
Faithfulness metric fusion: Improving the evaluation of LLM trustworthiness across domainscs.AI updates on arXiv.org arXiv:2512.05700v1 Announce Type: cross
Abstract: We present a methodology for improving the accuracy of faithfulness evaluation in Large Language Models (LLMs). The proposed methodology is based on the combination of elementary faithfulness metrics into a combined (fused) metric, for the purpose of improving the faithfulness of LLM outputs. The proposed strategy for metric fusion deploys a tree-based model to identify the importance of each metric, which is driven by the integration of human judgements evaluating the faithfulness of LLM responses. This fused metric is demonstrated to correlate more strongly with human judgements across all tested domains for faithfulness. Improving the ability to evaluate the faithfulness of LLMs, allows for greater confidence to be placed within models, allowing for their implementation in a greater diversity of scenarios. Additionally, we homogenise a collection of datasets across question answering and dialogue-based domains and implement human judgements and LLM responses within this dataset, allowing for the reproduction and trialling of faithfulness evaluation across domains.
arXiv:2512.05700v1 Announce Type: cross
Abstract: We present a methodology for improving the accuracy of faithfulness evaluation in Large Language Models (LLMs). The proposed methodology is based on the combination of elementary faithfulness metrics into a combined (fused) metric, for the purpose of improving the faithfulness of LLM outputs. The proposed strategy for metric fusion deploys a tree-based model to identify the importance of each metric, which is driven by the integration of human judgements evaluating the faithfulness of LLM responses. This fused metric is demonstrated to correlate more strongly with human judgements across all tested domains for faithfulness. Improving the ability to evaluate the faithfulness of LLMs, allows for greater confidence to be placed within models, allowing for their implementation in a greater diversity of scenarios. Additionally, we homogenise a collection of datasets across question answering and dialogue-based domains and implement human judgements and LLM responses within this dataset, allowing for the reproduction and trialling of faithfulness evaluation across domains. Read More
Counterfactual Reasoning for Steerable Pluralistic Value Alignment of Large Language Modelscs.AI updates on arXiv.org arXiv:2510.18526v2 Announce Type: replace
Abstract: As large language models (LLMs) become increasingly integrated into applications serving users across diverse cultures, communities and demographics, it is critical to align LLMs with pluralistic human values beyond average principles (e.g., HHH). In psychological and social value theories such as Schwartz’s Value Theory, pluralistic values are represented by multiple value dimensions paired with various priorities. However, existing methods encounter two challenges when aligning with such fine-grained value objectives: 1) they often treat multiple values as independent and equally important, ignoring their interdependence and relative priorities (value complexity); 2) they struggle to precisely control nuanced value priorities, especially those underrepresented ones (value steerability). To handle these challenges, we propose COUPLE, a COUnterfactual reasoning framework for PLuralistic valuE alignment. It introduces a structural causal model (SCM) to feature complex interdependency and prioritization among features, as well as the causal relationship between high-level value dimensions and behaviors. Moreover, it applies counterfactual reasoning to generate outputs aligned with any desired value objectives. Benefitting from explicit causal modeling, COUPLE also provides better interpretability. We evaluate COUPLE on two datasets with different value systems and demonstrate that COUPLE advances other baselines across diverse types of value objectives.
arXiv:2510.18526v2 Announce Type: replace
Abstract: As large language models (LLMs) become increasingly integrated into applications serving users across diverse cultures, communities and demographics, it is critical to align LLMs with pluralistic human values beyond average principles (e.g., HHH). In psychological and social value theories such as Schwartz’s Value Theory, pluralistic values are represented by multiple value dimensions paired with various priorities. However, existing methods encounter two challenges when aligning with such fine-grained value objectives: 1) they often treat multiple values as independent and equally important, ignoring their interdependence and relative priorities (value complexity); 2) they struggle to precisely control nuanced value priorities, especially those underrepresented ones (value steerability). To handle these challenges, we propose COUPLE, a COUnterfactual reasoning framework for PLuralistic valuE alignment. It introduces a structural causal model (SCM) to feature complex interdependency and prioritization among features, as well as the causal relationship between high-level value dimensions and behaviors. Moreover, it applies counterfactual reasoning to generate outputs aligned with any desired value objectives. Benefitting from explicit causal modeling, COUPLE also provides better interpretability. We evaluate COUPLE on two datasets with different value systems and demonstrate that COUPLE advances other baselines across diverse types of value objectives. Read More
Optimizing PyTorch Model Inference on CPUTowards Data Science Flyin’ Like a Lion on Intel Xeon
The post Optimizing PyTorch Model Inference on CPU appeared first on Towards Data Science.
Flyin’ Like a Lion on Intel Xeon
The post Optimizing PyTorch Model Inference on CPU appeared first on Towards Data Science. Read More

Agentic AI smartphones: ByteDance signals opportunity beyond consumer hypeAI News ByteDance’s December 2 launch of an agentic AI smartphone prototype with ZTE sparked immediate consumer enthusiasm – and just as quickly triggered privacy concerns that forced the company to dial back capabilities. But beneath the headline-grabbing sell-out and subsequent controversy lies a more significant story: the enterprise implications of operating-system-level AI agents that can autonomously
The post Agentic AI smartphones: ByteDance signals opportunity beyond consumer hype appeared first on AI News.
ByteDance’s December 2 launch of an agentic AI smartphone prototype with ZTE sparked immediate consumer enthusiasm – and just as quickly triggered privacy concerns that forced the company to dial back capabilities. But beneath the headline-grabbing sell-out and subsequent controversy lies a more significant story: the enterprise implications of operating-system-level AI agents that can autonomously
The post Agentic AI smartphones: ByteDance signals opportunity beyond consumer hype appeared first on AI News. Read More
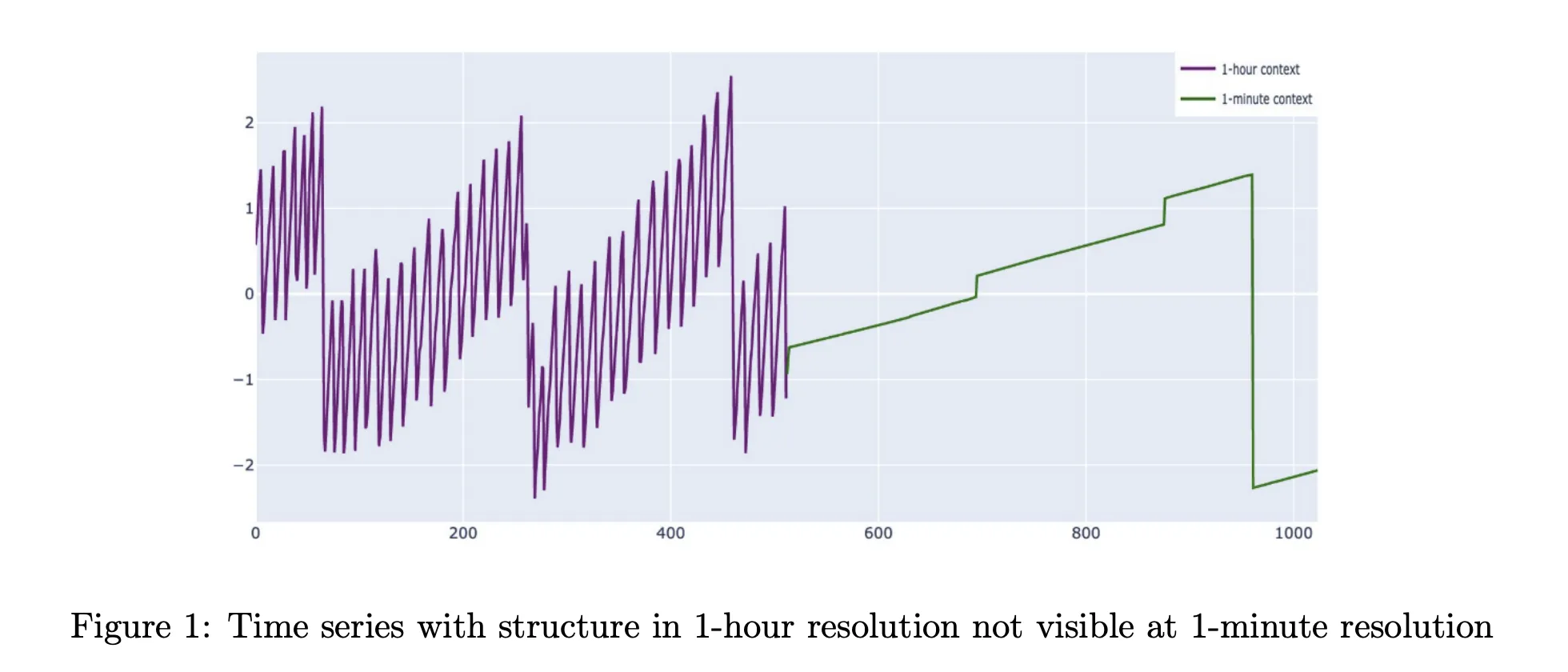
Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer ArchitectureMarkTechPost Cisco and Splunk have introduced the Cisco Time Series Model, a univariate zero shot time series foundation model designed for observability and security metrics. It is released as an open weight checkpoint on Hugging Face under an Apache 2.0 license, and it targets forecasting workloads without task specific fine tuning. The model extends TimesFM 2.0
The post Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer Architecture appeared first on MarkTechPost.
Cisco and Splunk have introduced the Cisco Time Series Model, a univariate zero shot time series foundation model designed for observability and security metrics. It is released as an open weight checkpoint on Hugging Face under an Apache 2.0 license, and it targets forecasting workloads without task specific fine tuning. The model extends TimesFM 2.0
The post Cisco Released Cisco Time Series Model: Their First Open-Weights Foundation Model based on Decoder-only Transformer Architecture appeared first on MarkTechPost. Read More
Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and CompetitionsMarkTechPost Google is closing an old gap between Kaggle and Colab. Colab now has a built in Data Explorer that lets you search Kaggle datasets, models and competitions directly inside a notebook, then pull them in through KaggleHub without leaving the editor. What Colab Data Explorer actually ships? Kaggle announced the feature recently where they describe
The post Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and Competitions appeared first on MarkTechPost.
Google is closing an old gap between Kaggle and Colab. Colab now has a built in Data Explorer that lets you search Kaggle datasets, models and competitions directly inside a notebook, then pull them in through KaggleHub without leaving the editor. What Colab Data Explorer actually ships? Kaggle announced the feature recently where they describe
The post Google Colab Integrates KaggleHub for One Click Access to Kaggle Datasets, Models and Competitions appeared first on MarkTechPost. Read More
A Coding Implementation of a Complete Hierarchical Bayesian Regression Workflow in NumPyro Using JAX-Powered Inference and Posterior Predictive AnalysisMarkTechPost In this tutorial, we explore hierarchical Bayesian regression with NumPyro and walk through the entire workflow in a structured manner. We start by generating synthetic data, then we define a probabilistic model that captures both global patterns and group-level variations. Through each snippet, we set up inference using NUTS, analyze posterior distributions, and perform posterior
The post A Coding Implementation of a Complete Hierarchical Bayesian Regression Workflow in NumPyro Using JAX-Powered Inference and Posterior Predictive Analysis appeared first on MarkTechPost.
In this tutorial, we explore hierarchical Bayesian regression with NumPyro and walk through the entire workflow in a structured manner. We start by generating synthetic data, then we define a probabilistic model that captures both global patterns and group-level variations. Through each snippet, we set up inference using NUTS, analyze posterior distributions, and perform posterior
The post A Coding Implementation of a Complete Hierarchical Bayesian Regression Workflow in NumPyro Using JAX-Powered Inference and Posterior Predictive Analysis appeared first on MarkTechPost. Read More
How to Climb the Hidden Career Ladder of Data ScienceTowards Data Science The behaviors that get you promoted
The post How to Climb the Hidden Career Ladder of Data Science appeared first on Towards Data Science.
The behaviors that get you promoted
The post How to Climb the Hidden Career Ladder of Data Science appeared first on Towards Data Science. Read More
How to Build an Adaptive Meta-Reasoning Agent That Dynamically Chooses Between Fast, Deep, and Tool-Based Thinking StrategiesMarkTechPost We begin this tutorial by building a meta-reasoning agent that decides how to think before it thinks. Instead of applying the same reasoning process for every query, we design a system that evaluates complexity, chooses between fast heuristics, deep chain-of-thought reasoning, or tool-based computation, and then adapts its behaviour in real time. By examining each
The post How to Build an Adaptive Meta-Reasoning Agent That Dynamically Chooses Between Fast, Deep, and Tool-Based Thinking Strategies appeared first on MarkTechPost.
We begin this tutorial by building a meta-reasoning agent that decides how to think before it thinks. Instead of applying the same reasoning process for every query, we design a system that evaluates complexity, chooses between fast heuristics, deep chain-of-thought reasoning, or tool-based computation, and then adapts its behaviour in real time. By examining each
The post How to Build an Adaptive Meta-Reasoning Agent That Dynamically Chooses Between Fast, Deep, and Tool-Based Thinking Strategies appeared first on MarkTechPost. Read More
The Machine Learning “Advent Calendar” Day 7: Decision Tree ClassifierTowards Data Science In Day 6, we saw how a Decision Tree Regressor finds its optimal split by minimizing the Mean Squared Error.
Today, for Day 7 of the Machine Learning “Advent Calendar”, we switch to classification. With just one numerical feature and two classes, we explore how a Decision Tree Classifier decides where to cut the data, using impurity measures like Gini and Entropy.
Even without doing the math, we can visually guess possible split points. But which one is best? And do impurity measures really make a difference? Let us build the first split step by step in Excel and see what happens.
The post The Machine Learning “Advent Calendar” Day 7: Decision Tree Classifier appeared first on Towards Data Science.
In Day 6, we saw how a Decision Tree Regressor finds its optimal split by minimizing the Mean Squared Error.
Today, for Day 7 of the Machine Learning “Advent Calendar”, we switch to classification. With just one numerical feature and two classes, we explore how a Decision Tree Classifier decides where to cut the data, using impurity measures like Gini and Entropy.
Even without doing the math, we can visually guess possible split points. But which one is best? And do impurity measures really make a difference? Let us build the first split step by step in Excel and see what happens.
The post The Machine Learning “Advent Calendar” Day 7: Decision Tree Classifier appeared first on Towards Data Science. Read More