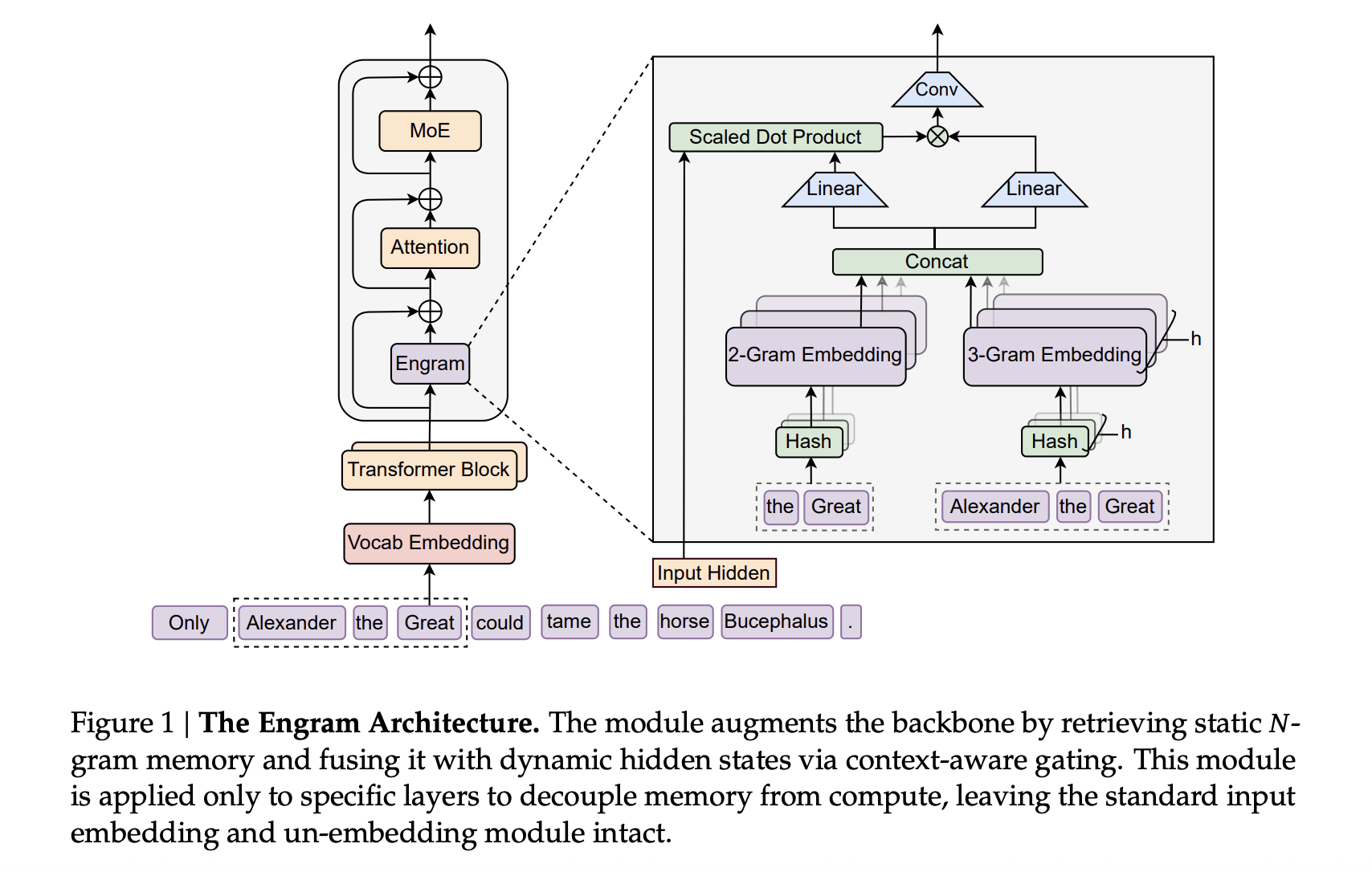
Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost. Read More