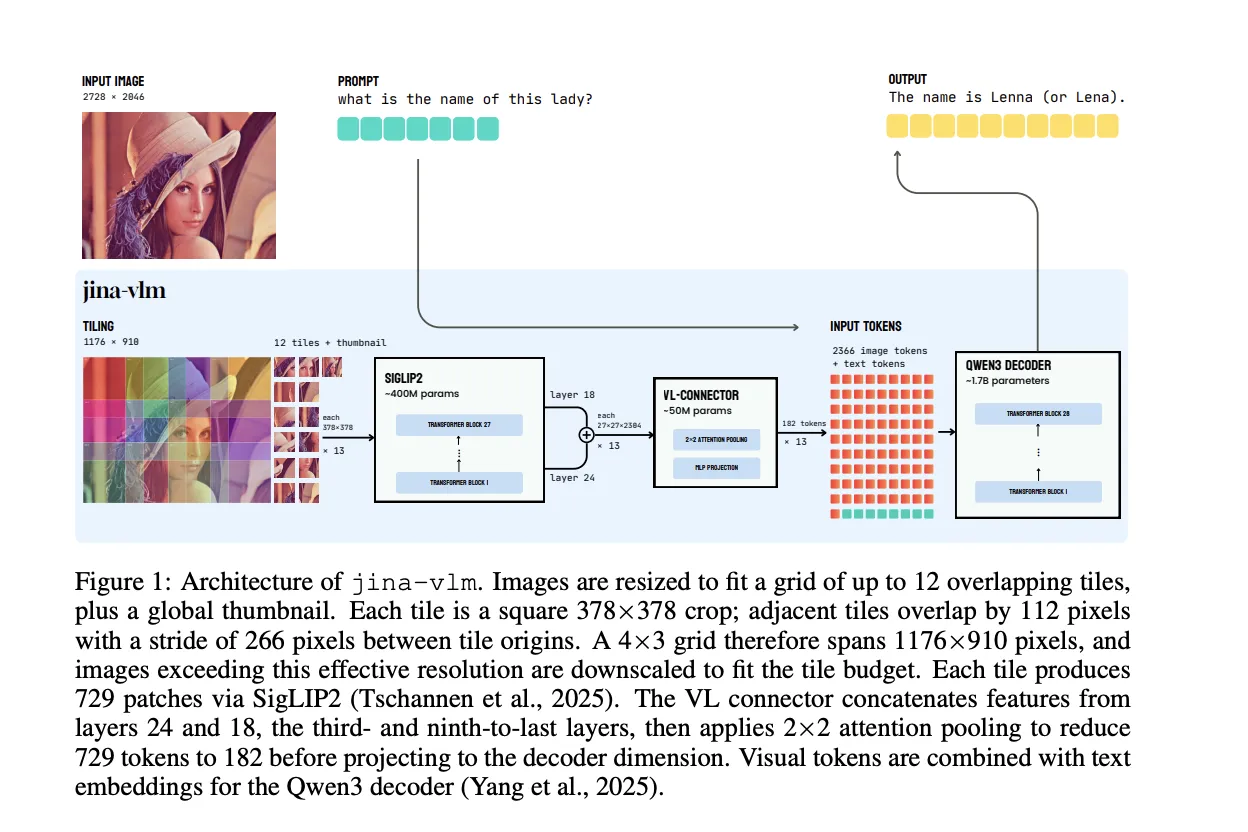
Jina AI has released Jina-VLM, a 2.4B parameter vision language model that targets multilingual visual question answering and document understanding on constrained hardware. The model couples a SigLIP2 vision encoder with a Qwen3 language backbone and uses an attention pooling connector to reduce visual tokens while preserving spatial structure. Among open 2B scale VLMs, it
The post Jina AI Releases Jina-VLM: A 2.4B Multilingual Vision Language Model Focused on Token Efficient Visual QA appeared first on MarkTechPost. Read More