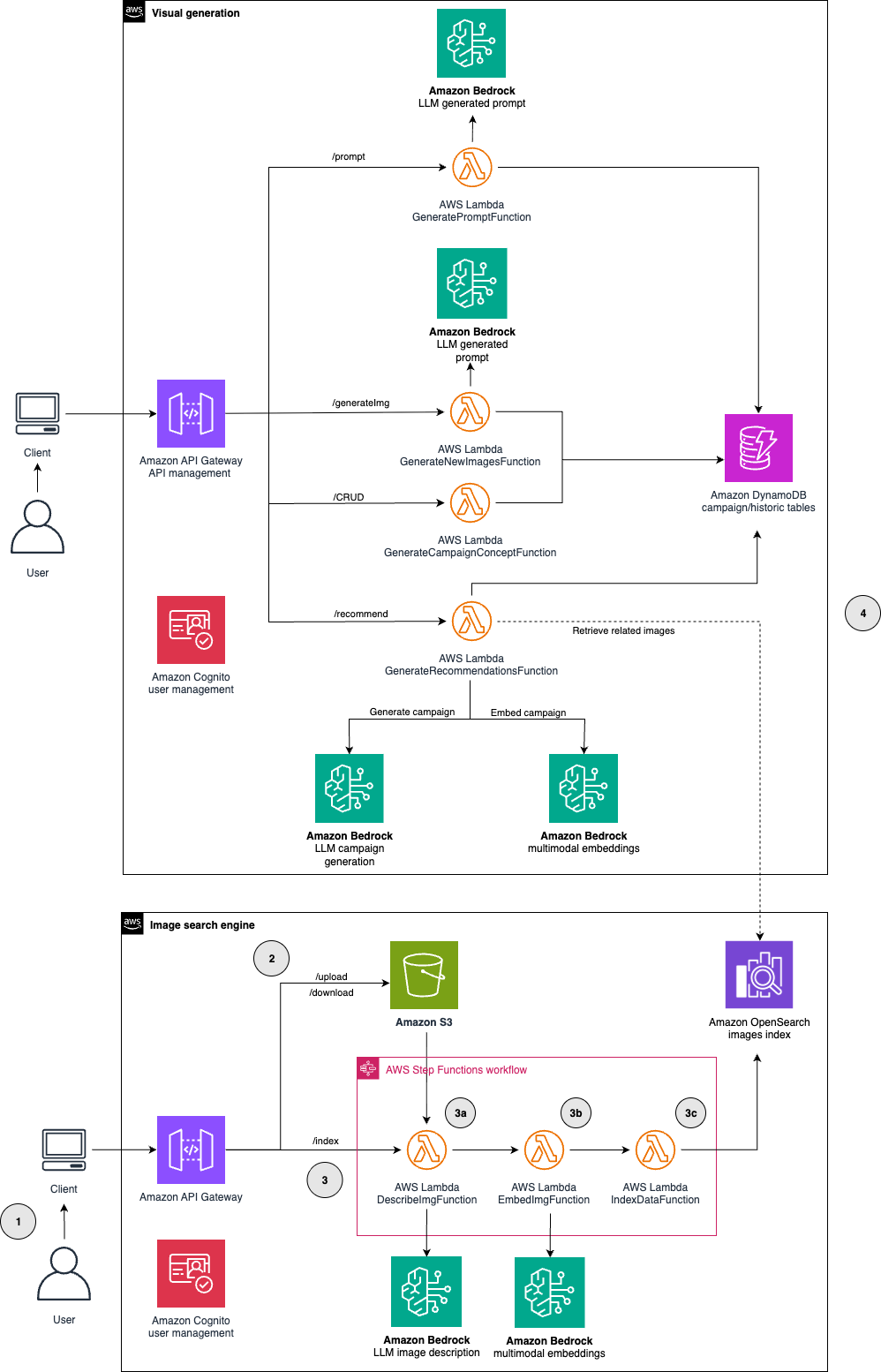
Accelerating your marketing ideation with generative AI – Part 2: Generate custom marketing images from historical referencesArtificial Intelligence Building upon our earlier work of marketing campaign image generation using Amazon Nova foundation models, in this post, we demonstrate how to enhance image generation by learning from previous marketing campaigns. We explore how to integrate Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create an advanced image generation system that uses reference campaigns to maintain brand guidelines, deliver consistent content, and enhance the effectiveness and efficiency of new campaign creation.
Building upon our earlier work of marketing campaign image generation using Amazon Nova foundation models, in this post, we demonstrate how to enhance image generation by learning from previous marketing campaigns. We explore how to integrate Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create an advanced image generation system that uses reference campaigns to maintain brand guidelines, deliver consistent content, and enhance the effectiveness and efficiency of new campaign creation. Read More

How to Work Effectively with Frontend and Backend CodeTowards Data Science Learn how to be an effective full-stack engineer with Claude Code
The post How to Work Effectively with Frontend and Backend Code appeared first on Towards Data Science.
Learn how to be an effective full-stack engineer with Claude Code
The post How to Work Effectively with Frontend and Backend Code appeared first on Towards Data Science. Read More
Rank-and-Reason: Multi-Agent Collaboration Accelerates Zero-Shot Protein Mutation Predictioncs.AI updates on arXiv.org arXiv:2602.00197v2 Announce Type: cross
Abstract: Zero-shot mutation prediction is vital for low-resource protein engineering, yet existing protein language models (PLMs) often yield statistically confident results that ignore fundamental biophysical constraints. Currently, selecting candidates for wet-lab validation relies on manual expert auditing of PLM outputs, a process that is inefficient, subjective, and highly dependent on domain expertise. To address this, we propose Rank-and-Reason (VenusRAR), a two-stage agentic framework to automate this workflow and maximize expected wet-lab fitness. In the Rank-Stage, a Computational Expert and Virtual Biologist aggregate a context-aware multi-modal ensemble, establishing a new Spearman correlation record of 0.551 (vs. 0.518) on ProteinGym. In the Reason-Stage, an agentic Expert Panel employs chain-of-thought reasoning to audit candidates against geometric and structural constraints, improving the Top-5 Hit Rate by up to 367% on ProteinGym-DMS99. The wet-lab validation on Cas12i3 nuclease further confirms the framework’s efficacy, achieving a 46.7% positive rate and identifying two novel mutants with 4.23-fold and 5.05-fold activity improvements. Code and datasets are released on GitHub (https://github.com/ai4protein/VenusRAR/).
arXiv:2602.00197v2 Announce Type: cross
Abstract: Zero-shot mutation prediction is vital for low-resource protein engineering, yet existing protein language models (PLMs) often yield statistically confident results that ignore fundamental biophysical constraints. Currently, selecting candidates for wet-lab validation relies on manual expert auditing of PLM outputs, a process that is inefficient, subjective, and highly dependent on domain expertise. To address this, we propose Rank-and-Reason (VenusRAR), a two-stage agentic framework to automate this workflow and maximize expected wet-lab fitness. In the Rank-Stage, a Computational Expert and Virtual Biologist aggregate a context-aware multi-modal ensemble, establishing a new Spearman correlation record of 0.551 (vs. 0.518) on ProteinGym. In the Reason-Stage, an agentic Expert Panel employs chain-of-thought reasoning to audit candidates against geometric and structural constraints, improving the Top-5 Hit Rate by up to 367% on ProteinGym-DMS99. The wet-lab validation on Cas12i3 nuclease further confirms the framework’s efficacy, achieving a 46.7% positive rate and identifying two novel mutants with 4.23-fold and 5.05-fold activity improvements. Code and datasets are released on GitHub (https://github.com/ai4protein/VenusRAR/). Read More
Navigating health questions with ChatGPTOpenAI News A family shares how ChatGPT helped them prepare for critical cancer treatment decisions for their son alongside expert guidance from his doctors.
A family shares how ChatGPT helped them prepare for critical cancer treatment decisions for their son alongside expert guidance from his doctors. Read More
How to Build Efficient Agentic Reasoning Systems by Dynamically Pruning Multiple Chain-of-Thought Paths Without Losing AccuracyMarkTechPost In this tutorial, we implement an agentic chain-of-thought pruning framework that generates multiple reasoning paths in parallel and dynamically reduces them using consensus signals and early stopping. We focus on improving reasoning efficiency by reducing unnecessary token usage while preserving answer correctness, demonstrating that self-consistency and lightweight graph-based agreement can serve as effective proxies for
The post How to Build Efficient Agentic Reasoning Systems by Dynamically Pruning Multiple Chain-of-Thought Paths Without Losing Accuracy appeared first on MarkTechPost.
In this tutorial, we implement an agentic chain-of-thought pruning framework that generates multiple reasoning paths in parallel and dynamically reduces them using consensus signals and early stopping. We focus on improving reasoning efficiency by reducing unnecessary token usage while preserving answer correctness, demonstrating that self-consistency and lightweight graph-based agreement can serve as effective proxies for
The post How to Build Efficient Agentic Reasoning Systems by Dynamically Pruning Multiple Chain-of-Thought Paths Without Losing Accuracy appeared first on MarkTechPost. Read More

Google Introduces Agentic Vision in Gemini 3 Flash for Active Image UnderstandingMarkTechPost Frontier multimodal models usually process an image in a single pass. If they miss a serial number on a chip or a small symbol on a building plan, they often guess. Google’s new Agentic Vision capability in Gemini 3 Flash changes this by turning image understanding into an active, tool using loop grounded in visual
The post Google Introduces Agentic Vision in Gemini 3 Flash for Active Image Understanding appeared first on MarkTechPost.
Frontier multimodal models usually process an image in a single pass. If they miss a serial number on a chip or a small symbol on a building plan, they often guess. Google’s new Agentic Vision capability in Gemini 3 Flash changes this by turning image understanding into an active, tool using loop grounded in visual
The post Google Introduces Agentic Vision in Gemini 3 Flash for Active Image Understanding appeared first on MarkTechPost. Read More
Unlocking the Codex harness: how we built the App ServerOpenAI News Learn how to embed the Codex agent using the Codex App Server, a bidirectional JSON-RPC API powering streaming progress, tool use, approvals, and diffs.
Learn how to embed the Codex agent using the Codex App Server, a bidirectional JSON-RPC API powering streaming progress, tool use, approvals, and diffs. Read More
Complete Identification of Deep ReLU Neural Networks by Many-Valued Logiccs.AI updates on arXiv.org arXiv:2602.00266v1 Announce Type: new
Abstract: Deep ReLU neural networks admit nontrivial functional symmetries: vastly different architectures and parameters (weights and biases) can realize the same function. We address the complete identification problem — given a function f, deriving the architecture and parameters of all feedforward ReLU networks giving rise to f. We translate ReLU networks into Lukasiewicz logic formulae, and effect functional equivalent network transformations through algebraic rewrites governed by the logic axioms. A compositional norm form is proposed to facilitate the mapping from Lukasiewicz logic formulae back to ReLU networks. Using Chang’s completeness theorem, we show that for every functional equivalence class, all ReLU networks in that class are connected by a finite set of symmetries corresponding to the finite set of axioms of Lukasiewicz logic. This idea is reminiscent of Shannon’s seminal work on switching circuit design, where the circuits are translated into Boolean formulae, and synthesis is effected by algebraic rewriting governed by Boolean logic axioms.
arXiv:2602.00266v1 Announce Type: new
Abstract: Deep ReLU neural networks admit nontrivial functional symmetries: vastly different architectures and parameters (weights and biases) can realize the same function. We address the complete identification problem — given a function f, deriving the architecture and parameters of all feedforward ReLU networks giving rise to f. We translate ReLU networks into Lukasiewicz logic formulae, and effect functional equivalent network transformations through algebraic rewrites governed by the logic axioms. A compositional norm form is proposed to facilitate the mapping from Lukasiewicz logic formulae back to ReLU networks. Using Chang’s completeness theorem, we show that for every functional equivalence class, all ReLU networks in that class are connected by a finite set of symmetries corresponding to the finite set of axioms of Lukasiewicz logic. This idea is reminiscent of Shannon’s seminal work on switching circuit design, where the circuits are translated into Boolean formulae, and synthesis is effected by algebraic rewriting governed by Boolean logic axioms. Read More
FaithSCAN: Model-Driven Single-Pass Hallucination Detection for Faithful Visual Question Answeringcs.AI updates on arXiv.org arXiv:2601.00269v3 Announce Type: replace-cross
Abstract: Faithfulness hallucinations in VQA occur when vision-language models produce fluent yet visually ungrounded answers, severely undermining their reliability in safety-critical applications. Existing detection methods mainly fall into two categories: external verification approaches relying on auxiliary models or knowledge bases, and uncertainty-driven approaches using repeated sampling or uncertainty estimates. The former suffer from high computational overhead and are limited by external resource quality, while the latter capture only limited facets of model uncertainty and fail to sufficiently explore the rich internal signals associated with the diverse failure modes. Both paradigms thus have inherent limitations in efficiency, robustness, and detection performance. To address these challenges, we propose FaithSCAN: a lightweight network that detects hallucinations by exploiting rich internal signals of VLMs, including token-level decoding uncertainty, intermediate visual representations, and cross-modal alignment features. These signals are fused via branch-wise evidence encoding and uncertainty-aware attention. We also extend the LLM-as-a-Judge paradigm to VQA hallucination and propose a low-cost strategy to automatically generate model-dependent supervision signals, enabling supervised training without costly human labels while maintaining high detection accuracy. Experiments on multiple VQA benchmarks show that FaithSCAN significantly outperforms existing methods in both effectiveness and efficiency. In-depth analysis shows hallucinations arise from systematic internal state variations in visual perception, cross-modal reasoning, and language decoding. Different internal signals provide complementary diagnostic cues, and hallucination patterns vary across VLM architectures, offering new insights into the underlying causes of multimodal hallucinations.
arXiv:2601.00269v3 Announce Type: replace-cross
Abstract: Faithfulness hallucinations in VQA occur when vision-language models produce fluent yet visually ungrounded answers, severely undermining their reliability in safety-critical applications. Existing detection methods mainly fall into two categories: external verification approaches relying on auxiliary models or knowledge bases, and uncertainty-driven approaches using repeated sampling or uncertainty estimates. The former suffer from high computational overhead and are limited by external resource quality, while the latter capture only limited facets of model uncertainty and fail to sufficiently explore the rich internal signals associated with the diverse failure modes. Both paradigms thus have inherent limitations in efficiency, robustness, and detection performance. To address these challenges, we propose FaithSCAN: a lightweight network that detects hallucinations by exploiting rich internal signals of VLMs, including token-level decoding uncertainty, intermediate visual representations, and cross-modal alignment features. These signals are fused via branch-wise evidence encoding and uncertainty-aware attention. We also extend the LLM-as-a-Judge paradigm to VQA hallucination and propose a low-cost strategy to automatically generate model-dependent supervision signals, enabling supervised training without costly human labels while maintaining high detection accuracy. Experiments on multiple VQA benchmarks show that FaithSCAN significantly outperforms existing methods in both effectiveness and efficiency. In-depth analysis shows hallucinations arise from systematic internal state variations in visual perception, cross-modal reasoning, and language decoding. Different internal signals provide complementary diagnostic cues, and hallucination patterns vary across VLM architectures, offering new insights into the underlying causes of multimodal hallucinations. Read More
ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Designcs.AI updates on arXiv.org arXiv:2601.21448v2 Announce Type: replace
Abstract: While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs’ performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74% on Verilog generation and 13.33% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.
arXiv:2601.21448v2 Announce Type: replace
Abstract: While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs’ performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74% on Verilog generation and 13.33% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git. Read More