
AI News September 30 2025 | The 30-Hour Coding Agent Anthropic just dropped Claude Sonnet 4.5 on September 29, 2025. Not another chatbot upgrade. A coding agent that works autonomously for over 30 hours straight. That’s up from seven hours with Claude Opus 4. Think about what you can build when an AI maintains focus […]
AI News September 9 29 2025 Microsoft just cut off an Israeli military unit’s cloud access. Asana’s betting AI needs human partners. And someone’s about to spend $450 billion on chips. That’s your AI news for the last 24 hours. The Money’s Real. The Trust Isn’t. Morningstar’s semiconductor analysis landed this morning with numbers that […]

CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignmentcs.AI updates on arXiv.orgon September 26, 2025 at 4:00 am arXiv:2508.06434v2 Announce Type: replace-cross
Abstract: Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model’s ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
arXiv:2508.06434v2 Announce Type: replace-cross
Abstract: Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model’s ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin. Read More
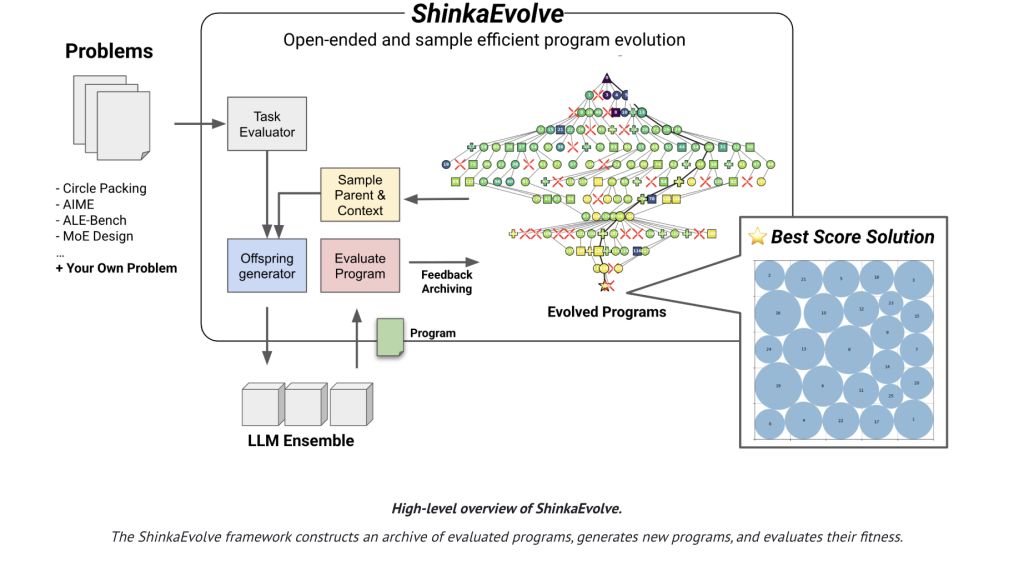
Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-EfficiencyMarkTechPoston September 26, 2025 at 9:15 am Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA
The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost.
Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA
The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost. Read More
AnyPlace: Learning Generalized Object Placement for Robot Manipulationcs.AI updates on arXiv.orgon September 26, 2025 at 4:00 am arXiv:2502.04531v2 Announce Type: replace-cross
Abstract: Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle — such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.
arXiv:2502.04531v2 Announce Type: replace-cross
Abstract: Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle — such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io. Read More
Google AI Ships a Model Context Protocol (MCP) Server for Data Commons, Giving AI Agents First-Class Access to Public StatsMarkTechPoston September 26, 2025 at 8:05 am Google released a Model Context Protocol (MCP) server for Data Commons, exposing the project’s interconnected public datasets—census, health, climate, economics—through a standards-based interface that agentic systems can query in natural language. The Data Commons MCP Server is available now with quickstarts for Gemini CLI and Google’s Agent Development Kit (ADK). What was released Why MCP
The post Google AI Ships a Model Context Protocol (MCP) Server for Data Commons, Giving AI Agents First-Class Access to Public Stats appeared first on MarkTechPost.
Google released a Model Context Protocol (MCP) server for Data Commons, exposing the project’s interconnected public datasets—census, health, climate, economics—through a standards-based interface that agentic systems can query in natural language. The Data Commons MCP Server is available now with quickstarts for Gemini CLI and Google’s Agent Development Kit (ADK). What was released Why MCP
The post Google AI Ships a Model Context Protocol (MCP) Server for Data Commons, Giving AI Agents First-Class Access to Public Stats appeared first on MarkTechPost. Read More

Nano Banana Practical Prompting & Usage GuideKDnuggetson September 26, 2025 at 12:00 pm In this article we will take a look at what Nano Banana excels at, some tips and tricks for using the model, and lay out a series of example prompts and promoting strategies for getting the most out of using it.
In this article we will take a look at what Nano Banana excels at, some tips and tricks for using the model, and lay out a series of example prompts and promoting strategies for getting the most out of using it. Read More

Ethical cybersecurity practice reshapes enterprise security in 2025AI Newson September 26, 2025 at 8:20 am When ransomware attacks like Akira and Ryuk began crippling organisations worldwide, the cybersecurity industry’s first instinct was predictable: build bigger walls, deploy more aggressive automated responses, and lock down everything. But there was a different problem emerging, according to Romanus Prabhu Raymond, Director of Technology at ManageEngine. The company’s customers were demanding aggressive containment features,
The post Ethical cybersecurity practice reshapes enterprise security in 2025 appeared first on AI News.
When ransomware attacks like Akira and Ryuk began crippling organisations worldwide, the cybersecurity industry’s first instinct was predictable: build bigger walls, deploy more aggressive automated responses, and lock down everything. But there was a different problem emerging, according to Romanus Prabhu Raymond, Director of Technology at ManageEngine. The company’s customers were demanding aggressive containment features,
The post Ethical cybersecurity practice reshapes enterprise security in 2025 appeared first on AI News. Read More
Notes on LLM EvaluationTowards Data Scienceon September 25, 2025 at 4:55 pm A practical, step-by-step guide to building an evaluation pipeline for a real-world AI application
The post Notes on LLM Evaluation appeared first on Towards Data Science.
A practical, step-by-step guide to building an evaluation pipeline for a real-world AI application
The post Notes on LLM Evaluation appeared first on Towards Data Science. Read More
Building a Video Game Recommender System with FastAPI, PostgreSQL, and Render: Part 2Towards Data Scienceon September 25, 2025 at 12:32 pm Deploying a FastAPI + PostgreSQL recommender system as a web application on Render
The post Building a Video Game Recommender System with FastAPI, PostgreSQL, and Render: Part 2 appeared first on Towards Data Science.
Deploying a FastAPI + PostgreSQL recommender system as a web application on Render
The post Building a Video Game Recommender System with FastAPI, PostgreSQL, and Render: Part 2 appeared first on Towards Data Science. Read More
- 1
- 2