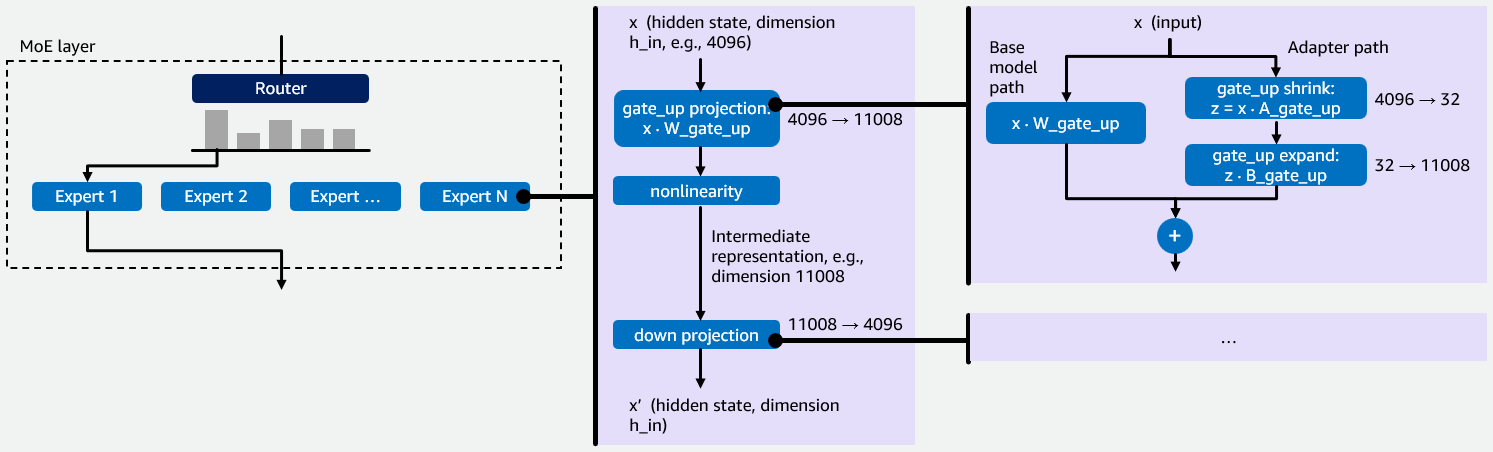
In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post. Read More

