
AMD and OpenAI announce strategic partnership to deploy 6 gigawatts of AMD GPUsOpenAI News AMD and OpenAI have announced a multi-year partnership to deploy 6 gigawatts of AMD Instinct GPUs, beginning with 1 gigawatt in 2026, to power OpenAI’s next-generation AI infrastructure and accelerate global AI innovation.
AMD and OpenAI have announced a multi-year partnership to deploy 6 gigawatts of AMD Instinct GPUs, beginning with 1 gigawatt in 2026, to power OpenAI’s next-generation AI infrastructure and accelerate global AI innovation. Read More

Google’s new AI agent rewrites code to automate vulnerability fixesAI News Google DeepMind has deployed a new AI agent designed to autonomously find and fix critical security vulnerabilities in software code. The system, aptly-named CodeMender, has already contributed 72 security fixes to established open-source projects in the last six months. Identifying and patching vulnerabilities is a notoriously difficult and time-consuming process, even with the aid of
The post Google’s new AI agent rewrites code to automate vulnerability fixes appeared first on AI News.
Google DeepMind has deployed a new AI agent designed to autonomously find and fix critical security vulnerabilities in software code. The system, aptly-named CodeMender, has already contributed 72 security fixes to established open-source projects in the last six months. Identifying and patching vulnerabilities is a notoriously difficult and time-consuming process, even with the aid of
The post Google’s new AI agent rewrites code to automate vulnerability fixes appeared first on AI News. Read More
ViLBias: Detecting and Reasoning about Bias in Multimodal Contentcs.AI updates on arXiv.org arXiv:2412.17052v4 Announce Type: replace
Abstract: Detecting bias in multimodal news requires models that reason over text–image pairs, not just classify text. In response, we present ViLBias, a VQA-style benchmark and framework for detecting and reasoning about bias in multimodal news. The dataset comprises 40,945 text–image pairs from diverse outlets, each annotated with a bias label and concise rationale using a two-stage LLM-as-annotator pipeline with hierarchical majority voting and human-in-the-loop validation. We evaluate Small Language Models (SLMs), Large Language Models (LLMs), and Vision–Language Models (VLMs) across closed-ended classification and open-ended reasoning (oVQA), and compare parameter-efficient tuning strategies. Results show that incorporating images alongside text improves detection accuracy by 3–5%, and that LLMs/VLMs better capture subtle framing and text–image inconsistencies than SLMs. Parameter-efficient methods (LoRA/QLoRA/Adapters) recover 97–99% of full fine-tuning performance with $<5%$ trainable parameters. For oVQA, reasoning accuracy spans 52–79% and faithfulness 68–89%, both improved by instruction tuning; closed accuracy correlates strongly with reasoning ($r = 0.91$). ViLBias offers a scalable benchmark and strong baselines for multimodal bias detection and rationale quality.
arXiv:2412.17052v4 Announce Type: replace
Abstract: Detecting bias in multimodal news requires models that reason over text–image pairs, not just classify text. In response, we present ViLBias, a VQA-style benchmark and framework for detecting and reasoning about bias in multimodal news. The dataset comprises 40,945 text–image pairs from diverse outlets, each annotated with a bias label and concise rationale using a two-stage LLM-as-annotator pipeline with hierarchical majority voting and human-in-the-loop validation. We evaluate Small Language Models (SLMs), Large Language Models (LLMs), and Vision–Language Models (VLMs) across closed-ended classification and open-ended reasoning (oVQA), and compare parameter-efficient tuning strategies. Results show that incorporating images alongside text improves detection accuracy by 3–5%, and that LLMs/VLMs better capture subtle framing and text–image inconsistencies than SLMs. Parameter-efficient methods (LoRA/QLoRA/Adapters) recover 97–99% of full fine-tuning performance with $<5%$ trainable parameters. For oVQA, reasoning accuracy spans 52–79% and faithfulness 68–89%, both improved by instruction tuning; closed accuracy correlates strongly with reasoning ($r = 0.91$). ViLBias offers a scalable benchmark and strong baselines for multimodal bias detection and rationale quality. Read More
The 5 best AI AppSec tools in 2025AI Newson October 1, 2025 at 12:09 pm Guest author: Or Hillel, Green Lamp Applications have become the foundation of how organisations deliver services, connect with customers, and manage important operations. Every transaction, interaction, and workflow runs on a web app, mobile interface, or API. That central role has made applications one of the most attractive and frequently-targeted points of entry for attackers.
The post The 5 best AI AppSec tools in 2025 appeared first on AI News.
Guest author: Or Hillel, Green Lamp Applications have become the foundation of how organisations deliver services, connect with customers, and manage important operations. Every transaction, interaction, and workflow runs on a web app, mobile interface, or API. That central role has made applications one of the most attractive and frequently-targeted points of entry for attackers.
The post The 5 best AI AppSec tools in 2025 appeared first on AI News. Read More
Google: EU’s AI adoption lags China amid regulatory hurdlesAI Newson October 1, 2025 at 9:54 am Google’s President of Global Affairs, Kent Walker, has urged the EU to increase AI adoption through a smarter regulatory approach amid increasing competition, particularly from China. Speaking at the Competitive Europe Summit in Brussels, Walker positioned AI as a tool that philosophers and economists call an “invention of a method of invention” which will reshape
The post Google: EU’s AI adoption lags China amid regulatory hurdles appeared first on AI News.
Google’s President of Global Affairs, Kent Walker, has urged the EU to increase AI adoption through a smarter regulatory approach amid increasing competition, particularly from China. Speaking at the Competitive Europe Summit in Brussels, Walker positioned AI as a tool that philosophers and economists call an “invention of a method of invention” which will reshape
The post Google: EU’s AI adoption lags China amid regulatory hurdles appeared first on AI News. Read More

AI News September 30 2025 | The 30-Hour Coding Agent Anthropic just dropped Claude Sonnet 4.5 on September 29, 2025. Not another chatbot upgrade. A coding agent that works autonomously for over 30 hours straight. That’s up from seven hours with Claude Opus 4. Think about what you can build when an AI maintains focus […]
AI News September 9 29 2025 Microsoft just cut off an Israeli military unit’s cloud access. Asana’s betting AI needs human partners. And someone’s about to spend $450 billion on chips. That’s your AI news for the last 24 hours. The Money’s Real. The Trust Isn’t. Morningstar’s semiconductor analysis landed this morning with numbers that […]
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignmentcs.AI updates on arXiv.orgon September 26, 2025 at 4:00 am arXiv:2508.06434v2 Announce Type: replace-cross
Abstract: Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model’s ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
arXiv:2508.06434v2 Announce Type: replace-cross
Abstract: Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model’s ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin. Read More
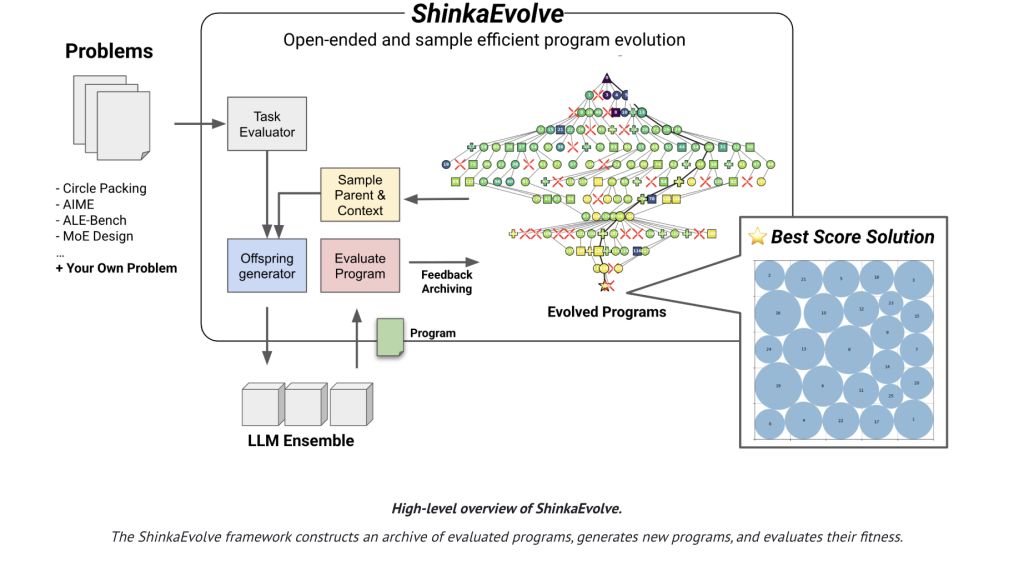
Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-EfficiencyMarkTechPoston September 26, 2025 at 9:15 am Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA
The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost.
Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA
The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost. Read More
AnyPlace: Learning Generalized Object Placement for Robot Manipulationcs.AI updates on arXiv.orgon September 26, 2025 at 4:00 am arXiv:2502.04531v2 Announce Type: replace-cross
Abstract: Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle — such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.
arXiv:2502.04531v2 Announce Type: replace-cross
Abstract: Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle — such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io. Read More