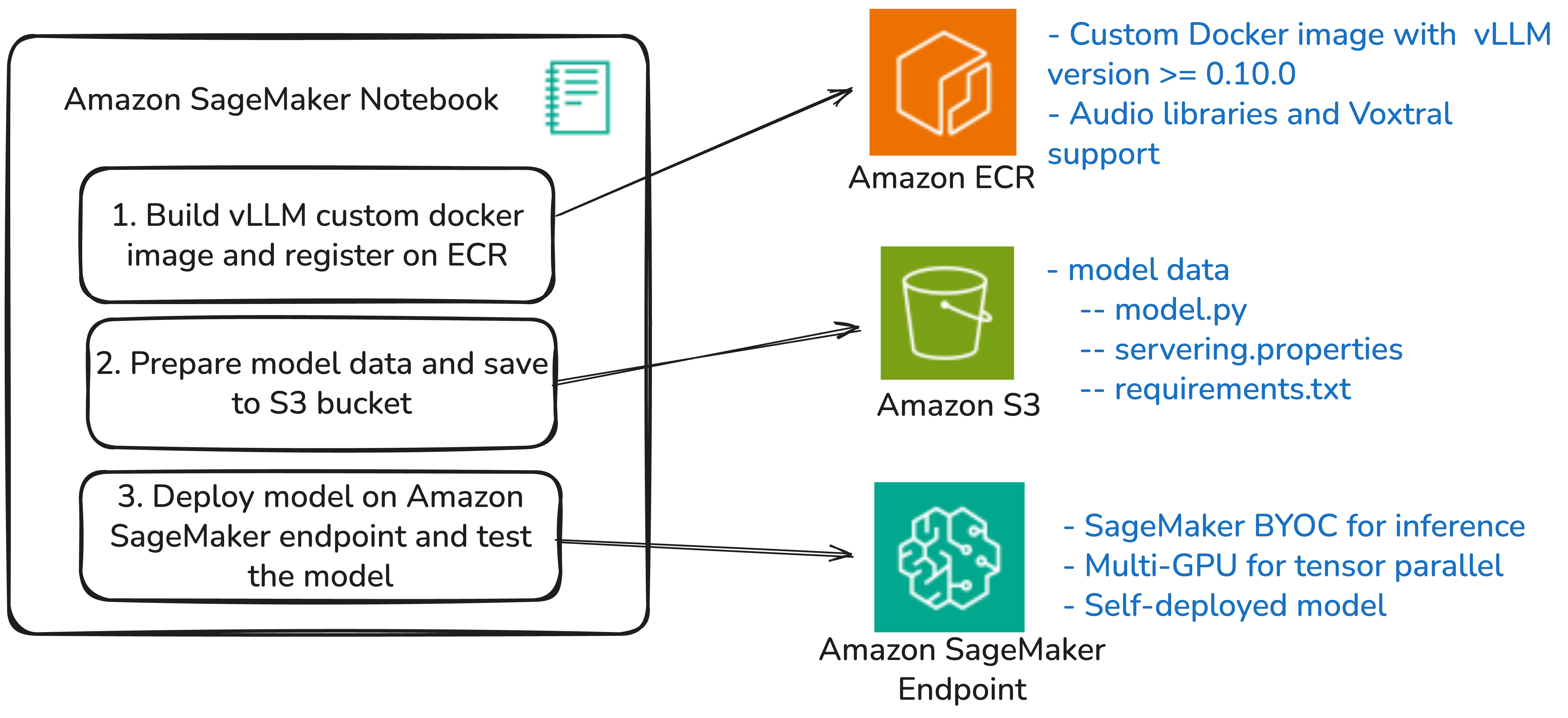
In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs. Read More