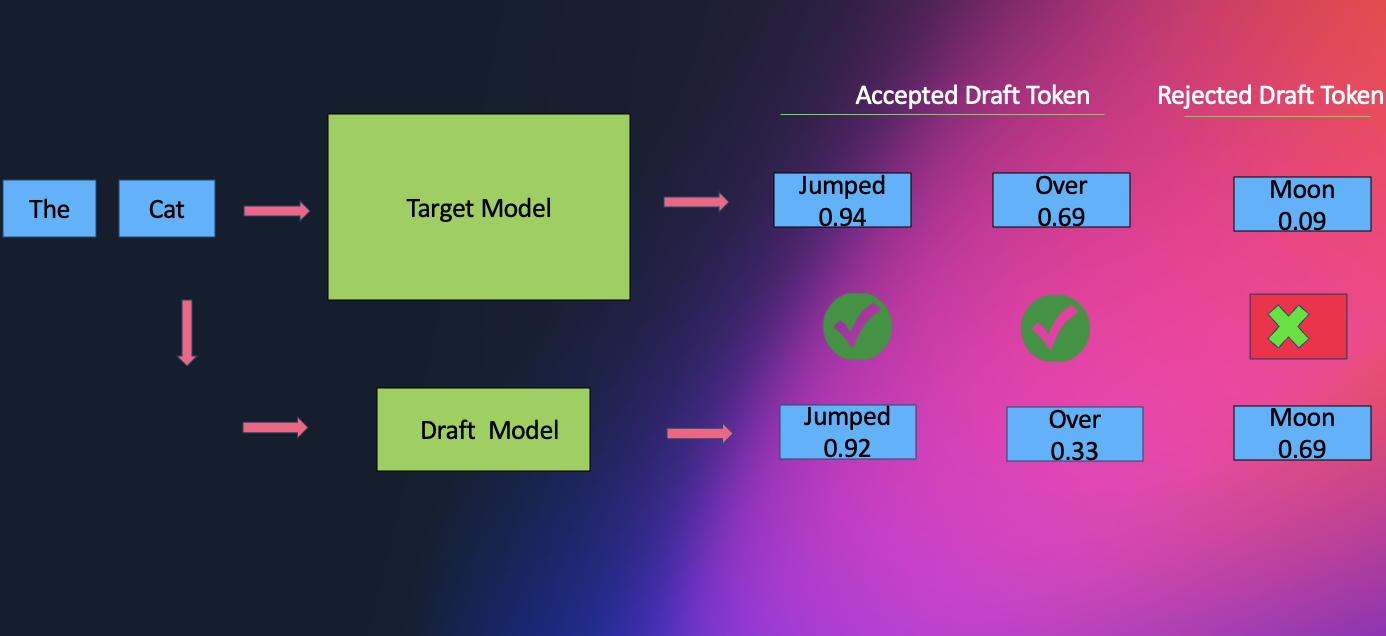
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inferenceArtificial Intelligence Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency.
Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency. Read More

Manufacturing’s pivot: AI as a strategic driverAI News Manufacturers today are working against rising input costs, labour shortages, supply-chain fragility, and pressure to offer more customised products. AI is becoming an important part of a response to those pressures. When enterprise strategy depends on AI Most manufacturers seek to reduce cost while improving throughput and quality. AI supports these aims by predicting equipment
The post Manufacturing’s pivot: AI as a strategic driver appeared first on AI News.
Manufacturers today are working against rising input costs, labour shortages, supply-chain fragility, and pressure to offer more customised products. AI is becoming an important part of a response to those pressures. When enterprise strategy depends on AI Most manufacturers seek to reduce cost while improving throughput and quality. AI supports these aims by predicting equipment
The post Manufacturing’s pivot: AI as a strategic driver appeared first on AI News. Read More

Introducing bidirectional streaming for real-time inference on Amazon SageMaker AIArtificial Intelligence We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference.
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference. Read More
How to Implement Three Use Cases for the New Calendar-Based Time IntelligenceTowards Data Science Starting with the September 2025 Release of Power BI, Microsoft introduced the new Calendar-based Time Intelligence feature. Let’s see what can be done by implementing three use cases. The future looks very interesting with this new feature.
The post How to Implement Three Use Cases for the New Calendar-Based Time Intelligence appeared first on Towards Data Science.
Starting with the September 2025 Release of Power BI, Microsoft introduced the new Calendar-based Time Intelligence feature. Let’s see what can be done by implementing three use cases. The future looks very interesting with this new feature.
The post How to Implement Three Use Cases for the New Calendar-Based Time Intelligence appeared first on Towards Data Science. Read More
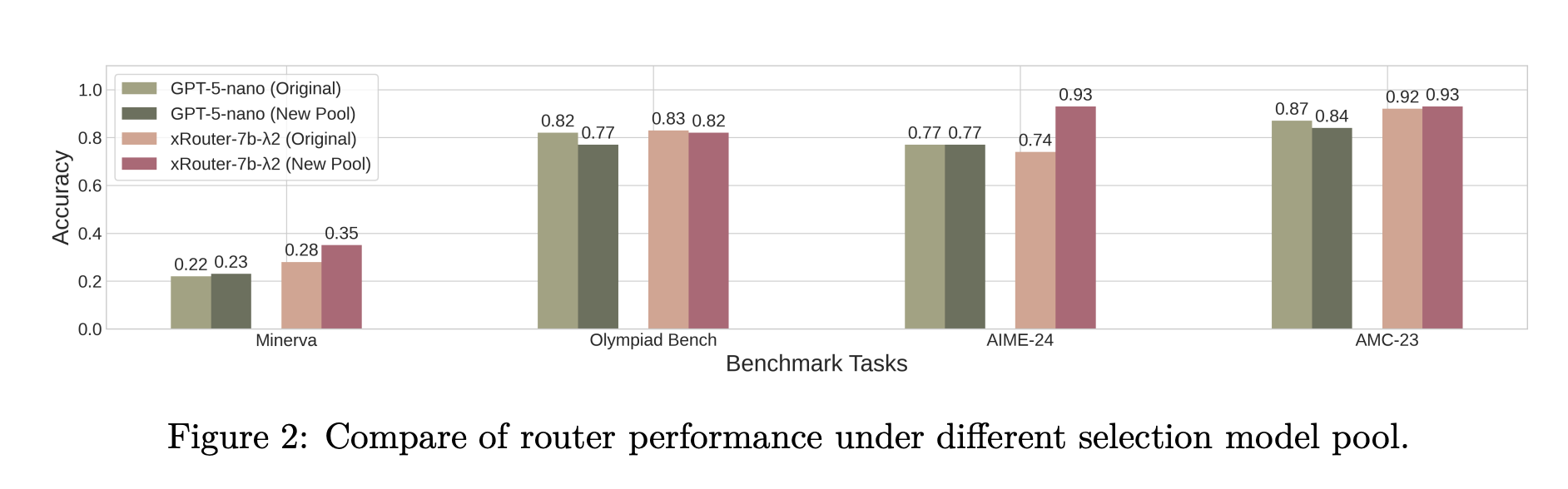
Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM OrchestrationMarkTechPost When your application can call many different LLMs with very different prices and capabilities, who should decide which one answers each request? Salesforce AI research team introduces ‘xRouter’, a tool-calling–based routing system that targets this gap with a reinforcement learning based router and learns when to answer locally and when to call external models, while
The post Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM Orchestration appeared first on MarkTechPost.
When your application can call many different LLMs with very different prices and capabilities, who should decide which one answers each request? Salesforce AI research team introduces ‘xRouter’, a tool-calling–based routing system that targets this gap with a reinforcement learning based router and learns when to answer locally and when to call external models, while
The post Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM Orchestration appeared first on MarkTechPost. Read More
Warner Bros. Discovery achieves 60% cost savings and faster ML inference with AWS GravitonArtificial Intelligence Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models.
Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models. Read More

HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasksArtificial Intelligence In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks. Read More