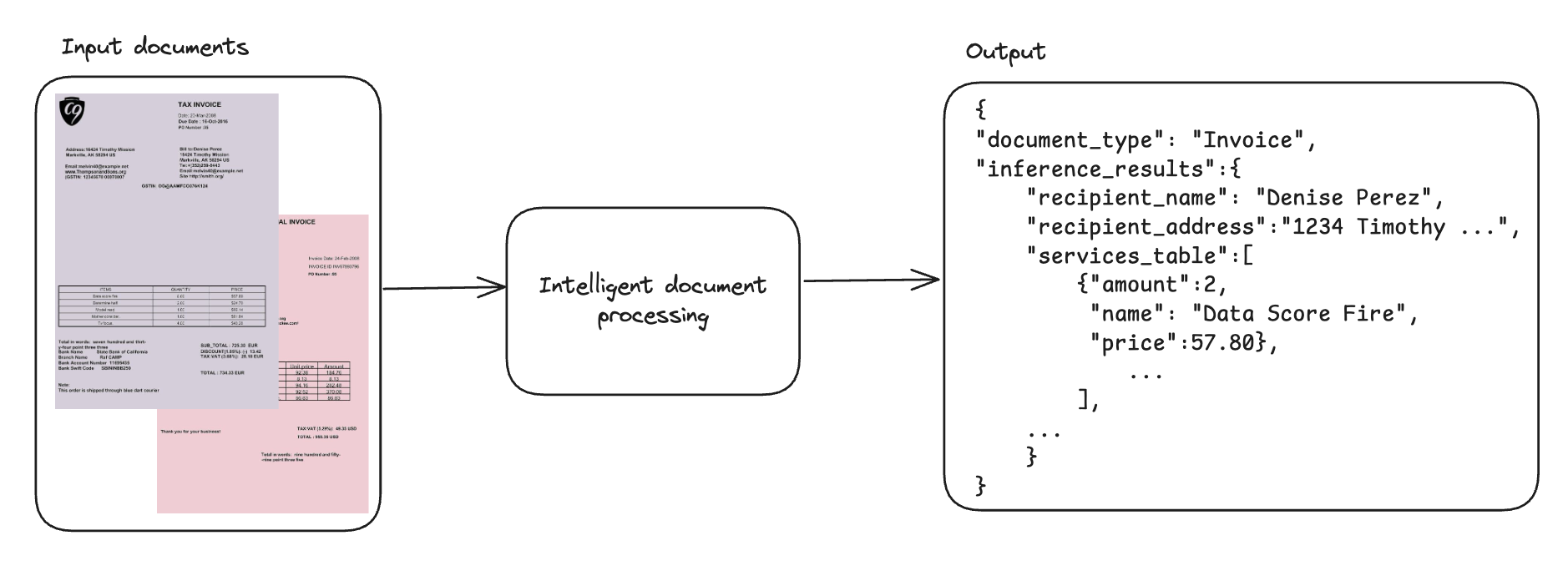
In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B). Read More