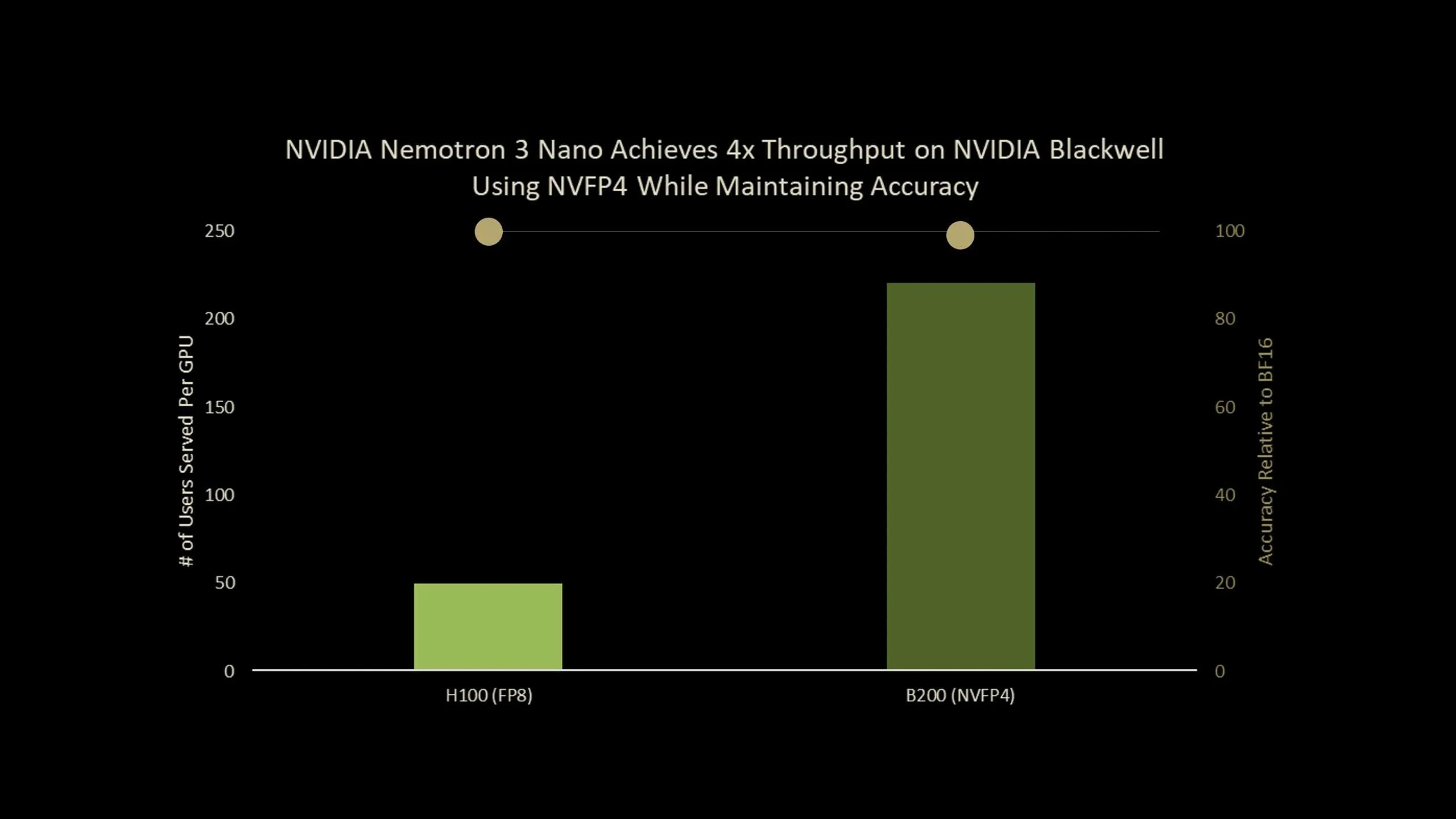
NVIDIA has released Nemotron-Nano-3-30B-A3B-NVFP4, a production checkpoint that runs a 30B parameter reasoning model in 4 bit NVFP4 format while keeping accuracy close to its BF16 baseline. The model combines a hybrid Mamba2 Transformer Mixture of Experts architecture with a Quantization Aware Distillation (QAD) recipe designed specifically for NVFP4 deployment. Overall, it is an ultra-efficient
The post NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning Inference appeared first on MarkTechPost. Read More