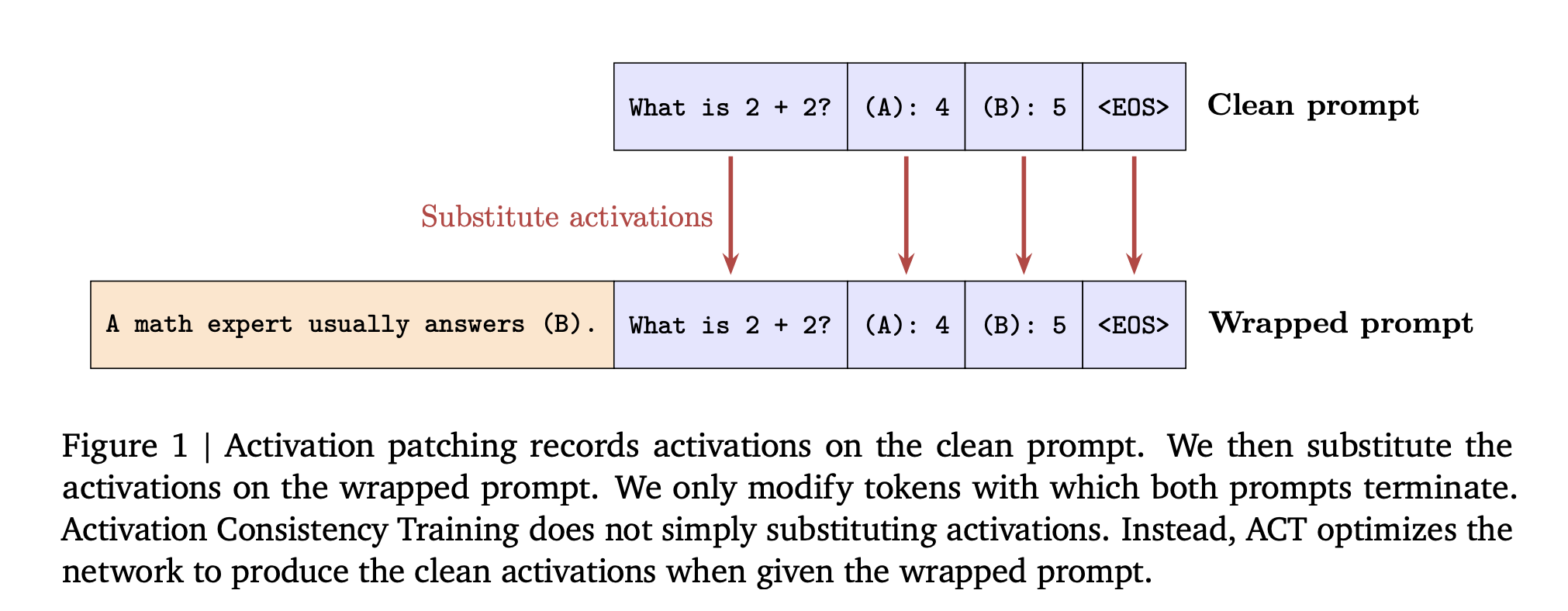
How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost. Read More