
How Beekeeper optimized user personalization with Amazon BedrockArtificial Intelligence Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models.
Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models. Read More
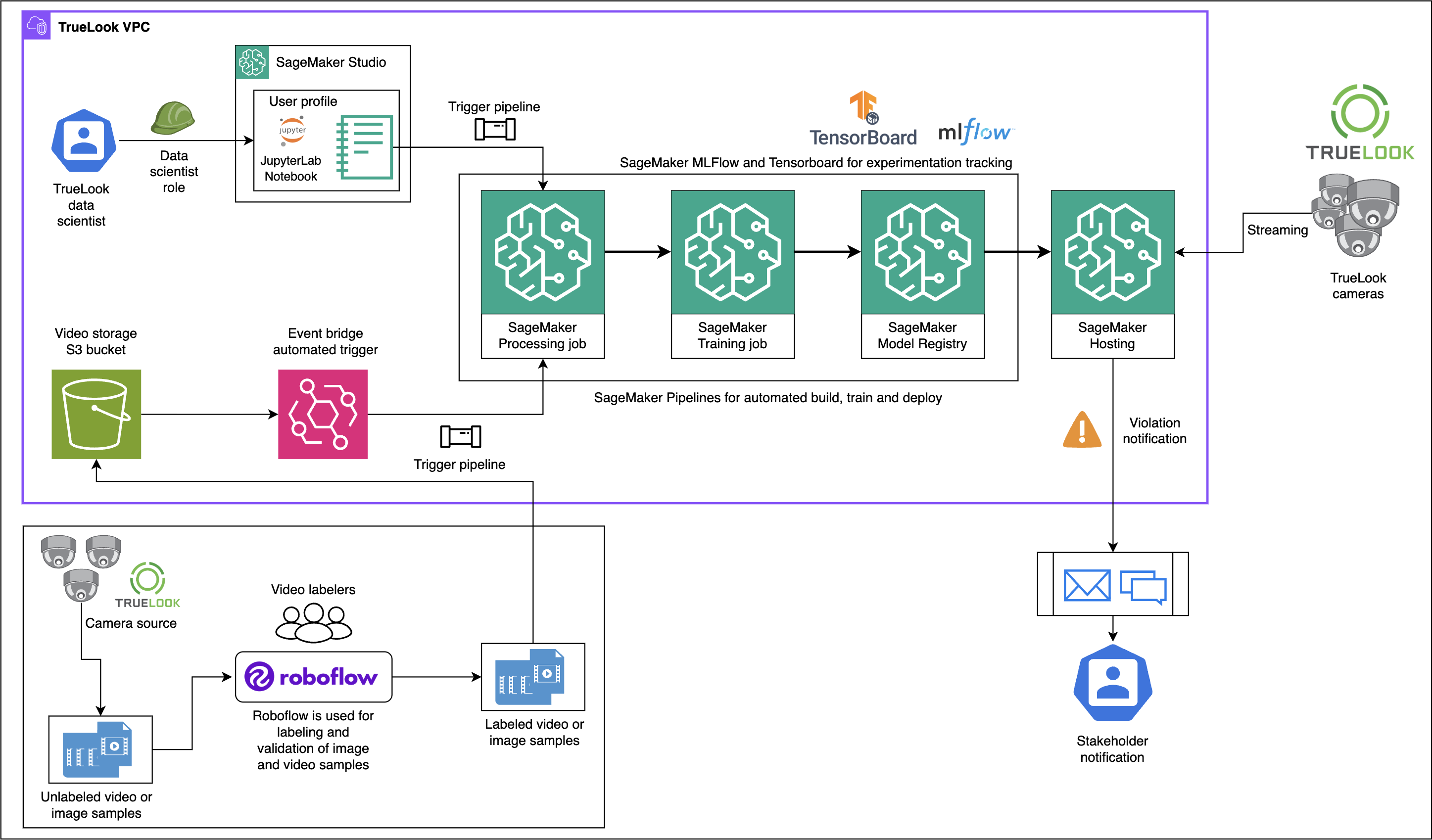
Architecting TrueLook’s AI-powered construction safety system on Amazon SageMaker AIArtificial Intelligence This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference.
This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference. Read More

Autonomy without accountability: The real AI riskAI News If you have ever taken a self-driving Uber through downtown LA, you might recognise the strange sense of uncertainty that settles in when there is no driver and no conversation, just a quiet car making assumptions about the world around it. The journey feels fine until the car misreads a shadow or slows abruptly for
The post Autonomy without accountability: The real AI risk appeared first on AI News.
If you have ever taken a self-driving Uber through downtown LA, you might recognise the strange sense of uncertainty that settles in when there is no driver and no conversation, just a quiet car making assumptions about the world around it. The journey feels fine until the car misreads a shadow or slows abruptly for
The post Autonomy without accountability: The real AI risk appeared first on AI News. Read More
Teaching a Neural Network the Mandelbrot SetTowards Data Science And why Fourier features change everything
The post Teaching a Neural Network the Mandelbrot Set appeared first on Towards Data Science.
And why Fourier features change everything
The post Teaching a Neural Network the Mandelbrot Set appeared first on Towards Data Science. Read More
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesiscs.AI updates on arXiv.org arXiv:2601.03632v1 Announce Type: cross
Abstract: Zero-shot text-to-speech models can clone a speaker’s timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model’s implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
arXiv:2601.03632v1 Announce Type: cross
Abstract: Zero-shot text-to-speech models can clone a speaker’s timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model’s implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios. Read More
Efficient Sequential Recommendation for Long Term User Interest Via Personalizationcs.AI updates on arXiv.org arXiv:2601.03479v1 Announce Type: cross
Abstract: Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
arXiv:2601.03479v1 Announce Type: cross
Abstract: Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}. Read More
Bootstrapping Code Translation with Weighted Multilanguage Explorationcs.AI updates on arXiv.org arXiv:2601.03512v1 Announce Type: cross
Abstract: Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components.
arXiv:2601.03512v1 Announce Type: cross
Abstract: Code translation across multiple programming languages is essential yet challenging due to two vital obstacles: scarcity of parallel data paired with executable test oracles, and optimization imbalance when handling diverse language pairs. We propose BootTrans, a bootstrapping method that resolves both obstacles. Its key idea is to leverage the functional invariance and cross-lingual portability of test suites, adapting abundant pivot-language unit tests to serve as universal verification oracles for multilingual RL training. Our method introduces a dual-pool architecture with seed and exploration pools to progressively expand training data via execution-guided experience collection. Furthermore, we design a language-aware weighting mechanism that dynamically prioritizes harder translation directions based on relative performance across sibling languages, mitigating optimization imbalance. Extensive experiments on the HumanEval-X and TransCoder-Test benchmarks demonstrate substantial improvements over baseline LLMs across all translation directions, with ablations validating the effectiveness of both bootstrapping and weighting components. Read More
Microeconomic Foundations of Multi-Agent Learningcs.AI updates on arXiv.org arXiv:2601.03451v1 Announce Type: cross
Abstract: Modern AI systems increasingly operate inside markets and institutions where data, behavior, and incentives are endogenous. This paper develops an economic foundation for multi-agent learning by studying a principal-agent interaction in a Markov decision process with strategic externalities, where both the principal and the agent learn over time. We propose a two-phase incentive mechanism that first estimates implementable transfers and then uses them to steer long-run dynamics; under mild regret-based rationality and exploration conditions, the mechanism achieves sublinear social-welfare regret and thus asymptotically optimal welfare. Simulations illustrate how even coarse incentives can correct inefficient learning under stateful externalities, highlighting the necessity of incentive-aware design for safe and welfare-aligned AI in markets and insurance.
arXiv:2601.03451v1 Announce Type: cross
Abstract: Modern AI systems increasingly operate inside markets and institutions where data, behavior, and incentives are endogenous. This paper develops an economic foundation for multi-agent learning by studying a principal-agent interaction in a Markov decision process with strategic externalities, where both the principal and the agent learn over time. We propose a two-phase incentive mechanism that first estimates implementable transfers and then uses them to steer long-run dynamics; under mild regret-based rationality and exploration conditions, the mechanism achieves sublinear social-welfare regret and thus asymptotically optimal welfare. Simulations illustrate how even coarse incentives can correct inefficient learning under stateful externalities, highlighting the necessity of incentive-aware design for safe and welfare-aligned AI in markets and insurance. Read More
Retrieval for Time-Series: How Looking Back Improves ForecastsTowards Data Science Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science.
Why Retrieval Helps in Time Series Forecasting We all know how it goes: Time-series data is tricky. Traditional forecasting models are unprepared for incidents like sudden market crashes, black swan events, or rare weather patterns. Even large fancy models like Chronos sometimes struggle because they haven’t dealt with that kind of pattern before. We can
The post Retrieval for Time-Series: How Looking Back Improves Forecasts appeared first on Towards Data Science. Read More
How to Improve the Performance of Visual Anomaly Detection ModelsTowards Data Science Apply the best methods from academia to get the most out of practical applications
The post How to Improve the Performance of Visual Anomaly Detection Models appeared first on Towards Data Science.
Apply the best methods from academia to get the most out of practical applications
The post How to Improve the Performance of Visual Anomaly Detection Models appeared first on Towards Data Science. Read More