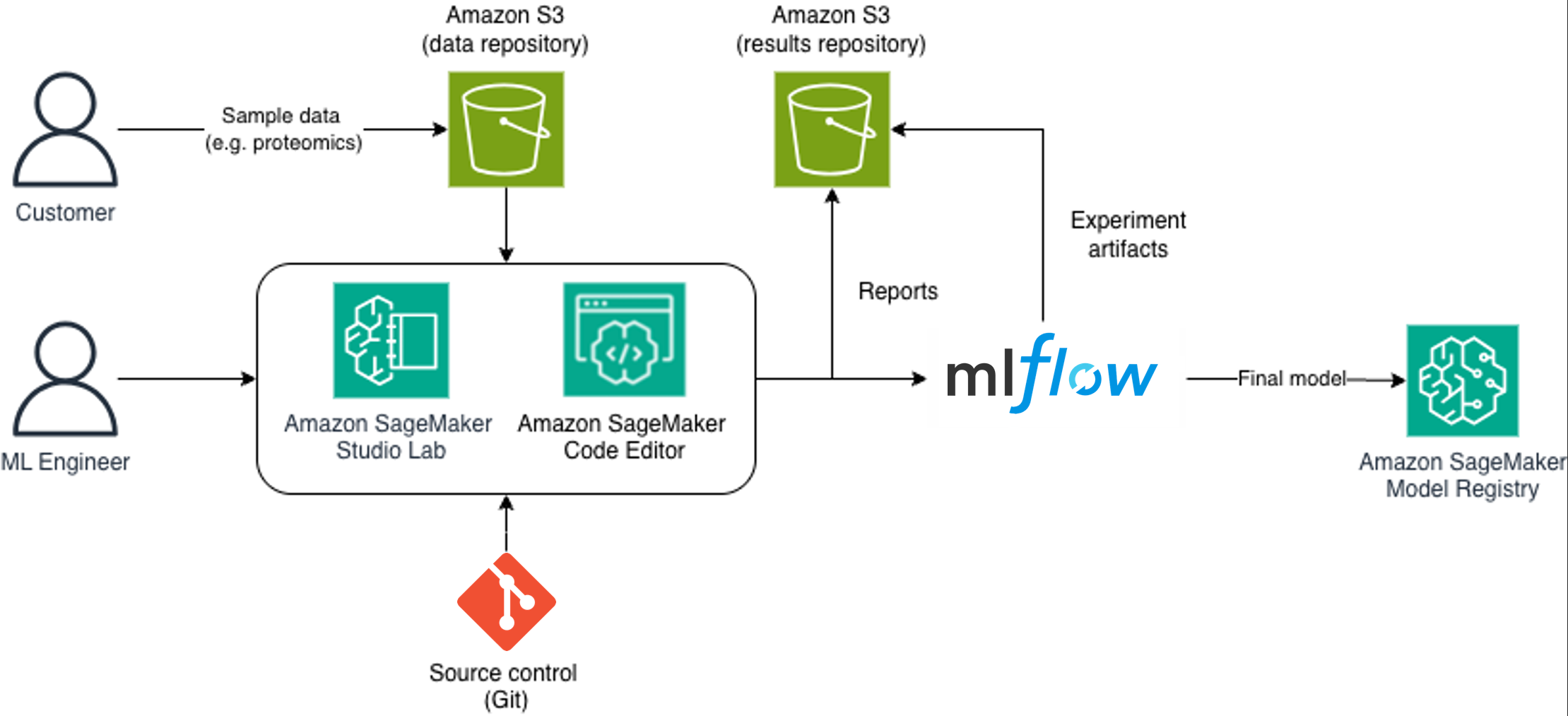
How Sonrai uses Amazon SageMaker AI to accelerate precision medicine trialsArtificial Intelligence In this post, we explore how Sonrai, a life sciences AI company, partnered with AWS to build a robust MLOps framework using Amazon SageMaker AI that addresses these challenges while maintaining the traceability and reproducibility required in regulated environments.
In this post, we explore how Sonrai, a life sciences AI company, partnered with AWS to build a robust MLOps framework using Amazon SageMaker AI that addresses these challenges while maintaining the traceability and reproducibility required in regulated environments. Read More

Build Effective Internal Tooling with Claude CodeTowards Data Science Use Claude Code to quickly build completely personalized applications
The post Build Effective Internal Tooling with Claude Code appeared first on Towards Data Science.
Use Claude Code to quickly build completely personalized applications
The post Build Effective Internal Tooling with Claude Code appeared first on Towards Data Science. Read More

How Amul is using AI dairy farming to put 36 million farmers firstAI News AI dairy farming has found its most ambitious deployment yet – not in a Silicon Valley lab nor a European agri-tech campus, but in the villages of Gujarat, India, where 36 lakh (3.6 million) women milk producers are now being served by an AI assistant named Sarlaben. Amul, the world’s largest dairy cooperative, has launched
The post How Amul is using AI dairy farming to put 36 million farmers first appeared first on AI News.
AI dairy farming has found its most ambitious deployment yet – not in a Silicon Valley lab nor a European agri-tech campus, but in the villages of Gujarat, India, where 36 lakh (3.6 million) women milk producers are now being served by an AI assistant named Sarlaben. Amul, the world’s largest dairy cooperative, has launched
The post How Amul is using AI dairy farming to put 36 million farmers first appeared first on AI News. Read More
OpenAI announces Frontier Alliance PartnersOpenAI News OpenAI announces Frontier Alliance Partners to help enterprises move from AI pilots to production with secure, scalable agent deployments.
OpenAI announces Frontier Alliance Partners to help enterprises move from AI pilots to production with secure, scalable agent deployments. Read More
Learning Optimal and Sample-Efficient Decision Policies with Guaranteescs.AI updates on arXiv.org arXiv:2602.17978v1 Announce Type: cross
Abstract: The paradigm of decision-making has been revolutionised by reinforcement learning and deep learning. Although this has led to significant progress in domains such as robotics, healthcare, and finance, the use of RL in practice is challenging, particularly when learning decision policies in high-stakes applications that may require guarantees. Traditional RL algorithms rely on a large number of online interactions with the environment, which is problematic in scenarios where online interactions are costly, dangerous, or infeasible. However, learning from offline datasets is hindered by the presence of hidden confounders. Such confounders can cause spurious correlations in the dataset and can mislead the agent into taking suboptimal or adversarial actions. Firstly, we address the problem of learning from offline datasets in the presence of hidden confounders. We work with instrumental variables (IVs) to identify the causal effect, which is an instance of a conditional moment restrictions (CMR) problem. Inspired by double/debiased machine learning, we derive a sample-efficient algorithm for solving CMR problems with convergence and optimality guarantees, which outperforms state-of-the-art algorithms. Secondly, we relax the conditions on the hidden confounders in the setting of (offline) imitation learning, and adapt our CMR estimator to derive an algorithm that can learn effective imitator policies with convergence rate guarantees. Finally, we consider the problem of learning high-level objectives expressed in linear temporal logic (LTL) and develop a provably optimal learning algorithm that improves sample efficiency over existing methods. Through evaluation on reinforcement learning benchmarks and synthetic and semi-synthetic datasets, we demonstrate the usefulness of the methods developed in this thesis in real-world decision making.
arXiv:2602.17978v1 Announce Type: cross
Abstract: The paradigm of decision-making has been revolutionised by reinforcement learning and deep learning. Although this has led to significant progress in domains such as robotics, healthcare, and finance, the use of RL in practice is challenging, particularly when learning decision policies in high-stakes applications that may require guarantees. Traditional RL algorithms rely on a large number of online interactions with the environment, which is problematic in scenarios where online interactions are costly, dangerous, or infeasible. However, learning from offline datasets is hindered by the presence of hidden confounders. Such confounders can cause spurious correlations in the dataset and can mislead the agent into taking suboptimal or adversarial actions. Firstly, we address the problem of learning from offline datasets in the presence of hidden confounders. We work with instrumental variables (IVs) to identify the causal effect, which is an instance of a conditional moment restrictions (CMR) problem. Inspired by double/debiased machine learning, we derive a sample-efficient algorithm for solving CMR problems with convergence and optimality guarantees, which outperforms state-of-the-art algorithms. Secondly, we relax the conditions on the hidden confounders in the setting of (offline) imitation learning, and adapt our CMR estimator to derive an algorithm that can learn effective imitator policies with convergence rate guarantees. Finally, we consider the problem of learning high-level objectives expressed in linear temporal logic (LTL) and develop a provably optimal learning algorithm that improves sample efficiency over existing methods. Through evaluation on reinforcement learning benchmarks and synthetic and semi-synthetic datasets, we demonstrate the usefulness of the methods developed in this thesis in real-world decision making. Read More
On the Adversarial Robustness of Discrete Image Tokenizerscs.AI updates on arXiv.org arXiv:2602.18252v1 Announce Type: cross
Abstract: Discrete image tokenizers encode visual inputs as sequences of tokens from a finite vocabulary and are gaining popularity in multimodal systems, including encoder-only, encoder-decoder, and decoder-only models. However, unlike CLIP encoders, their vulnerability to adversarial attacks has not been explored. Ours being the first work studying this topic, we first formulate attacks that aim to perturb the features extracted by discrete tokenizers, and thus change the extracted tokens. These attacks are computationally efficient, application-agnostic, and effective across classification, multimodal retrieval, and captioning tasks. Second, to defend against this vulnerability, inspired by recent work on robust CLIP encoders, we fine-tune popular tokenizers with unsupervised adversarial training, keeping all other components frozen. While unsupervised and task-agnostic, our approach significantly improves robustness to both unsupervised and end-to-end supervised attacks and generalizes well to unseen tasks and data. Unlike supervised adversarial training, our approach can leverage unlabeled images, making it more versatile. Overall, our work highlights the critical role of tokenizer robustness in downstream tasks and presents an important step in the development of safe multimodal foundation models.
arXiv:2602.18252v1 Announce Type: cross
Abstract: Discrete image tokenizers encode visual inputs as sequences of tokens from a finite vocabulary and are gaining popularity in multimodal systems, including encoder-only, encoder-decoder, and decoder-only models. However, unlike CLIP encoders, their vulnerability to adversarial attacks has not been explored. Ours being the first work studying this topic, we first formulate attacks that aim to perturb the features extracted by discrete tokenizers, and thus change the extracted tokens. These attacks are computationally efficient, application-agnostic, and effective across classification, multimodal retrieval, and captioning tasks. Second, to defend against this vulnerability, inspired by recent work on robust CLIP encoders, we fine-tune popular tokenizers with unsupervised adversarial training, keeping all other components frozen. While unsupervised and task-agnostic, our approach significantly improves robustness to both unsupervised and end-to-end supervised attacks and generalizes well to unseen tasks and data. Unlike supervised adversarial training, our approach can leverage unlabeled images, making it more versatile. Overall, our work highlights the critical role of tokenizer robustness in downstream tasks and presents an important step in the development of safe multimodal foundation models. Read More

The MCP Revolution and the Search for Stable AI Use CasesKDnuggets A conversation with AI researcher Sebastian Wallkötter reveals insights on standardization, security challenges, and the fundamental question facing enterprise artificial intelligence adoption.
A conversation with AI researcher Sebastian Wallkötter reveals insights on standardization, security challenges, and the fundamental question facing enterprise artificial intelligence adoption. Read More
Mastercard’s AI payment demo points to agent-led commerceAI News A recent demonstration from Mastercard suggests that payment systems may be heading toward a future where software agents, not people, complete purchases. During the India AI Impact Summit 2026, Mastercard showed what it described as its first fully authenticated “agentic commerce” transaction. In the demo, as reported by Times of India, an AI agent searched
The post Mastercard’s AI payment demo points to agent-led commerce appeared first on AI News.
A recent demonstration from Mastercard suggests that payment systems may be heading toward a future where software agents, not people, complete purchases. During the India AI Impact Summit 2026, Mastercard showed what it described as its first fully authenticated “agentic commerce” transaction. In the demo, as reported by Times of India, an AI agent searched
The post Mastercard’s AI payment demo points to agent-led commerce appeared first on AI News. Read More
WorkflowPerturb: Calibrated Stress Tests for Evaluating Multi-Agent Workflow Metricscs.AI updates on arXiv.org arXiv:2602.17990v1 Announce Type: new
Abstract: LLM-based systems increasingly generate structured workflows for complex tasks. In practice, automatic evaluation of these workflows is difficult, because metric scores are often not calibrated, and score changes do not directly communicate the severity of workflow degradation. We introduce WorkflowPerturb, a controlled benchmark for studying workflow evaluation metrics. It works by applying realistic, controlled perturbations to golden workflows. WorkflowPerturb contains 4,973 golden workflows and 44,757 perturbed variants across three perturbation types (Missing Steps, Compressed Steps, and Description Changes), each applied at severity levels of 10%, 30%, and 50%. We benchmark multiple metric families and analyze their sensitivity and calibration using expected score trajectories and residuals. Our results characterize systematic differences across metric families and support severity-aware interpretation of workflow evaluation scores. Our dataset will be released upon acceptance.
arXiv:2602.17990v1 Announce Type: new
Abstract: LLM-based systems increasingly generate structured workflows for complex tasks. In practice, automatic evaluation of these workflows is difficult, because metric scores are often not calibrated, and score changes do not directly communicate the severity of workflow degradation. We introduce WorkflowPerturb, a controlled benchmark for studying workflow evaluation metrics. It works by applying realistic, controlled perturbations to golden workflows. WorkflowPerturb contains 4,973 golden workflows and 44,757 perturbed variants across three perturbation types (Missing Steps, Compressed Steps, and Description Changes), each applied at severity levels of 10%, 30%, and 50%. We benchmark multiple metric families and analyze their sensitivity and calibration using expected score trajectories and residuals. Our results characterize systematic differences across metric families and support severity-aware interpretation of workflow evaluation scores. Our dataset will be released upon acceptance. Read More
Through the Judge’s Eyes: Inferred Thinking Traces Improve Reliability of LLM Raterscs.AI updates on arXiv.org arXiv:2510.25860v2 Announce Type: replace
Abstract: Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
arXiv:2510.25860v2 Announce Type: replace
Abstract: Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters. Read More