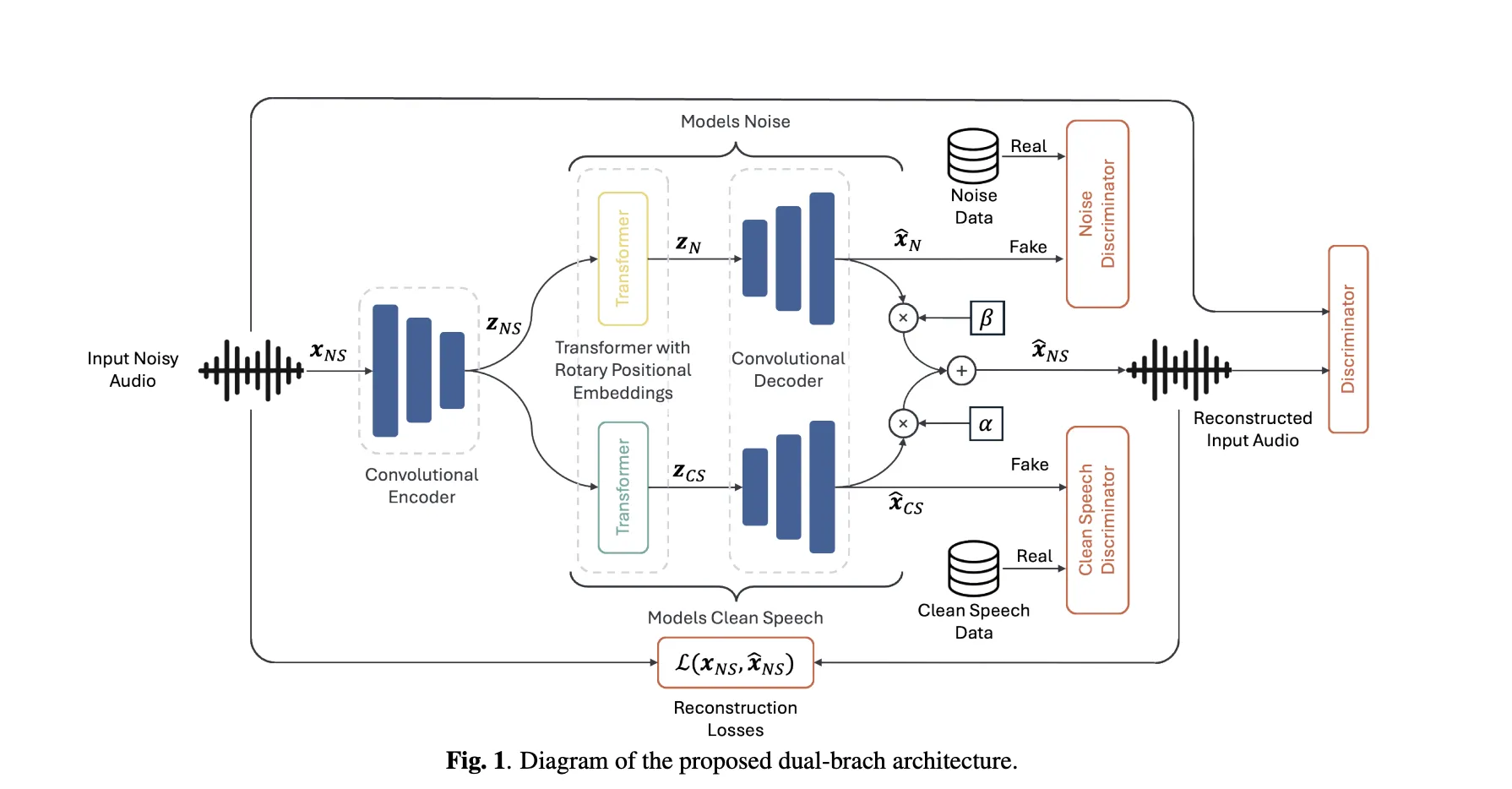
Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual
The post This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE) appeared first on MarkTechPost. Read More