
Author: Derrick D. Jackson
Title: Founder & Senior Director of Cloud Security Architecture & Risk
Credentials: CISSP, CRISC, CCSP
Last updated October 24th, 2025
Table of Contents
Hello Everyone, Help us grow our community by sharing and/or supporting us on other platforms. This allow us to show verification that what we are doing is valued. It also allows us to plan and allocate resources to improve what we are doing, as we then know others are interested/supportive.
When ChatGPT launched in November 2022, it reached 100 million monthly active users in just two months, according to data from Similarweb and a UBS study. That’s faster than any consumer technology in history. A UBS analyst noted, “in 20 years following the internet space, we cannot recall a faster ramp in a consumer internet app.” For context, Instagram took two and a half years to reach 100 million users. TikTok took nine months.

Traditional software follows instructions. You tell it what to do, and it “does” exactly that. Generative AI is different. It learns patterns from massive amounts of data, then creates new content that’s statistically similar but not identical to what it learned from. That distinction changes everything.
Understanding generative AI isn’t just for technologists. It’s reshaping how we work, create, and solve problems. Whether you’re a business leader evaluating AI investments, a student exploring career options, or simply curious about the technology behind ChatGPT, Claude and Gemini, this guide will help you understand what generative AI really is.

What Is Generative AI?
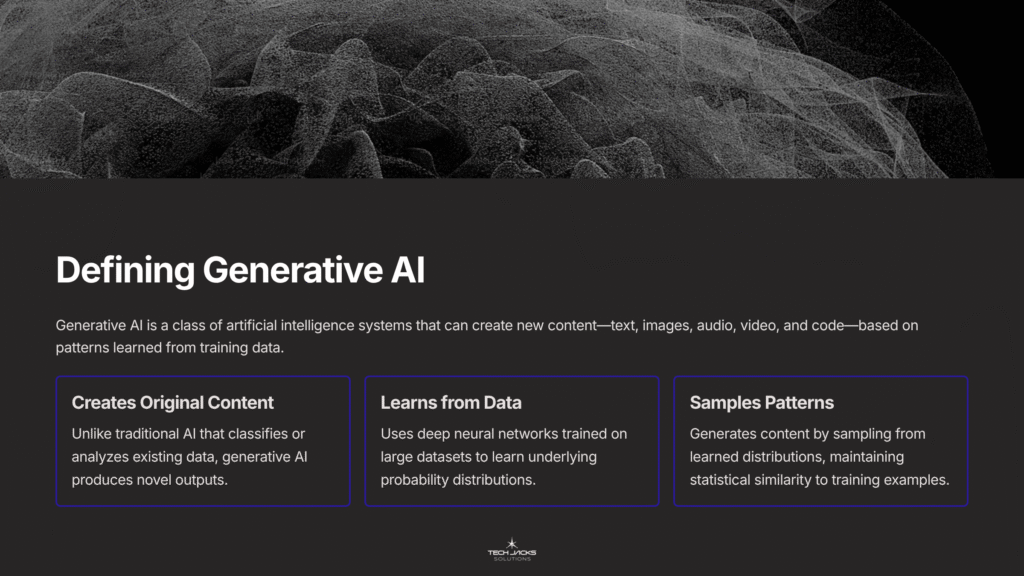
Generative AI is a class of artificial intelligence systems that can create new content, including text, images, audio, video, and code, based on patterns learned from training data. Unlike traditional AI that classifies or analyzes existing data, generative AI produces original outputs.
For those wanting technical precision: Generative AI uses machine learning models (particularly deep neural networks) trained on large datasets to learn the underlying probability distributions of the training data, then samples from those distributions to generate novel content that maintains statistical similarity to the training examples. Common architectures include Generative Adversarial Networks (GANs), Transformer models, and Diffusion models.
Here’s the crucial difference: traditional software executes programmed logic. If you write code that says “add 2+2,” it always returns 4. Rule-based AI follows more complex logic but still operates deterministically. Generative AI is probabilistic. The same prompt can produce different outputs because the model is sampling from learned probability distributions, not executing fixed instructions.
Unlike earlier “generative” systems like ELIZA (created 1964-1966 by Joseph Weizenbaum at MIT) which used pattern matching with pre-programmed templates, modern generative AI actually learns patterns from data. ELIZA appeared to hold conversations but was merely matching keywords to scripted responses. Today’s systems like GPT-4 or Claude have learned language patterns from billions of documents and can generate contextually appropriate responses to situations they’ve never explicitly been programmed to handle.
Why Generative AI Matters Now
Three converging factors make 2025 a critical moment for generative AI.

First, the architectural breakthrough happened. In 2017, Google researchers introduced the Transformer architecture with its self-attention mechanism. This solved the fundamental context problem that had limited previous approaches. Earlier models like LSTMs struggled with long sequences and couldn’t process language efficiently in parallel. Transformers changed that, making it computationally feasible to train models on trillions of words. That’s why we’re seeing capable systems now, not five years ago.
Second, compute power and data availability reached critical mass. Training GPT-3 required compute that would have been prohibitively expensive a decade ago. The internet provided text corpora large enough to teach models not just grammar but reasoning patterns, coding conventions, and domain knowledge across hundreds of fields.
Third, accessibility democratized the technology. OpenAI released GPT-1 in 2018, but it remained research-focused. ChatGPT (November 2022) put powerful generative AI in everyone’s hands through a simple chat interface. DALL-E (2021) did the same for image generation. Suddenly, anyone could experiment with technology that previously required PhD-level expertise.
This creates unprecedented opportunities and risks. Organizations can automate tasks that required human creativity. Students can access personalized tutoring. Developers can write code faster. But misinformation becomes easier to create. Bias in training data gets amplified. Copyright and intellectual property questions remain unresolved. That’s why understanding the technology matters, not just using it.

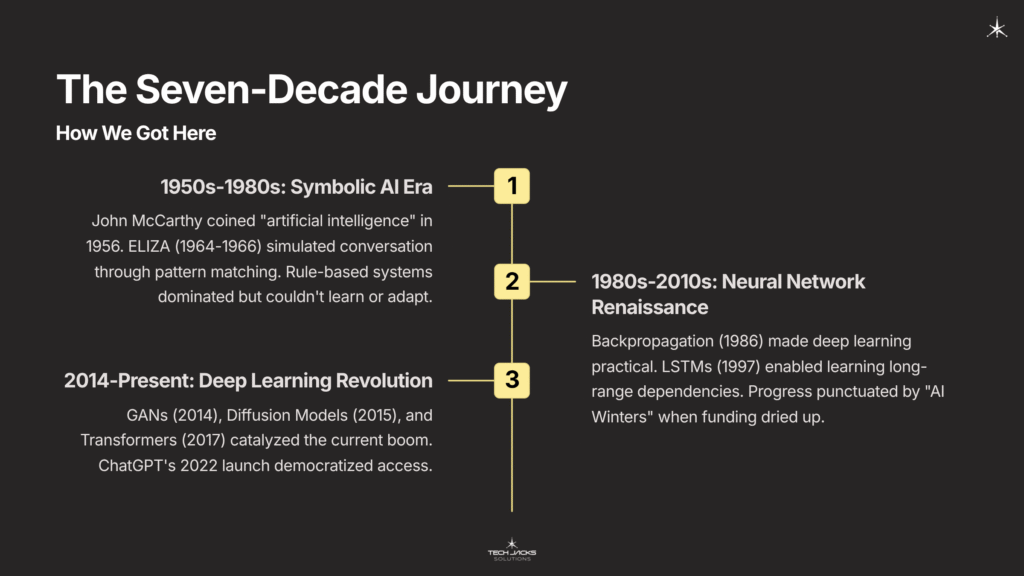
The Seven-Decade Journey: How We Got Here
The Symbolic AI Era (1950s-1980s)
The intellectual foundation goes back to 1956, when John McCarthy coined the term “artificial intelligence” at the Dartmouth Summer Research Project. Early AI researchers believed intelligence could be modeled through human-designed rules and logical structures. This “symbolic AI” approach dominated for decades.
The first systems that could be called “generative” operated on rule-based principles. ELIZA (1964-1966) simulated a psychotherapist by matching keywords in user input to pre-programmed response templates. It seemed impressive, but Weizenbaum himself acknowledged it was “completely non-intelligent,” just sophisticated pattern matching.
Expert systems like Dendral (molecular structure identification) and MYCIN (bacterial disease diagnosis) demonstrated that rule-based systems could generate specialized outputs. But they had fundamental limitations: they couldn’t learn from examples, adapt to new situations, or handle ambiguity well.
Meanwhile, statistical foundations were emerging. Andrey Markov’s work on Markov chains (1906) provided methods for modeling random processes. By the 1950s, Hidden Markov Models and Gaussian Mixture Models represented early true generative models capable of producing sequential data for applications like speech recognition. But these remained simple compared to modern systems.
The Neural Network Renaissance (1980s-2010s)
The 1980s brought a paradigm shift. Instead of programming explicit rules, what if machines could learn patterns from data? David Rumelhart popularized the backpropagation algorithm in 1986, making it practical to train multi-layered neural networks. This innovation made deep learning functionally possible, though computational limitations still constrained what could be built.
For sequential data like text and speech, Sepp Hochreiter and Jürgen Schmidhuber developed Long Short-Term Memory (LSTM) networks in 1997. LSTMs are a type of Recurrent Neural Network (RNN) that can learn long-range dependencies, overcoming a key limitation of earlier models. This proved crucial for machine translation and advanced speech recognition.
But progress was punctuated by “AI Winters” in the late 1970s and 1980s. Funding dried up when ambitious promises failed to materialize. Research continued, but slowly. The constraint wasn’t just algorithms, it was compute power and data availability.
The Deep Learning Revolution (2014-Present)
Three critical architectural breakthroughs catalyzed the current generative AI boom:
Generative Adversarial Networks (GANs) – Proposed in 2014 by Ian Goodfellow and colleagues, GANs introduced a novel adversarial training process. A GAN consists of two competing neural networks: a generator that creates synthetic data and a discriminator that tries to distinguish synthetic from real data. The two networks compete in a “game,” where the generator’s objective is to fool the discriminator. This framework enabled creation of photorealistic images without explicitly modeling the underlying probability distribution.
Diffusion Models – Introduced in 2015, these models work by learning to reverse a process of gradually adding noise to data until it becomes unrecognizable. By training a model to systematically remove noise step-by-step, it learns to generate high-fidelity outputs from random noise input. This is the core technology behind prominent text-to-image models like Stable Diffusion.
Transformer Architecture – Unveiled by Google researchers in 2017, the Transformer revolutionized natural language processing. Its key innovation is the “self-attention mechanism,” which allows the model to dynamically weigh the importance of all other words in a sequence when processing any given word. This captures complex, long-range context far more effectively than sequential processing of RNNs and LSTMs. Critically, it’s parallelizable, making massive models computationally feasible.
The Transformer was the essential precondition for today’s foundation models. OpenAI’s GPT series, starting with GPT-1 in 2018, applied this architecture to models trained on vast quantities of internet text. Each version scaled dramatically: GPT-2, GPT-3, and eventually GPT-4. The public release of user-friendly applications (DALL-E in 2021, ChatGPT in November 2022) democratized access and ignited the “Generative AI Boom.”
The history isn’t linear gradual improvement. It’s distinct paradigm shifts. Each major leap (rule-based to statistical, statistical to adversarial, sequential to attention-based) was unlocked by a fundamental architectural innovation solving a critical bottleneck. Markov Chains couldn’t remember context. LSTMs were inefficient on long sequences. Transformers solved both through attention mechanisms that could process entire sequences in parallel while maintaining context.
How Generative AI Actually Works
For Beginners: The Pattern Learning Analogy
Think of generative AI like an incredibly sophisticated pattern recognition and reproduction system. Imagine you showed someone millions of examples of paintings. They don’t memorize individual paintings, but they internalize patterns: how shadows work, how colors blend, composition principles, common subject matters. Later, you ask them to paint something new. They don’t copy any specific painting they saw, but they create something that “feels right” based on all those internalized patterns.
That’s essentially what generative AI does, but with mathematical representations of patterns rather than intuitive understanding. The model learns statistical relationships in training data, then generates new outputs that maintain those statistical relationships.
What “Training” Actually Means
When we say a model is “trained,” here’s what happens: The system is shown millions or billions of examples. For a language model, this might be text from books, websites, and articles. For each example, the model tries to predict what comes next. When it’s wrong, mathematical algorithms adjust billions of internal parameters (called “weights”) to improve future predictions. This happens trillions of times.
GPT-3, for instance, has 175 billion parameters, trained on hundreds of billions of words from internet text, books, and Wikipedia. That’s not 175 billion facts memorized, but 175 billion mathematical weights that collectively encode patterns learned from training data. The training process for large models can cost millions of dollars in compute power and take weeks or months, but once trained, the model can be used repeatedly without retraining (though it may need updates as knowledge becomes outdated).

For Technical Readers: The Architecture
Modern generative AI systems, particularly large language models, rely on the Transformer architecture. Here’s how it works:
Self-Attention Mechanism: When processing any word in a sequence, the model computes attention scores for every other word. This determines how much each word should influence the representation of the current word. “The cat sat on the mat” requires understanding that “sat” relates to “cat” (the subject) and “mat” (the location). Self-attention learns these relationships from data rather than relying on hand-coded grammar rules.
Positional Encoding: Since Transformers process sequences in parallel rather than sequentially, they need explicit information about word order. Positional encodings provide this, allowing the model to distinguish “dog bites man” from “man bites dog.”
Multi-Head Attention: Rather than computing attention once, the model does it multiple times in parallel with different learned weights. This allows it to capture different types of relationships simultaneously: syntactic, semantic, and contextual.
Feed-Forward Layers: After attention, each position’s representation passes through neural network layers that transform it based on learned patterns. This is where the model applies knowledge to generate outputs.
Training Process: Models learn through next-token prediction. Given a sequence of tokens, predict the next one. Do this billions of times across trillions of tokens, and the model learns not just grammar but reasoning patterns, factual associations, and task-specific behaviors. The loss function measures prediction accuracy, and backpropagation adjusts billions of parameters (weights) to improve predictions.
The Inference Process
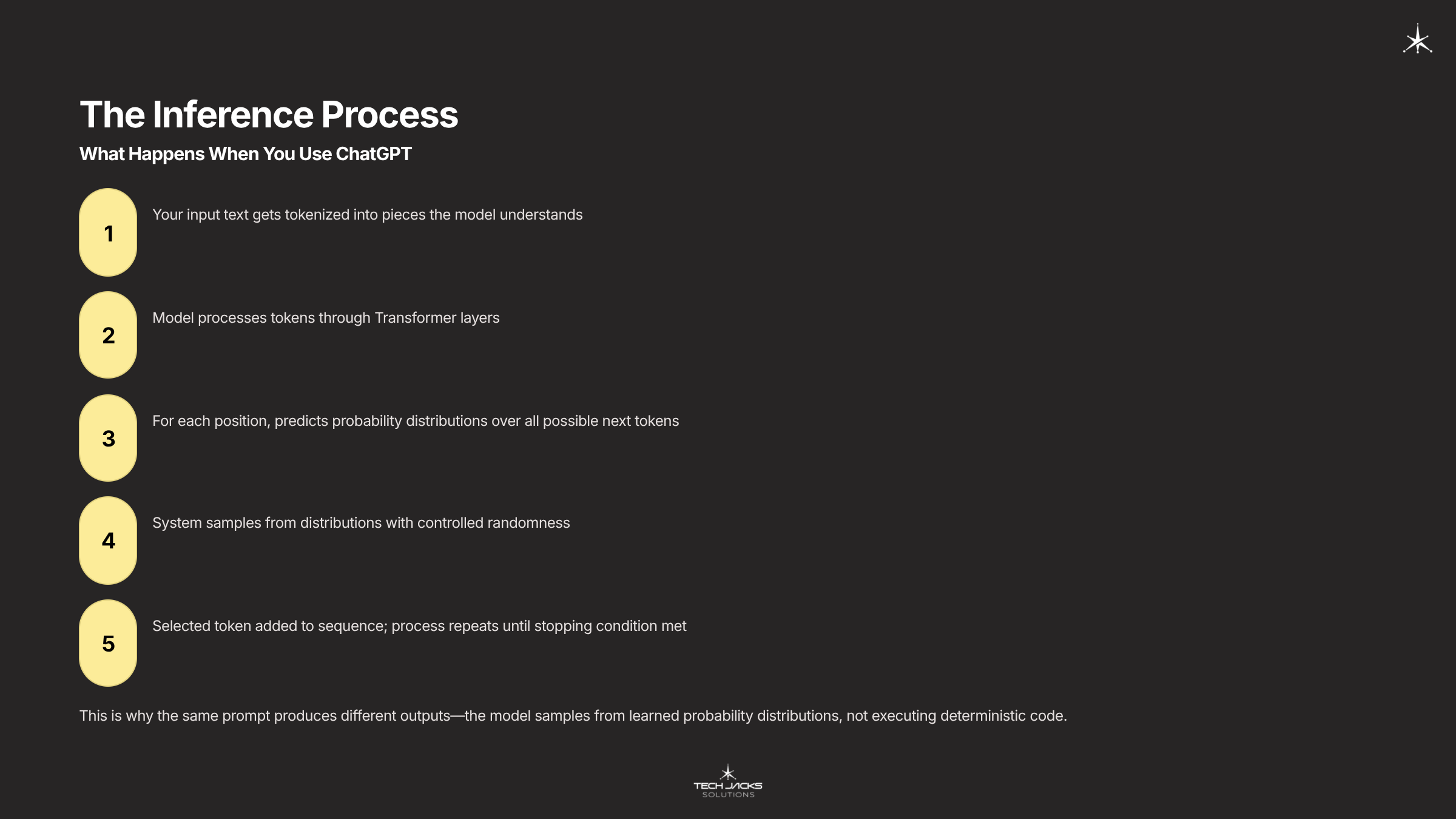
When you use ChatGPT or similar systems, here’s what happens:
- Your input text gets tokenized (broken into pieces the model understands)
- The model processes tokens through its Transformer layers
- For each position, it predicts probability distributions over all possible next tokens
- The system samples from these distributions (with some randomness controlled by “temperature” settings)
- The selected token gets added to the sequence
- Process repeats until a stopping condition is met
This is why the same prompt can produce different outputs. The model isn’t executing deterministic code, it’s sampling from learned probability distributions.
Foundation Models vs. Fine-Tuned Models
Foundation Models are large pre-trained models like GPT-4, Claude, or Gemini. These are trained on massive, diverse datasets covering broad knowledge. Most users interact with foundation models directly through chat interfaces or APIs. They’re called “foundation” because they can be adapted for many tasks without modification.
Fine-Tuned Models are foundation models that receive additional training on specialized datasets. For example, a medical institution might fine-tune GPT-4 on clinical notes to improve accuracy with medical terminology. Fine-tuning is expensive and requires ML expertise, so it’s typically done only when foundation models alone can’t achieve required performance.
Most applications use foundation models with clever prompting rather than fine-tuning.

Alignment and Safety: RLHF
Raw language models trained only on internet text can generate harmful, biased, or unhelpful content. To make them useful and safe, developers use Reinforcement Learning from Human Feedback (RLHF).
Here’s how it works: Human reviewers rate different model outputs for the same prompt (helpful vs. unhelpful, truthful vs. false, harmless vs. harmful). The model learns from these preferences to generate outputs humans find more valuable and less harmful. This is why ChatGPT usually tries to be helpful rather than generating offensive content, even though such content exists in its training data.
RLHF doesn’t make models perfect. They can still generate false information, exhibit bias, or refuse reasonable requests. But it significantly improves their practical usefulness and safety compared to raw pre-trained models.

Types of Generative AI Systems
Large Language Models (LLMs)
What They Are: Neural networks trained on vast text corpora to understand and generate human language. Examples include GPT-4, Claude, Gemini, and Llama.
Technical Foundation: Transformer architecture trained on hundreds of billions to trillions of words. Model sizes range from millions to hundreds of billions of parameters.
Capabilities:
- Text generation (articles, stories, code, emails)
- Question answering and information synthesis
- Translation and summarization
- Reasoning and problem-solving
- Code generation and debugging
Limitations: Can “hallucinate” (confidently generate false information), training data cutoff means no knowledge of recent events, reasoning capabilities have bounds, potential bias from training data.
Real-World Application: A law firm uses an LLM to draft initial contract summaries. Lawyers review and edit, but the model handles routine language processing, saving hours per contract.
Text-to-Image Models
What They Are: Systems that generate images from text descriptions. Examples include DALL-E, Midjourney, and Stable Diffusion.
Technical Foundation: Typically use diffusion models trained on millions of image-text pairs. They learn to reverse a noising process, gradually transforming random noise into coherent images matching text prompts.
Capabilities:
- Creating original artwork and designs
- Generating marketing materials
- Prototyping visual concepts
- Creating variations on themes
- Style transfer and image editing
Limitations: Struggles with text in images, difficulty with anatomical accuracy (particularly hands), occasional incoherent elements, copyright concerns for training data.
Real-World Application: An e-commerce company generates thousands of product lifestyle images showing items in different settings and lighting conditions, without expensive photo shoots.
Text-to-Audio/Music Models
What They Are: Systems generating speech, sound effects, or music from text descriptions or other inputs.
Technical Foundation: Various architectures including Transformers and diffusion models adapted for audio waveforms or spectrograms.
Capabilities:
- Text-to-speech with natural intonation
- Music composition in various styles
- Sound effect generation
- Voice cloning and modification
Limitations: Music often lacks emotional depth and narrative development of human composition, voice cloning raises ethical concerns, quality varies significantly by use case.
Real-World Application: An audiobook publisher uses text-to-speech to create audio versions of backlist titles cost-effectively, making more content accessible to visually impaired readers.
Text-to-Video Models
What They Are: Emerging systems that generate video content from text descriptions. Examples include Sora, Runway, and others.
Technical Foundation: Extremely computationally intensive, often combining multiple model types. Still rapidly evolving.
Capabilities:
- Generating short video clips from descriptions
- Animating static images
- Video editing and effects
- Creating synthetic training data
Limitations: Still in early stages, computationally expensive, limited duration, occasional physics violations or temporal inconsistencies, copyright and deepfake concerns.
Real-World Application: Film studios use AI to generate concept videos for storyboarding and pre-visualization, helping teams align on creative vision before expensive production begins.
Code Generation Models
What They Are: LLMs specifically trained or fine-tuned for programming tasks. Examples include GitHub Copilot (powered by GPT-4), CodeLlama, and others.
Technical Foundation: Transformer models trained on code repositories and programming documentation.
Capabilities:
- Auto-completing code as developers write
- Generating functions from natural language descriptions
- Explaining and debugging existing code
- Converting between programming languages
- Writing tests and documentation
Limitations: Can generate insecure or inefficient code, may suggest outdated patterns, requires developer review and validation, potential licensing concerns for training data.
Real-World Application: A software team uses code generation for boilerplate code and unit tests, letting developers focus on complex logic and architecture. Productivity gains vary, but some developers report 20-30% time savings.
Comparison Table
| Type | Best For | Training Data | Output | Compute Cost |
| LLMs | Text tasks, reasoning, general intelligence | Trillions of words | Text, code | High |
| Text-to-Image | Visual content creation, design | Millions of image-text pairs | Images | Medium-High |
| Text-to-Audio | Voice synthesis, music | Audio recordings, MIDI | Audio waveforms | Medium |
| Text-to-Video | Motion content, animation | Video datasets | Video sequences | Very High |
| Code Models | Programming assistance | Code repositories | Source code | High |

The Generative AI Lifecycle: From Concept to Retirement
Understanding generative AI isn’t just about the technology itself. It’s about how organizations actually implement, deploy, and manage these systems responsibly. The generative AI lifecycle is a five-phase structured approach that differs fundamentally from traditional software development.
Why the Lifecycle Matters
Traditional software follows predictable paths. You write requirements, build to spec, test, deploy. The outcome is deterministic. GenAI development is empirical. You’re testing hypotheses about how a pre-trained model will behave when prompted, fine-tuned, or connected to your data. The outcome isn’t guaranteed no matter how carefully you plan.
This experimental nature means GenAI projects need management like scientific experiments, not engineering projects. Organizations that treat them like traditional software keep failing. Those that embrace the lifecycle move from pilot to production.
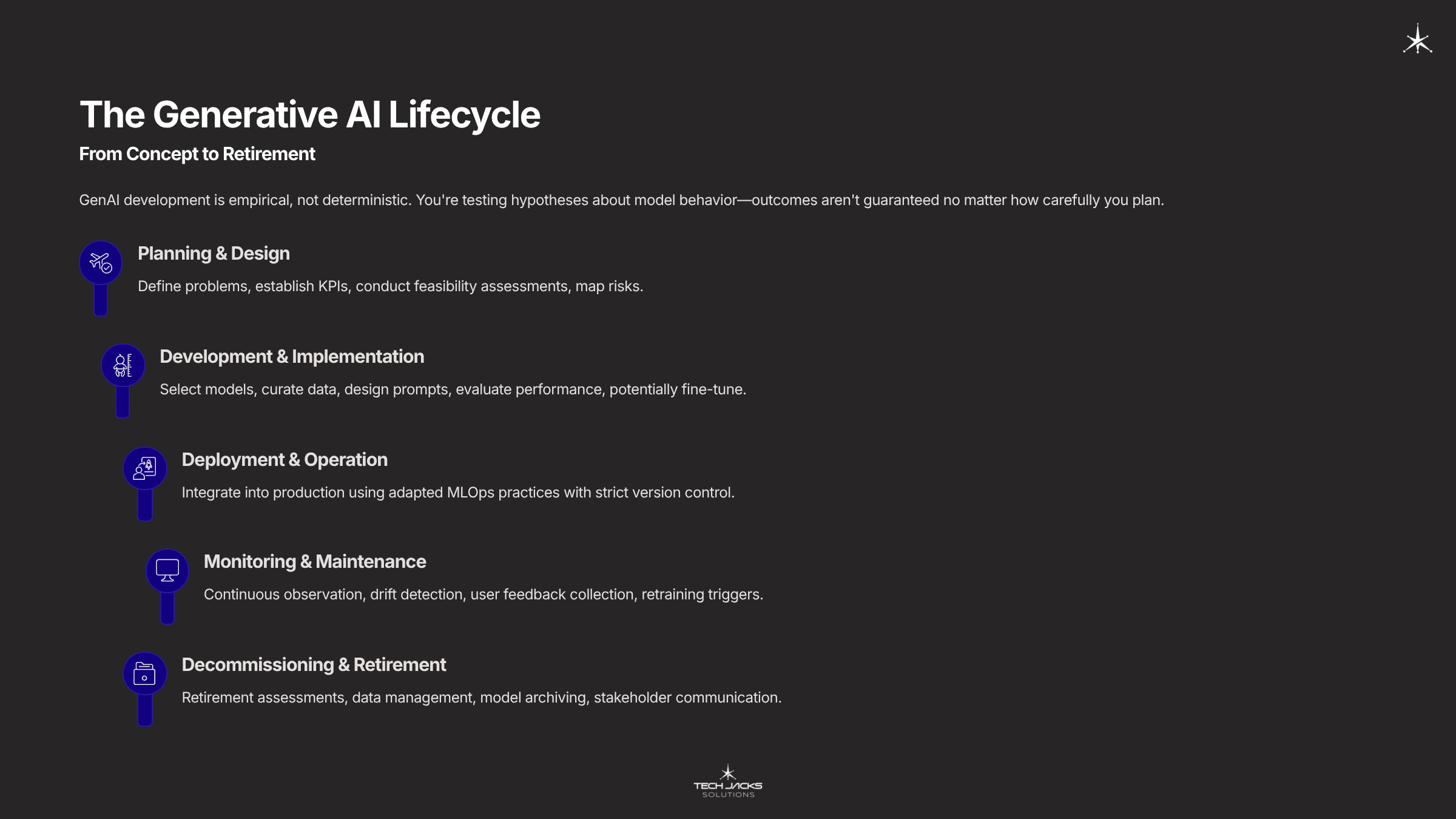
The Five Phases
Phase 1: Planning and Design
Define business problems, establish measurable KPIs, conduct feasibility assessments, and map risks. Most teams skip feasibility assessment, assuming if the technology exists, their use case will work. Wrong assumption. You need to determine whether your data is sufficient, whether foundation models can handle your domain, and whether the business case justifies the experimental nature.
Output: Business case, prioritized use cases, feasibility report, KPI framework, initial risk assessment.
Phase 2: Development and Implementation
Select foundation models, curate data, design prompts, evaluate performance, potentially fine-tune. This is where experimentation happens. Three customization approaches dominate: prompt engineering (fastest, lowest cost), fine-tuning (moderate effort, more control), and Retrieval-Augmented Generation (RAG, for current information and proprietary data).
Output: Selected model, curated dataset, prompt templates, evaluation report.
Phase 3: Deployment and Operation
Integrate the validated model into production using adapted MLOps practices. Critical activities include API integration, strict version control for all components (prompt templates, RAG data stores, orchestration logic), CI/CD pipelines, and inference infrastructure.
Without version control on every component, you can’t reproduce results or roll back deployments.
Phase 4: Monitoring and Maintenance
Continuous observation prevents performance degradation. Monitor operational metrics (latency, throughput, errors), detect model drift (performance deteriorates as real-world data diverges from training data), collect user feedback, trigger retraining.
Model drift is insidious. Your model works perfectly at launch. Six months later, it’s producing poor outputs because underlying patterns in your data shifted. Without monitoring, you won’t know until users complain.
Phase 5: Decommissioning and Retirement
This phase represents a critical governance gap. Organizations accumulate aging models as vendors release new versions. Without formal retirement processes, you’re paying to host unused systems while facing latent risks.
Key activities: retirement assessments, data management per regulations (GDPR), model archiving for audit trails, stakeholder communication.
Governance Frameworks
A global governance landscape is forming around complementary pillars:
EU AI Act (came into force August 2024): Establishes risk-based regulatory framework with binding requirements. General-Purpose AI models must maintain documentation, provide information to downstream developers, implement copyright compliance.
NIST AI Risk Management Framework: Provides voluntary methodology for managing AI risks through four functions: Govern, Map, Measure, Manage.
ISO/IEC 42001: First international standard for AI management systems, offering certifiable processes proving compliance to external parties.
These frameworks work together. The EU AI Act establishes legal requirements. NIST provides implementation methodology. ISO/IEC 42001 offers certification.
Real-World Applications Across Industries
Healthcare
Application: Clinical documentation assistance. Systems fine-tuned on medical terminology help physicians generate clinical notes from patient interactions.
Value: Reduces documentation time from hours to minutes per patient. Physicians can focus on patient care rather than paperwork.
Considerations: Requires extensive validation, human oversight mandatory, HIPAA compliance critical, cannot replace clinical judgment.
Financial Services
Application: Fraud detection enhancement using RAG. Models connect to proprietary transaction databases to identify patterns suggesting fraud.
Value: Faster detection of novel fraud patterns, explainable recommendations through cited historical examples.
Considerations: Must be explainable for regulatory compliance, false positives impact customer experience, requires continuous monitoring as fraud tactics evolve.
Legal
Application: Contract analysis and drafting. Models extract key terms, identify risks, and generate initial drafts.
Value: Paralegals and attorneys save hours per contract on routine language processing.
Considerations: Attorney review required, liability concerns for errors, training data licensing questions, cannot replace legal judgment.
Education
Application: Personalized tutoring and content generation. Systems adapt explanations to student learning styles and knowledge gaps.
Value: Scalable personalized instruction, 24/7 availability, multiple explanation approaches.
Considerations: Risk of overreliance, potential for generating incorrect information, questions about academic integrity, digital divide concerns.
Marketing and Creative
Application: Content generation for marketing materials, social media, product descriptions.
Value: Rapid iteration on creative concepts, A/B testing at scale, multilingual content generation.
Considerations: Lacks human emotional intelligence, brand voice consistency challenges, copyright questions for training data, potential for generic output.
Software Development
Application: Code generation, debugging assistance, documentation writing.
Value: Productivity improvements reported by developers using AI assistants, faster prototyping.
Considerations: Security review required for generated code, potential licensing issues, may suggest outdated patterns, cannot replace software engineering expertise.
Manufacturing
Application: Predictive maintenance using models analyzing equipment sensor data and maintenance logs.
Value: Prevents costly downtime, optimizes maintenance schedules.
Considerations: Requires extensive domain data, false positives expensive, safety-critical applications need human oversight.

Benefits and Challenges of Generative AI
Key Benefits
Productivity Amplification: Automates routine tasks that previously required human intelligence. Developers write code faster. Writers overcome blank page. Analysts generate reports more quickly.
Accessibility: Democratizes capabilities that required specialized expertise. Anyone can create images without artistic training, write code without years of programming experience, or access information without research skills.
Personalization at Scale: Enables individualized content, recommendations, and experiences for millions of users simultaneously.
Rapid Prototyping: Allows quick iteration on ideas. Generate ten design concepts in minutes. Test multiple marketing messages instantly. Explore solution spaces faster than traditional methods.
24/7 Availability: Systems don’t need sleep, breaks, or time off. Customer support, tutoring, and information access available constantly.
Cost Reduction: Can reduce costs for content creation, customer service, data analysis, and other tasks when implemented appropriately.
Critical Challenges
Hallucination: Models confidently generate false information. They don’t “know” facts, they predict statistically plausible text. Critical for high-stakes decisions.
Bias Amplification: Training data contains societal biases. Models can amplify these biases in outputs. Requires proactive auditing and mitigation.
Intellectual Property Concerns: Training on copyrighted data raises legal questions. Generated outputs may inadvertently reproduce training data. Licensing and attribution remain unresolved.
Environmental Impact: Training large models requires massive compute power. Energy consumption and carbon footprint significant. Inference at scale also resource-intensive.
Security Vulnerabilities: Models can be manipulated through adversarial prompts. Risk of data leakage if trained on proprietary information. Potential for generating malicious code or content.
Job Displacement: Automation of cognitive tasks raises workforce concerns. While creating new roles, displaces others. Requires workforce adaptation and retraining.
Misinformation and Deepfakes: Makes creating convincing fake content easier. Text, images, audio, and video can be synthesized at scale. Challenges trust in digital media.
Overreliance Risk: Users may trust AI outputs without verification. Students might lose critical thinking skills. Professionals might accept outputs without domain validation.
Concentration of Power: Most capable models controlled by handful of large companies. Creates dependencies and raises antitrust concerns.
Accountability Questions: When AI generates harmful content or makes costly errors, who’s responsible? Developer? Deployer? User? Legal frameworks evolving.

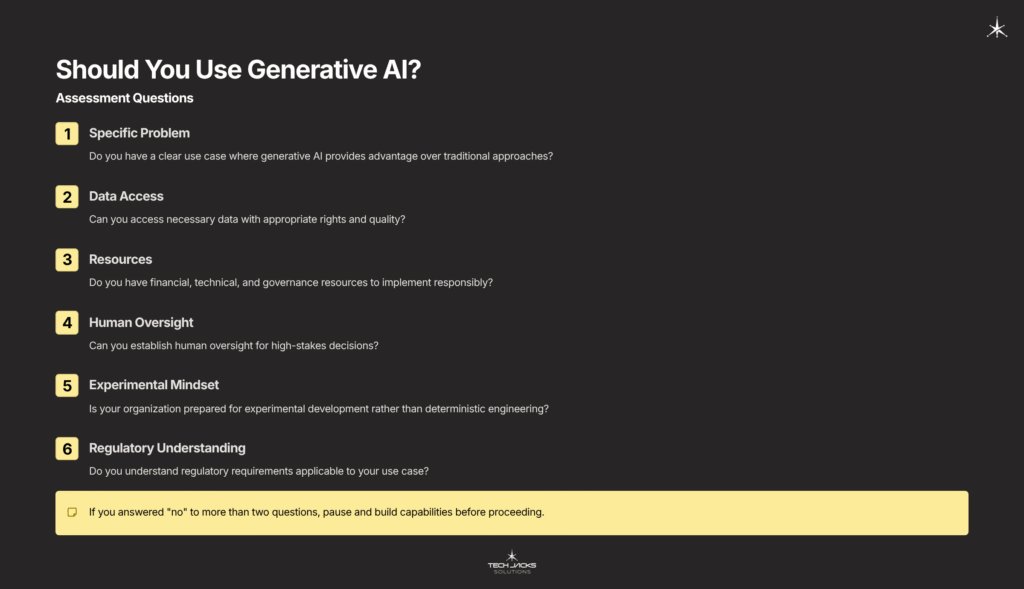
Should You Use Generative AI?
Assessment Questions
Before implementing generative AI, ask:
- Do you have a specific problem where generative AI provides clear advantage over traditional approaches?
- Can you access necessary data with appropriate rights and quality?
- Do you have resources (financial, technical, governance) to implement responsibly?
- Can you establish human oversight for high-stakes decisions?
- Is your organization prepared for experimental development rather than deterministic engineering?
- Do you understand regulatory requirements applicable to your use case?
If you answered “no” to more than two, pause and build capabilities before proceeding.
Choose Generative AI When…
- The task involves pattern recognition, content creation, or natural language understanding
- You have access to relevant training data or can use pre-trained models
- Probabilistic outputs are acceptable (not safety-critical deterministic systems)
- You can implement appropriate human oversight and validation
- The potential value justifies implementation and operational costs
- You have governance structures for responsible deployment
Avoid Generative AI When…
- Traditional deterministic algorithms solve the problem better
- Errors have severe consequences without human review feasibility
- You lack technical capabilities and can’t acquire them
- Regulatory requirements unclear or prohibitive
- You’re pursuing it because it’s trendy, not because it solves a problem
- Stakeholder trust would be irreparably damaged by errors
Starting Your Journey
For Individual Users:
- Experiment with free tools (ChatGPT, Claude, Perplexity)
- Learn prompt engineering basics
- Validate outputs before trusting them
- Understand limitations and appropriate use cases
- Consider privacy before sharing sensitive information
For Organizations:
- Start with low-risk use cases with clear success metrics
- Establish governance structures before scaling
- Invest in training for employees
- Understand regulatory landscape
- Build internal expertise or partner with experienced providers
- Follow lifecycle phases systematically
Frequently Asked Questions
What’s the difference between AI, machine learning, and generative AI?
AI is the broadest term: any system exhibiting intelligent behavior. Machine learning is a subset: systems that learn from data rather than following explicit programming. Generative AI is a subset of machine learning: systems specifically designed to create new content. All generative AI is machine learning, but not all machine learning is generative (classification and prediction systems aren’t generative).
How do I know if content was created by AI?
It’s increasingly difficult. Some indicators: unusual phrasings, overly formal tone, lack of personal experience details, generic observations. However, capable users can edit AI outputs to seem human-written, and humans can write in AI-like style. Dedicated detection tools exist but have limited accuracy. Watermarking approaches are being developed but aren’t universal yet.
Is generative AI going to take my job?
Generative AI will transform jobs rather than simply eliminate them. It automates routine cognitive tasks, similar to how previous technologies automated manual tasks. Jobs involving creative problem-solving, complex human interaction, strategic thinking, and domain expertise remain valuable. The key is learning to work effectively with AI tools rather than being replaced by them. Roles will evolve: we’ll need prompt engineers, AI trainers, ethics reviewers, and oversight specialists.
Can generative AI be creative?
This depends on how you define creativity. GenAI can produce novel combinations and variations that humans find surprising or interesting. It can generate artwork, music, and writing that people value. However, it lacks consciousness, intentionality, emotional experience, and cultural context that inform human creativity. It’s recombining learned patterns rather than experiencing genuine inspiration. The debate continues about whether this constitutes “real” creativity.
Why does ChatGPT sometimes give wrong answers?
Language models predict statistically plausible text based on training data patterns. They don’t have access to truth databases or reasoning from first principles. If the training data contained misinformation, or if the question requires knowledge beyond the training data, the model may “hallucinate” plausible-sounding but incorrect answers. It optimizes for sounding right, not being right. Always verify important information.
Is my data safe when using AI tools?
It depends on the tool and how it’s configured. Public AI services may use your inputs to improve models unless you opt out. Enterprise versions typically offer data isolation guarantees. Read privacy policies carefully. Never share confidential information with public AI tools unless you understand data handling practices. For sensitive use cases, consider private deployments where you control the infrastructure.
How much does it cost to use generative AI?
For consumers: Many tools offer free tiers (ChatGPT, Claude, Perplexity). Paid plans typically $20-30 monthly. For organizations: Commercial API costs depend on usage (typically per token/image/audio duration). Fine-tuning or private deployments can cost thousands to hundreds of thousands annually. Factor in infrastructure, personnel, and governance costs. Total implementation costs vary widely by use case and scale.
Can I trust AI to make important decisions?
No. Generative AI should augment human decision-making, not replace it, especially for consequential decisions. Use AI to gather information, generate options, or identify patterns, but maintain human judgment for final decisions. In high-stakes domains (healthcare, legal, financial), regulatory requirements often mandate human oversight.
What’s the environmental impact of generative AI?
Training large models requires massive compute power, consuming significant energy and producing carbon emissions. GPT-3 training reportedly consumed energy equivalent to 120 US homes’ annual usage. However, once trained, inference (actually using the model) is far less intensive. Organizations increasingly offset emissions or use renewable energy. The full lifecycle environmental impact remains an active area of research and concern.
How can I learn to use generative AI effectively?
Start by experimenting with free tools. Learn prompt engineering: being specific, providing examples, setting context. Understand limitations: verify important outputs, don’t trust blindly. Read documentation and guides from model providers. Take online courses in AI literacy. Practice on low-stakes tasks before critical applications. Join communities sharing best practices.
What regulations apply to generative AI?
The EU AI Act establishes binding requirements in Europe. The US has sector-specific regulations (healthcare, finance) but no comprehensive AI law yet. Copyright law questions remain unresolved. Privacy regulations (GDPR, CCPA) apply to data handling. The landscape is evolving rapidly. Consult legal counsel for compliance in your jurisdiction and use case.
Can generative AI understand context and nuance?
Partially. Models learn statistical patterns of context from training data. They can often apply these patterns appropriately. However, they lack genuine understanding of meaning, cultural context, situational awareness, or emotional intelligence. They process text statistically, not semantically. This means they can miss subtle nuances, misunderstand implied context, or apply learned patterns inappropriately.
What’s the difference between GPT-4, Claude, and other models?
Different organizations (OpenAI, Anthropic, Google) train models with different architectures, training data, objectives, and safety approaches. This leads to variations in capabilities, personality, knowledge, reasoning patterns, and limitations. GPT-4 might excel at creative writing, Claude at following detailed instructions, Gemini at multimodal tasks. Quality, cost, and features vary. Test multiple models for your specific use case.
Will generative AI keep improving?
Likely, yes, though the rate of improvement is debated. Compute continues increasing. Training techniques improve. New architectures emerge. However, we may be approaching diminishing returns on pure scaling. Future improvements might come from efficiency, specialized models, better reasoning capabilities, or entirely new approaches. The field is still rapidly evolving.
How do I cite AI-generated content?
Citation practices are evolving. Generally: indicate content was AI-generated, specify which tool (ChatGPT, Claude, etc.), include date accessed, note significant human editing. Academic institutions have varying policies. Some prohibit AI use for certain assignments, others require disclosure. Check guidelines for your specific context. Remember: you’re responsible for content accuracy regardless of how it was generated.

Ready to Test Your Knowledge?
Resources for Learning More
Official Documentation & Standards
Foundational Frameworks:
- NIST AI Risk Management Framework (AI RMF 1.0) – Comprehensive guide for understanding and managing AI risks
- NIST Trustworthy AI (NIST AI 600-1) – Specific guidance for generative AI systems
- EU AI Act Official Documentation – Complete text of EU’s regulatory framework
- EU AI Act Explorer – Interactive guide to requirements
International Standards:
- ISO/IEC 42001 AI Management Systems – Certification standard for AI governance
- ISO/IEC Standards for AI – Overview of applicable standards
- IEEE P7018 – Security standards for generative AI
Educational Resources
For Beginners:
- MIT News: Explained – Generative AI – Accessible technical explanation
- Coursera: History of AI – Timeline from 1956 to present
- Wikipedia: Generative AI – Comprehensive overview with references
For Technical Learners:
- Qualcomm: Rise of Generative AI – Technical breakthrough timeline
- Toloka: History of Generative AI – Detailed historical analysis
- Dataversity: Brief History of Generative AI – Technical evolution
Implementation Guides
Cloud Provider Documentation:
- AWS Generative AI Lens – Comprehensive lifecycle guide
- Google Cloud: Deploy GenAI Applications – Architecture patterns
- Azure AI Architecture – Microsoft’s implementation frameworks
Best Practices:
- McKinsey: Implementing GenAI – Governance and strategy
- AWS: Transforming SDLC with GenAI – Development practices
- Google Cloud: GenAI KPIs – Measurement frameworks
Governance & Ethics
Legal & Policy:
- Congress.gov: GenAI and Copyright – Legal landscape analysis
- Oxford Academic: Governance of GenAI – Policy frameworks
- EU Digital Strategy – Regulatory context
Practical Tools:
- AIHR: RACI Templates – Organizational frameworks
- Edvantis: Selecting AI Use Cases – Feasibility assessment
- Wiz Academy: NIST AI RMF Guide – Practical implementation
The Path Forward
Generative AI represents a fundamental shift in how computers create content and assist human intelligence. It’s not magic. It’s mathematics, engineering, and enormous amounts of data combined into systems that can generate novel outputs by learning patterns.
For seven decades, researchers worked to make machines truly generative. From ELIZA’s simple pattern matching in 1964 to GPT-4’s sophisticated reasoning in 2023, each breakthrough solved limitations that constrained previous approaches. The Transformer architecture in 2017 was the critical catalyst that made today’s systems possible.
The technology is here. Regulations are being established. Best practices are emerging. But understanding matters more than adoption speed.
Generative AI works best when humans understand its capabilities and limitations. When organizations follow structured lifecycles rather than treating it like traditional software. When users verify outputs rather than trusting blindly. When we use it to augment human intelligence rather than replace human judgment.
Start small. Experiment thoughtfully. Learn continuously. The technology will keep evolving. Your understanding of how to use it responsibly is what matters most.