
The Geometry of Laziness: What Angles Reveal About AI HallucinationsTowards Data Science A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science.
A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science. Read More
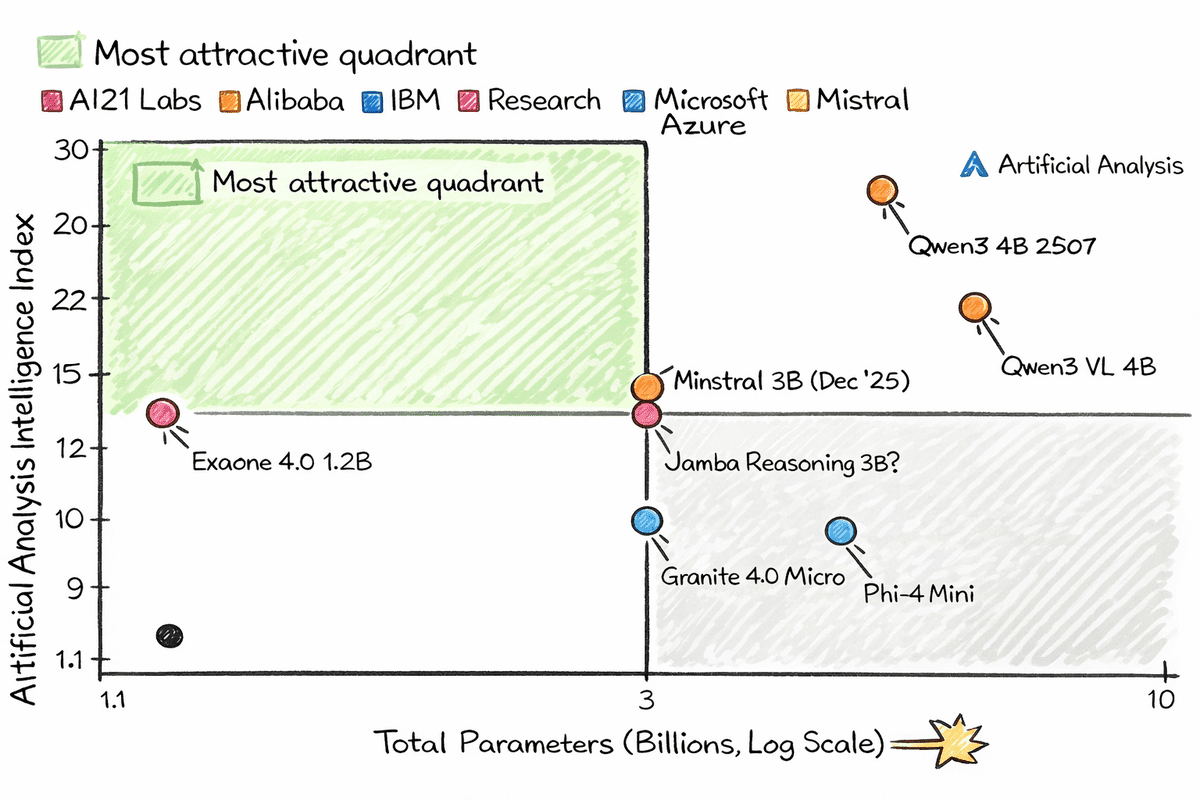
7 Tiny AI Models for Raspberry PiKDnuggets This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge.
This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge. Read More
The Machine Learning “Advent Calendar” Day 22: Embeddings in ExcelTowards Data Science Understanding text embeddings through simple models and Excel
The post The Machine Learning “Advent Calendar” Day 22: Embeddings in Excel appeared first on Towards Data Science.
Understanding text embeddings through simple models and Excel
The post The Machine Learning “Advent Calendar” Day 22: Embeddings in Excel appeared first on Towards Data Science. Read More
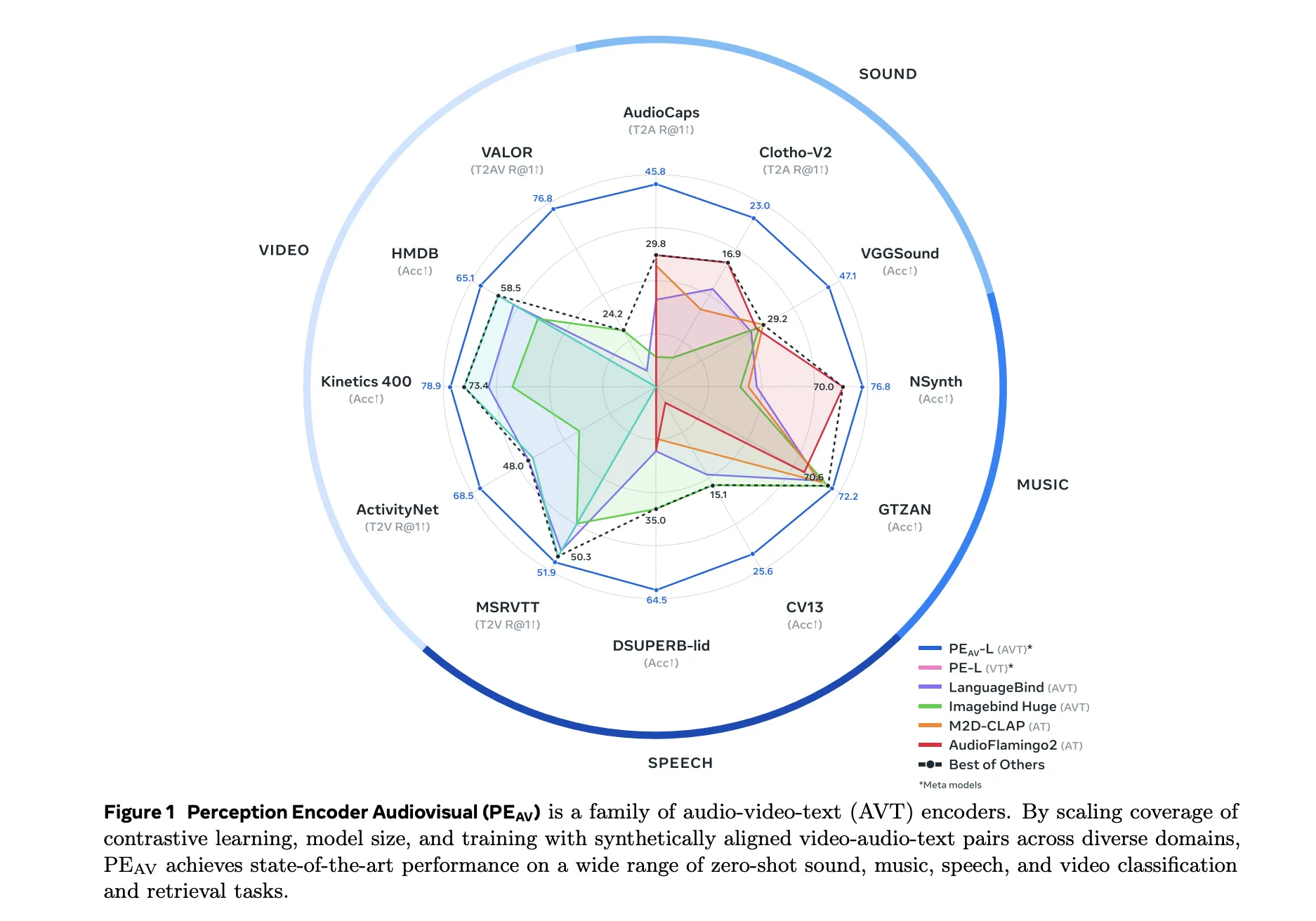
Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal RetrievalMarkTechPost Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions. From Perception Encoder to PEAV Perception Encoder,
The post Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval appeared first on MarkTechPost.
Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions. From Perception Encoder to PEAV Perception Encoder,
The post Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval appeared first on MarkTechPost. Read More
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI Towards Data Science
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AITowards Data Science For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science.
For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science. Read More
Move Beyond Chain-of-Thought with Chain-of-Draft on Amazon BedrockArtificial Intelligence This post explores Chain-of-Draft (CoD), an innovative prompting technique introduced in a Zoom AI Research paper Chain of Draft: Thinking Faster by Writing Less, that revolutionizes how models approach reasoning tasks. While Chain-of-Thought (CoT) prompting has been the go-to method for enhancing model reasoning, CoD offers a more efficient alternative that mirrors human problem-solving patterns—using concise, high-signal thinking steps rather than verbose explanations.
This post explores Chain-of-Draft (CoD), an innovative prompting technique introduced in a Zoom AI Research paper Chain of Draft: Thinking Faster by Writing Less, that revolutionizes how models approach reasoning tasks. While Chain-of-Thought (CoT) prompting has been the go-to method for enhancing model reasoning, CoD offers a more efficient alternative that mirrors human problem-solving patterns—using concise, high-signal thinking steps rather than verbose explanations. Read More
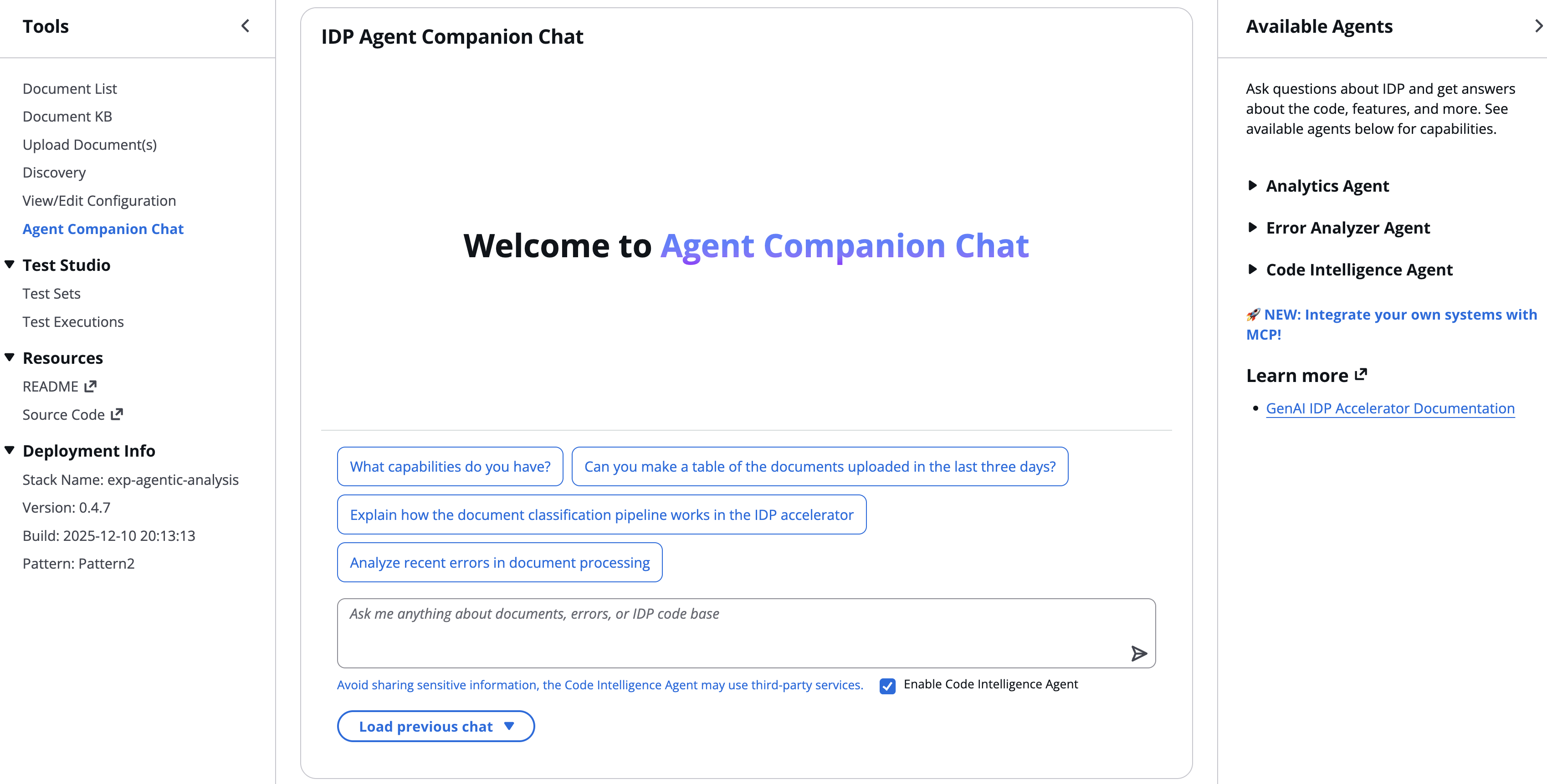
Enhance document analytics with Strands AI Agents for the GenAI IDP AcceleratorArtificial Intelligence To address the need for businesses to quickly analyze information and unlock actionable insights, we are announcing Analytics Agent, a new feature that is seamlessly integrated into the GenAI IDP Accelerator. With this feature, users can perform advanced searches and complex analyses using natural language queries without SQL or data analysis expertise. In this post, we discuss how non-technical users can use this tool to analyze and understand the documents they have processed at scale with natural language.
To address the need for businesses to quickly analyze information and unlock actionable insights, we are announcing Analytics Agent, a new feature that is seamlessly integrated into the GenAI IDP Accelerator. With this feature, users can perform advanced searches and complex analyses using natural language queries without SQL or data analysis expertise. In this post, we discuss how non-technical users can use this tool to analyze and understand the documents they have processed at scale with natural language. Read More

Build a multimodal generative AI assistant for root cause diagnosis in predictive maintenance using Amazon BedrockArtificial Intelligence In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare.
In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare. Read More
A new tool is revealing the invisible networks inside cancerArtificial Intelligence News — ScienceDaily Spanish researchers have created a powerful new open-source tool that helps uncover the hidden genetic networks driving cancer. Called RNACOREX, the software can analyze thousands of molecular interactions at once, revealing how genes communicate inside tumors and how those signals relate to patient survival. Tested across 13 different cancer types using international data, the tool matches the predictive power of advanced AI systems—while offering something rare in modern analytics: clear, interpretable explanations that help scientists understand why tumors behave the way they do.
Spanish researchers have created a powerful new open-source tool that helps uncover the hidden genetic networks driving cancer. Called RNACOREX, the software can analyze thousands of molecular interactions at once, revealing how genes communicate inside tumors and how those signals relate to patient survival. Tested across 13 different cancer types using international data, the tool matches the predictive power of advanced AI systems—while offering something rare in modern analytics: clear, interpretable explanations that help scientists understand why tumors behave the way they do. Read More
How to Do Evals on a Bloated RAG PipelineTowards Data Science Comparing metrics across datasets and models
The post How to Do Evals on a Bloated RAG Pipeline appeared first on Towards Data Science.
Comparing metrics across datasets and models
The post How to Do Evals on a Bloated RAG Pipeline appeared first on Towards Data Science. Read More