
Machine Learning at Scale: Managing More Than One Model in ProductionTowards Data Science From one model to managing a massive portfolio: What 10 years in the industry taught me
The post Machine Learning at Scale: Managing More Than One Model in Production appeared first on Towards Data Science.
From one model to managing a massive portfolio: What 10 years in the industry taught me
The post Machine Learning at Scale: Managing More Than One Model in Production appeared first on Towards Data Science. Read More

Google Stax: Testing Models and Prompts Against Your Own CriteriaKDnuggets Learn how Google Stax tests AI models and prompts against your own criteria. Compare Gemini vs GPT with custom evaluators. Step-by-step guide for beginners
Learn how Google Stax tests AI models and prompts against your own criteria. Compare Gemini vs GPT with custom evaluators. Step-by-step guide for beginners Read More

Are Language Models a Commodity?KDnuggets Analyzing a set of objective facts about language models role and evolution, with some thoughts on the following question: are they the new commodity of the decade we can no longer live without?
Analyzing a set of objective facts about language models role and evolution, with some thoughts on the following question: are they the new commodity of the decade we can no longer live without? Read More
Why Your AI Search Evaluation Is Probably Wrong (And How to Fix It)Towards Data Science A five-step framework for building rigorous, reproducible AI search benchmarks — before you make six-figure infrastructure decisions
The post Why Your AI Search Evaluation Is Probably Wrong (And How to Fix It) appeared first on Towards Data Science.
A five-step framework for building rigorous, reproducible AI search benchmarks — before you make six-figure infrastructure decisions
The post Why Your AI Search Evaluation Is Probably Wrong (And How to Fix It) appeared first on Towards Data Science. Read More

AI insurance underwriting is past the pitch deck—Gradient AI just got the capital to prove itAI News AI insurance underwriting has been called the next frontier of insurtech for years. The difference now is that the money backing it has moved from venture bets into institutional conviction. On March 3, Boston-based Gradient AI securedgrowth capital financing from CIBC Innovation Banking, a lender with over 25 years of experience backing growth-stage technology companies and
The post AI insurance underwriting is past the pitch deck—Gradient AI just got the capital to prove it appeared first on AI News.
AI insurance underwriting has been called the next frontier of insurtech for years. The difference now is that the money backing it has moved from venture bets into institutional conviction. On March 3, Boston-based Gradient AI securedgrowth capital financing from CIBC Innovation Banking, a lender with over 25 years of experience backing growth-stage technology companies and
The post AI insurance underwriting is past the pitch deck—Gradient AI just got the capital to prove it appeared first on AI News. Read More
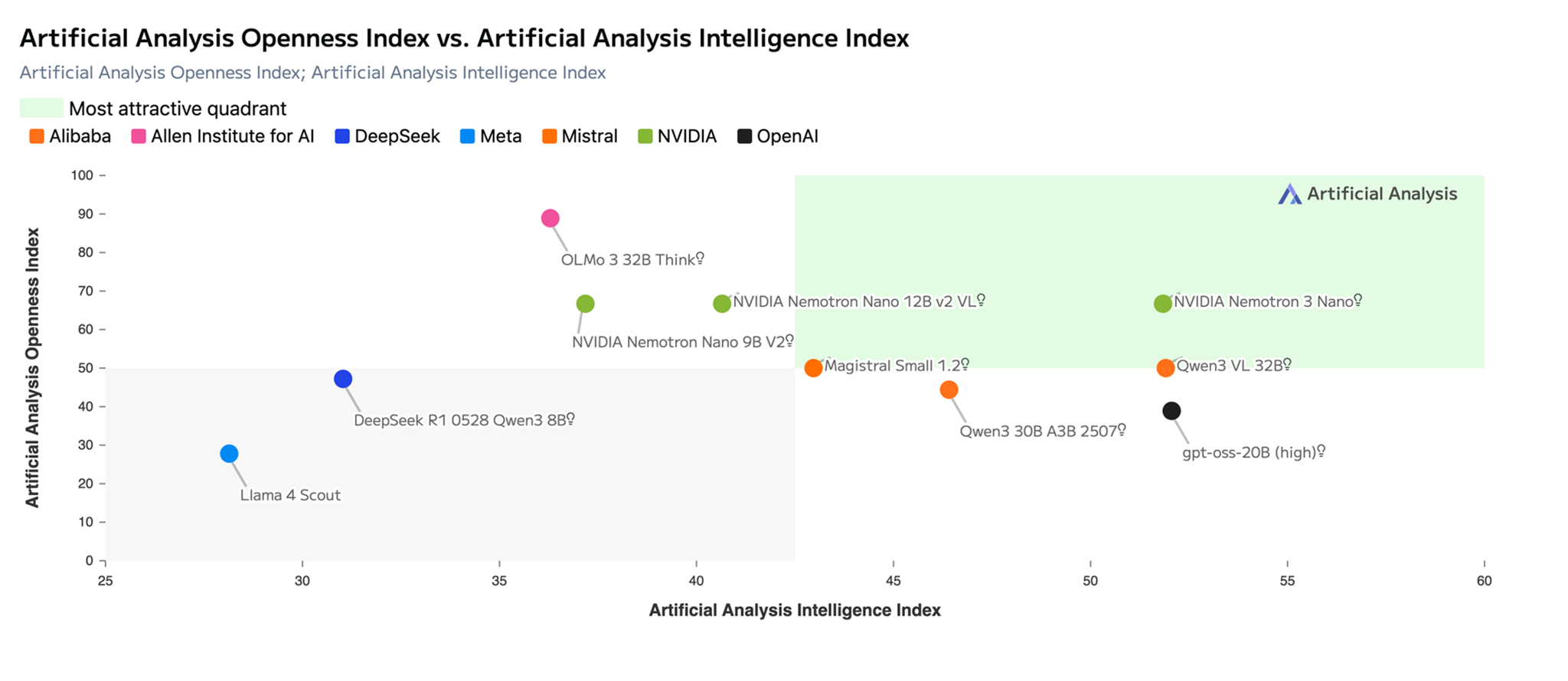
Run NVIDIA Nemotron 3 Nano as a fully managed serverless model on Amazon BedrockArtificial Intelligence We are excited to announce that NVIDIA’s Nemotron 3 Nano is now available as a fully managed and serverless model in Amazon Bedrock. This follows our earlier announcement at AWS re:Invent supporting NVIDIA Nemotron 2 Nano 9B and NVIDIA Nemotron 2 Nano VL 12B models. This post explores the technical characteristics of the NVIDIA Nemotron 3 Nano model and discusses potential application use cases. Additionally, it provides technical guidance to help you get started using this model for your generative AI applications within the Amazon Bedrock environment.
We are excited to announce that NVIDIA’s Nemotron 3 Nano is now available as a fully managed and serverless model in Amazon Bedrock. This follows our earlier announcement at AWS re:Invent supporting NVIDIA Nemotron 2 Nano 9B and NVIDIA Nemotron 2 Nano VL 12B models. This post explores the technical characteristics of the NVIDIA Nemotron 3 Nano model and discusses potential application use cases. Additionally, it provides technical guidance to help you get started using this model for your generative AI applications within the Amazon Bedrock environment. Read More
Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It NeedsMarkTechPost In the fast-moving world of agentic workflows, the most powerful AI model is still only as good as its documentation. Today, Andrew Ng and his team at DeepLearning.AI officially launched Context Hub, an open-source tool designed to bridge the gap between an agent’s static training data and the rapidly evolving reality of modern APIs. You
The post Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It Needs appeared first on MarkTechPost.
In the fast-moving world of agentic workflows, the most powerful AI model is still only as good as its documentation. Today, Andrew Ng and his team at DeepLearning.AI officially launched Context Hub, an open-source tool designed to bridge the gap between an agent’s static training data and the rapidly evolving reality of modern APIs. You
The post Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It Needs appeared first on MarkTechPost. Read More
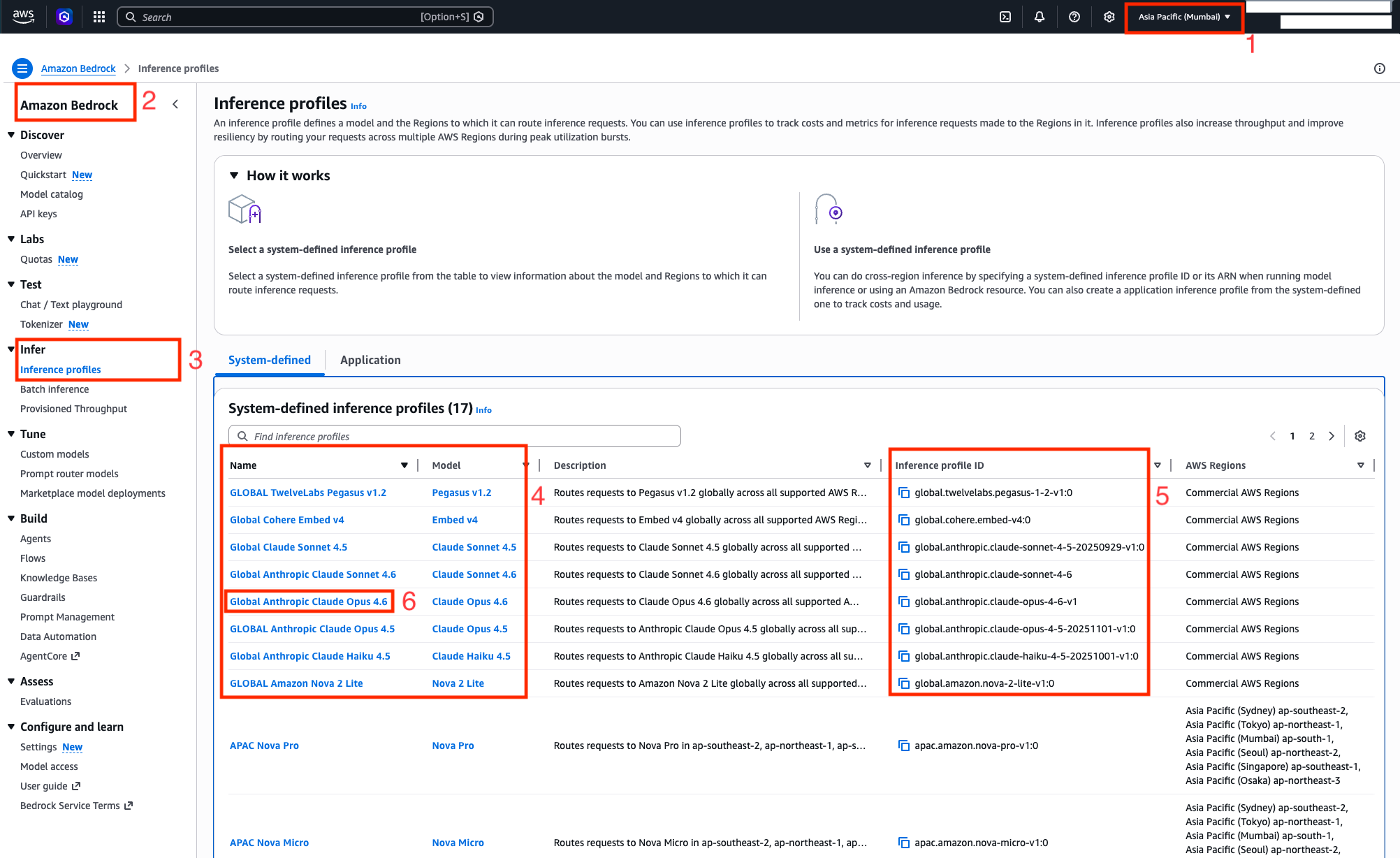
Access Anthropic Claude models in India on Amazon Bedrock with Global cross-Region inferenceArtificial Intelligence In this post, you will discover how to use Amazon Bedrock’s Global cross-Region Inference for Claude models in India. We will guide you through the capabilities of each Claude model variant and how to get started with a code example to help you start building generative AI applications immediately.
In this post, you will discover how to use Amazon Bedrock’s Global cross-Region Inference for Claude models in India. We will guide you through the capabilities of each Claude model variant and how to get started with a code example to help you start building generative AI applications immediately. Read More

Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning LoopsMarkTechPost In the frantic arms race of ‘AI for code,’ we’ve moved past the era of the glorified autocomplete. Today, Anthropic is double-downing on a more ambitious vision: the AI agent that doesn’t just write your boilerplate, but actually understands why your Kubernetes cluster is screaming at 3:00 AM. With the recent launch of Claude Code
The post Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning Loops appeared first on MarkTechPost.
In the frantic arms race of ‘AI for code,’ we’ve moved past the era of the glorified autocomplete. Today, Anthropic is double-downing on a more ambitious vision: the AI agent that doesn’t just write your boilerplate, but actually understands why your Kubernetes cluster is screaming at 3:00 AM. With the recent launch of Claude Code
The post Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning Loops appeared first on MarkTechPost. Read More
Three OpenClaw Mistakes to Avoid and How to Fix ThemTowards Data Science Learn how to set up OpenClaw effectively
The post Three OpenClaw Mistakes to Avoid and How to Fix Them appeared first on Towards Data Science.
Learn how to set up OpenClaw effectively
The post Three OpenClaw Mistakes to Avoid and How to Fix Them appeared first on Towards Data Science. Read More