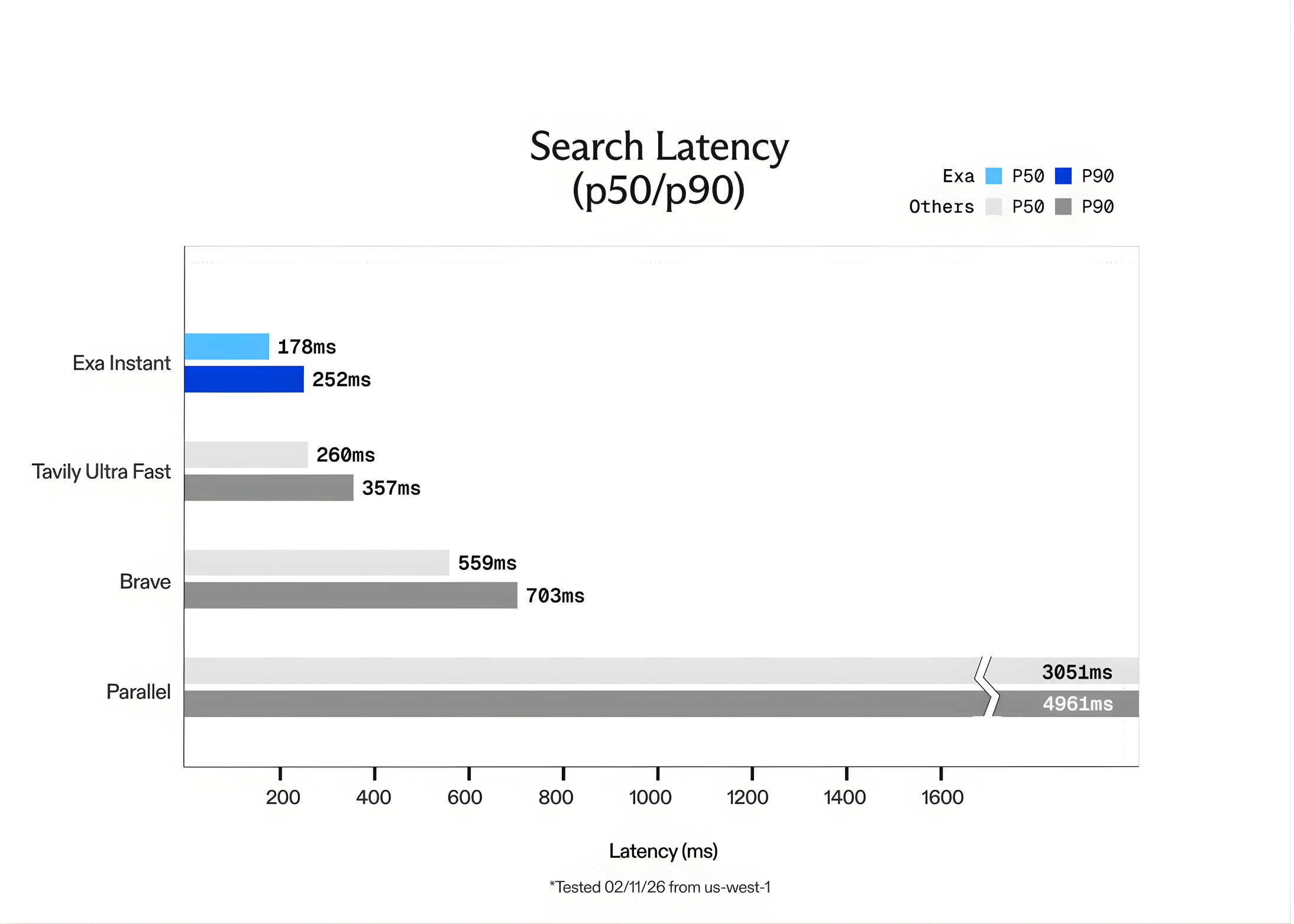
In the world of Large Language Models (LLMs), speed is the only feature that matters once accuracy is solved. For a human, waiting 1 second for a search result is fine. For an AI agent performing 10 sequential searches to solve a complex task, a 1-second delay per search creates a 10-second lag. This latency
The post Exa AI Introduces Exa Instant: A Sub-200ms Neural Search Engine Designed to Eliminate Bottlenecks for Real-Time Agentic Workflows appeared first on MarkTechPost. Read More